Choice of downsampling methods in Elasticsearch, GA in 9.4.
- Last-value: one observation per bucket, max storage savings
- Aggregate: min/max/sum/count + counter resets
Both fully queryable in ES|QL. Dashboards run unchanged on downsampled data.
https://t.co/B5CYPzI5cI
ES|QL now has schema-on-read.
SET unmapped_fields="load" makes every field in _source outside the mapping queryable — no reindex, works retroactively.
"Slower and accessible right now" beats "fast and doesn't exist".
https://t.co/xhRQVTCt1j
Native OTel exponential histograms in Elasticsearch — GA in 9.4, queryable in ES|QL.
Buckets adapt to the data, any percentile at query time with a guaranteed upper bound on relative error. A ::exponential_histogram cast handles older histogram data.
https://t.co/q8OAxATaV1
On the ingestion side — under the hood of the Prometheus Remote Write endpoint inside Elasticsearch: protobuf parsing, TSDS mapping, metric type inference.
Point Prometheus or Grafana Alloy straight at Elasticsearch, no adapter in between.
https://t.co/tx46fgrCAL
Elasticsearch is now a fully columnar metrics datastore. A year of work on TSDB:
• 6.6x denser storage — 3.75 bytes per OTel data point
• 50% more ingest
• Up to 160x faster queries
Competitive with Prometheus, Mimir & ClickHouse end-to-end.
https://t.co/kleSqOw6ev
And one more on the metrics story: native PromQL, inside Elasticsearch.
The new PROMQL command in ES|QL queries time series with PromQL — whether it came from Prometheus remote write, OTel, or elsewhere.
Tech Preview in Elasticsearch 9.4 and Serverless.
https://t.co/qOV6SQvaJ3
Database team on fire! Who said you gotta choose between either fast point queries (indexes) or fast aggregations (vectorized columnar scans)?
@TimescaleDB now gives you both. 2.18 will ship with a new table access method for our hypercore storage engine.
🔥🔥🔥
Most developers are often faced with the age old question: row-oriented or column-oriented database?
But @TimescaleDB developers are not most developers.
Instead, we asked: Why not both?
Say hello to 𝗛𝘆𝗽𝗲𝗿𝘀𝘁𝗼𝗿𝗲: the hybrid row/columnar engine for real-time analytics we've been working on for five years.
https://t.co/vkWnqhRdKx
(This is just Day 1 of Timescale Launch week. Even more goodies coming soon!)
One of the core rules in data management: Less (data accessed) is more (performance)
Chunk-skipping indexes in @TimescaleDB 2.16:
- Skip irrelevant partitions
- Even when filtering by non partitioning columns
🚀Boost Postgres Performance by 7x
https://t.co/RXhTJNIzin
@samokhvalov@TimescaleDB My main worry on moving with this would be that the rfc is not finalized and whether the final support for UUIDv7 in PG17 (?) will follow the format from https://t.co/oaEpAzyVYZ
@samokhvalov@TimescaleDB Great one Nikolay! The big question now becomes whether we should add support for UUIDv7 in Timescale and do the generation and conversion behind the scenes.
We love solving hard database problems. Building Vectorized Query Execution is definitely one!
Read about this new capability built for our columnar storage, available in the latest version of TimescaleDB.
#GoFast 🔥
https://t.co/504HKu6MBm
The first take on a video for Tiered Storage was outside - Keeping the rule of shooting in one take even if we once more went out of script & missed the target :-)
https://t.co/wvSSwmYT6D
I tried to record a funny (??) video about the new Tiered Storage by @TimescaleDB, got too excited by the price and forgot what I wanted to say - so why not share it publicly either way?
For more check our announcement: https://t.co/5UVE0SdPch
https://t.co/VFrCs1ewi9
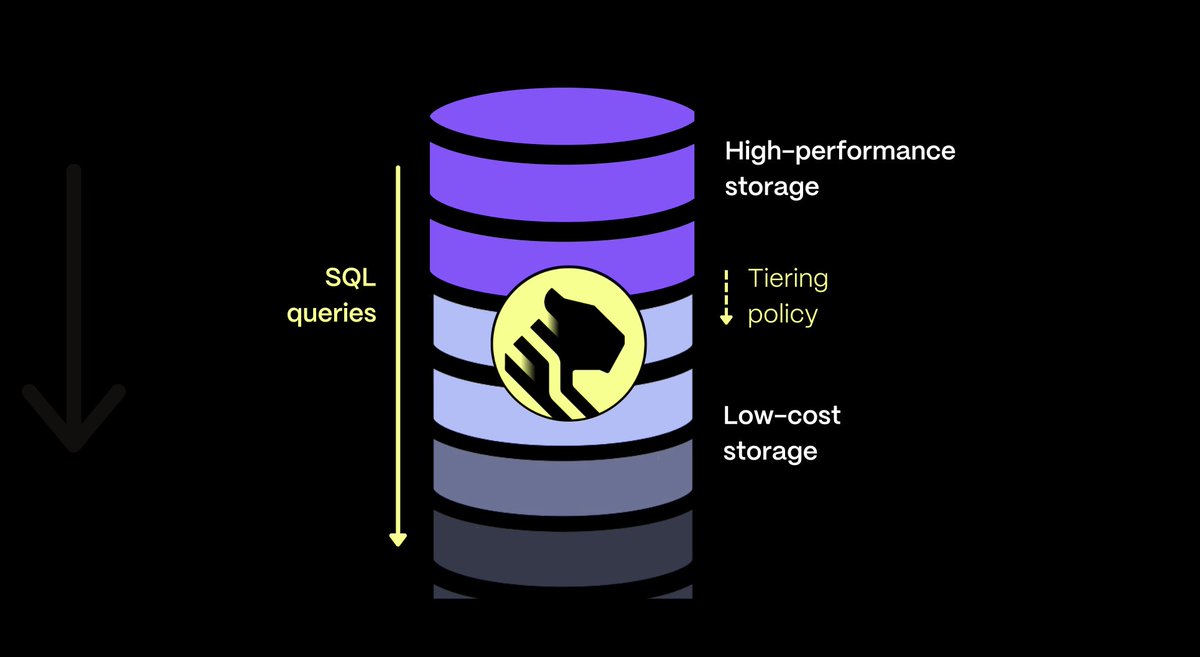
Super excited with the general availability of Tiered Storage and the new low-cost storage tier
💚flat price of $0.021 per GB/month
💚no extra charge per query or data read
💚no hidden fees
💚seamless tiering
💚unified querying
Straightforward, cost-effective data management 💝
It's "Scaling Postgres" Launch Week.
Announcing Tiered Storage on Timescale💥
Store your older data in a low-cost, bottomless storage tier while still being able to query it via normal SQL from within #PostgreSQL. Now in general availability.
https://t.co/p9ltpUaguJ
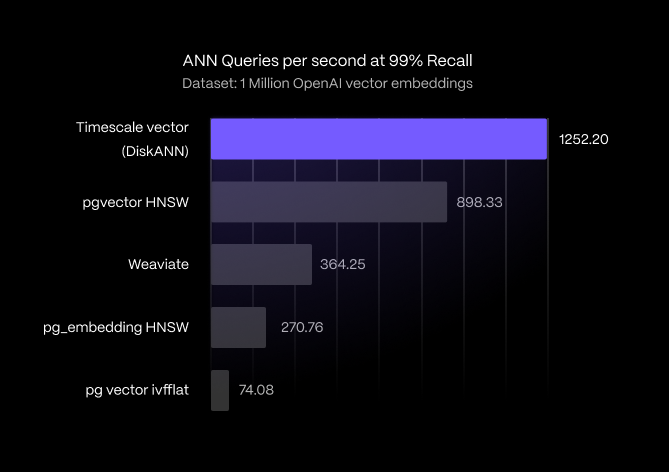
1/ 🤖 You don’t need a specialized vector database. You just need PostgreSQL.
Introducing Timescale Vector: PostgreSQL++ for AI Applications
- 📈 3x ANN search performance vs Weaviate, 40%-1,500% boost for pgvector.
- ⚙️ No need to learn and manage a separate vector database.
Whatttt?!?! We won an award!!! We are honored to be included as one of the most groundbreaking products available to developers and IT organizations https://t.co/cEYj7fQdgM #kinginthecastle#dataops#opensourcesoftware
If you love solving interesting database problems, the Database Group at GitLab continues to hire for Backend Engineers with strong experience in Ruby on Rails and PostgreSQL. Every day is definitely interesting :-)
https://t.co/UtYKbNzQJg
A deep dive on the issues PostgreSQL subtransactions can cause in the presence of replicas and a step-by-step look at what we did to eliminate them at GitLab https://t.co/nwS0nJWwQh