InternRobotics is open-source!
🚀 A Sim-Data-Train/Eval inclusive engine for Embodied AI:
⚙️ 1-line sim deploy
📦 Massive hybrid datasets
🧠 One-click training & eval across 50+ models
🔗 Click to explore: https://t.co/iTV3e12r8U
🧐 Simulation has long promised robot pretraining, but breaks at the moment of real-world deployment.
🚀 Today, we introduce SIM1: the first real-to-sim-to-real paradigm where the generative world becomes the same one as reality.
SIM1 produces simulation data whose execution is directly valid in the physical world, enabling policies trained entirely in simulation to transfer zero-shot, at scale.
📈 This unlocks a new scaling law for robotics: we scale intelligence without scaling real-world data.
✨ Few demonstrations in, real-world policies out.
Simulation is no longer a proxy; it is supervision itself.
https://t.co/Kp1YBe5Gmf
https://t.co/GG2SBQfPpG
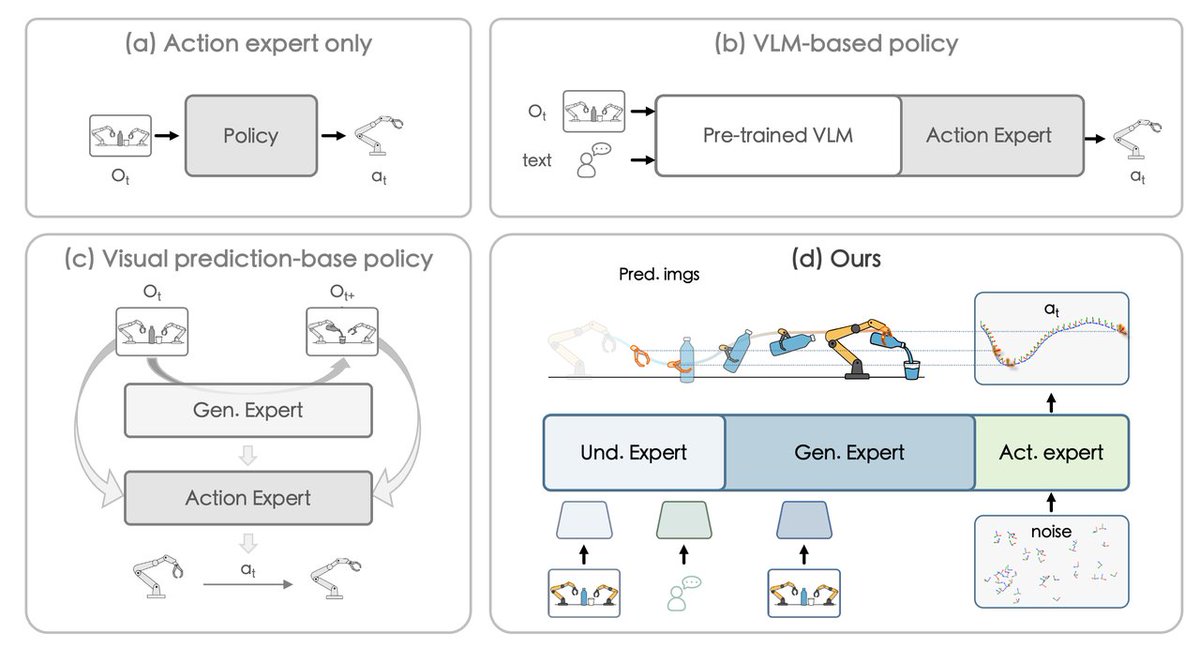
🤖 Introducing InternVLA-A1 — now fully open-sourced!
Many VLA models follow instructions well in static scenes… but struggle in dynamic environments (conveyor belts, rotating platforms, multi-robot setups). Why? They see the present—but can’t imagine the future.
InternVLA-A1 solution: unify perception, imagination, and action in one model:
✅ Scene understanding: Image + text → task parsing
✅ Task imagination: Predict future frames → reason about dynamics
✅ Guided control: Execute actions steered by visual foresight
Powered by InternData-A1 - Large-scale high-quality simulated dataset, InternVLA-A1 stays robust under complex backgrounds, lighting, and distractions.
🔥 See it in action:
1️⃣ High-speed conveyor: track, predict, and stably grasp or flip packages
2️⃣ Rotating platform: task-aware recognition & precise pick-up of diverse items
📊 Outperforms π0 and Gr00t N1.5 on general manipulation benchmarks!
✨ Model, data, and code are all open!
Models: https://t.co/5PYmtZNUoO
Datasets: https://t.co/Ipi9XF6sw7
GitHub: https://t.co/AddhXUyugu
Meet InternVLA-A1 🤖✨
It unifies scene understanding, visual foresight, and action execution into a single framework.
🧠 The Core: Synergizes MLLM's semantic understanding with world-model-style dynamic prediction, to "imagine" the future and guide adaptive actions.
🚀 The Fuel: Empowered by high-fidelity synthetic data (InternData-A1). The result? A VLA model that tackles high-dynamic scenarios with effortless mastery.
🤖Can robots achieve accurate navigation without any external localization feedback?
📸We present #LoGoPlanner, which handles perception, localization, and planning in one go!
Check our results on LeKiWi, G1, and Go2 robots.
🌐Project: https://t.co/mWIMzIfuqT
🚀 Introducing G^2VLM: Geometry Grounded Vision Language Model with Unified 3D Reconstruction and Spatial Reasoning
G^2VLM can natively predicts 3D attributes (depth, camera pose, pointmaps) and uses them for spatial understanding via interleaved reasoning.
🔧 End-to-End Unified Model
✅ Monocular & Video Depth Estimation
✅ Pose Estimation
✅ 3D Point Reconstruction
✅ Spatial Understanding and Reasoning
🏆 This design helps G^2VLM achieve robust performance in both 3D Reconstruction and Spatial Reasoning!
#VLM #spatial #3D #LLM
💻 Code at: https://t.co/WxvTgeG9Jw
👇[1/n]
Great release! Gallant demonstrates a clean voxel-grid pipeline for perceptive humanoid locomotion — unified policy, strong generalization across stairs, gaps, stepping stones, and cluttered spaces.
Introducing Gallant: Voxel Grid-based Humanoid Locomotion and Local-navigation across 3D Constrained Terrains 🤖
Project page: https://t.co/9hua2TXfKj
Arxiv: https://t.co/BadszLcPut
Gallant is, to our knowledge, the first system to run a single policy that handles full-space constraints — including ground-level barriers, lateral clutter, and overhead obstacles on a humanoid robot.
Instead of elevation maps or depth cameras, Gallant uses a voxel grid built directly from raw LiDAR as its perception representation, giving it inherent 3D coverage of the scene. With our custom LiDAR simulation toolkit (https://t.co/TsezpNF6cu), we model realistic scans, including returns from the robot’s own moving links, which is crucial for sim-to-real transfer.
On the control side, we use a target-based training scheme rather than standard velocity tracking. The robot is given a goal and learns to discover its own in-path velocities and trajectories, so no external high-frequency command stream is needed during deployment.
The policy itself is intentionally lightweight: just a 3-layer CNN + 3-layer MLP (~0.3M params), running onboard on the Unitree G1’s Orin NX at 50 Hz with no extra compute.
Training takes about 6 hours on 8× NVIDIA RTX 4090 GPUs. The resulting policy transfers directly to the real robot and achieves >90% success rate on most tested terrain types.
Gallant is our “half-way” step toward robust perceptive locomotion — a problem we believe remains fundamental for humanoid robots. We’re now working toward closing the gap to near-100% reliability and expanding the pipeline further.
Code will be fully released soon.
Discussion, feedback, and collaboration are very welcome! 🙌
Introducing Gallant: Voxel Grid-based Humanoid Locomotion and Local-navigation across 3D Constrained Terrains 🤖
Project page: https://t.co/9hua2TXfKj
Arxiv: https://t.co/BadszLcPut
Gallant is, to our knowledge, the first system to run a single policy that handles full-space constraints — including ground-level barriers, lateral clutter, and overhead obstacles on a humanoid robot.
Instead of elevation maps or depth cameras, Gallant uses a voxel grid built directly from raw LiDAR as its perception representation, giving it inherent 3D coverage of the scene. With our custom LiDAR simulation toolkit (https://t.co/TsezpNF6cu), we model realistic scans, including returns from the robot’s own moving links, which is crucial for sim-to-real transfer.
On the control side, we use a target-based training scheme rather than standard velocity tracking. The robot is given a goal and learns to discover its own in-path velocities and trajectories, so no external high-frequency command stream is needed during deployment.
The policy itself is intentionally lightweight: just a 3-layer CNN + 3-layer MLP (~0.3M params), running onboard on the Unitree G1’s Orin NX at 50 Hz with no extra compute.
Training takes about 6 hours on 8× NVIDIA RTX 4090 GPUs. The resulting policy transfers directly to the real robot and achieves >90% success rate on most tested terrain types.
Gallant is our “half-way” step toward robust perceptive locomotion — a problem we believe remains fundamental for humanoid robots. We’re now working toward closing the gap to near-100% reliability and expanding the pipeline further.
Code will be fully released soon.
Discussion, feedback, and collaboration are very welcome! 🙌
🎉IROS 2025 Workshop & Challenge Highlights
On Oct 20, the Workshop on Multimodal Robot Learning in Physical Worlds, hosted by Shanghai AI Lab, successfully concluded at #IROS2025.
💡 The event gathered experts from UC Berkeley, MIT, Stanford, Tsinghua, Zhejiang University, and ShanghaiTech to explore interactive and generalizable multimodal robot learning bridging simulation and the real world.
📺 Full talk replays are now live on the official website — check them out!
🔗https://t.co/tnBtuXLMd7
#embodiedai #AIResearch
🤖 Go from a task like "set the table" to a complete 3D tabletop scene, ready for robot simulation.
Meet MesaTask 🚀 [NeurIPS 2025 Spotlight]
✨ 10K+ physics-verified tabletop scenes
✨ 12K+ curated 3D assets
✨ Outperforms baselines in alignment, realism & physicality
All data & code are OPEN — try it now ⚡
🔗 Dataset: https://t.co/hdRVJC3GMw
🌐 Project: https://t.co/FFUtyFokUh
💻 Code: https://t.co/sDzvjQHPFc
📄 Paper:https://t.co/wOtsh0oZco
#NeurIPS2025 #AI #Robotics #EmbodiedAI #Dataset #OpenSource
🚨 Important Notice 🚨
Challenge update:
📅 Test server closing extended → Oct 7
⏰ Final sprint — registered teams, make sure to submit on time! Don’t miss your chance!🔥
🔥 Join our Challenge on Multimodal Robot Learning in InternUtopia and Real World!
🎮 Tasks: Manipulation & Navigation
🗺️ Each track includes an online qualifier and on-site finals
🧰 Starter kits open now
🥇 Winner prize: $10K
🔗 https://t.co/xEIqoH2Z1w
#IROS2025#Robotics
🤖 Behavior Foundation Model (BFM) for Humanoid Robots #robotics#embodiedai
We are excited to re-introduce our Behavior Foundation Model for Humanoid Robots, built upon a unified perspective of diverse WBC tasks —— a promising step toward a foundation model for general humanoid control.
🌐 Website: https://t.co/upnU6FwX7z
📄 Paper: https://t.co/UHSD4y9T13
We are trending fast on @huggingface ! 🔥🔥🔥
Thanks for all the love on our models, datasets, and papers 🥰
Fuel us with more LIKES & STARS so we can push even harder 🚀https://t.co/gayHWuvXu0
Shanghai AI Laboratory has launched InternVLA·A1, the first integrated “embodied manipulation model” capable of understanding, imagining, and executing ❗️
Real-world evaluations show it significantly outperforms π0 and GR00T N1.5, demonstrating strong adaptability in highly dynamic scenarios 🌟.
The model has been adapted for multiple robotic platforms, including Ark Infinity, Guodi Qinglong Humanoid Robot, Zhiyuan Genie, 松灵, and Franka🦾, enabling users to quickly adapt to new environments and tasks.
With the open-source release of InternVLA·A1, AI Lab has shared the complete technical framework for embodied intelligence's "thinking-acting-self-learning" closed loop:
InternVLA·M1 serves as the "brain," responsible for spatial reasoning and task planning;
InternVLA·A1 acts as the "cerebellum," enabling agile and precise motion execution;
The general reward model VLAC enhances reinforcement learning efficiency in real-world applications.
At 7:30 PM on September 19 (this Friday), Shanghai AI Laboratory will collaborate with multiple industry experts to host the second live session of Open Source Week, providing an in-depth analysis of the related technologies. Welcome to reserve your spot and join the broadcast.