HunyuanVideo GP v4 is out, check it out !: fast mode to generate 4s of a 1280x720 video with multiple loras in only 4 minutes on a RTX4090, on the fly change of models, attention modes without restarting the app, ..
https://t.co/TXeapIgweG
NEW: Open Source Text/ Image to video model is out - MIT licensed - Rivals Gen-3, Pika & Kling 🔥
> Pyramid Flow: Training-efficient Autoregressive Video Generation method
> Utilizes Flow Matching
> Trains on open-source datasets
> Generates high-quality 10-second videos
> Video resolution: 768p
> Frame rate: 24 FPS
> Supports image-to-video generation
> Model checkpoints available on the hub 🤗
Editing facial expressions in real time now on @huggingface Spaces 👨🎤🔀
A Grog converted Cog image to Gradio running a ComfyUI backend - magic of open source 🤝
▶️ https://t.co/dxICPo9sYO
InstantDrag
Improving Interactivity in Drag-based Image Editing
discuss: https://t.co/dTHqxUTdSg
Drag-based image editing has recently gained popularity for its interactivity and precision. However, despite the ability of text-to-image models to generate samples within a second, drag editing still lags behind due to the challenge of accurately reflecting user interaction while maintaining image content. Some existing approaches rely on computationally intensive per-image optimization or intricate guidance-based methods, requiring additional inputs such as masks for movable regions and text prompts, thereby compromising the interactivity of the editing process. We introduce InstantDrag, an optimization-free pipeline that enhances interactivity and speed, requiring only an image and a drag instruction as input. InstantDrag consists of two carefully designed networks: a drag-conditioned optical flow generator (FlowGen) and an optical flow-conditioned diffusion model (FlowDiffusion). InstantDrag learns motion dynamics for drag-based image editing in real-world video datasets by decomposing the task into motion generation and motion-conditioned image generation. We demonstrate InstantDrag's capability to perform fast, photo-realistic edits without masks or text prompts through experiments on facial video datasets and general scenes. These results highlight the efficiency of our approach in handling drag-based image editing, making it a promising solution for interactive, real-time applications.
Did a lot of testing on my LoRA training script for @bfl_ml FLUX.1 dev model. Amazing model! I think it is finally ready. Running smooth on a single 4090. Posting a guide tomorrow. Special thanks to @araminta_k for helping me test on her amazing original character and artwork.
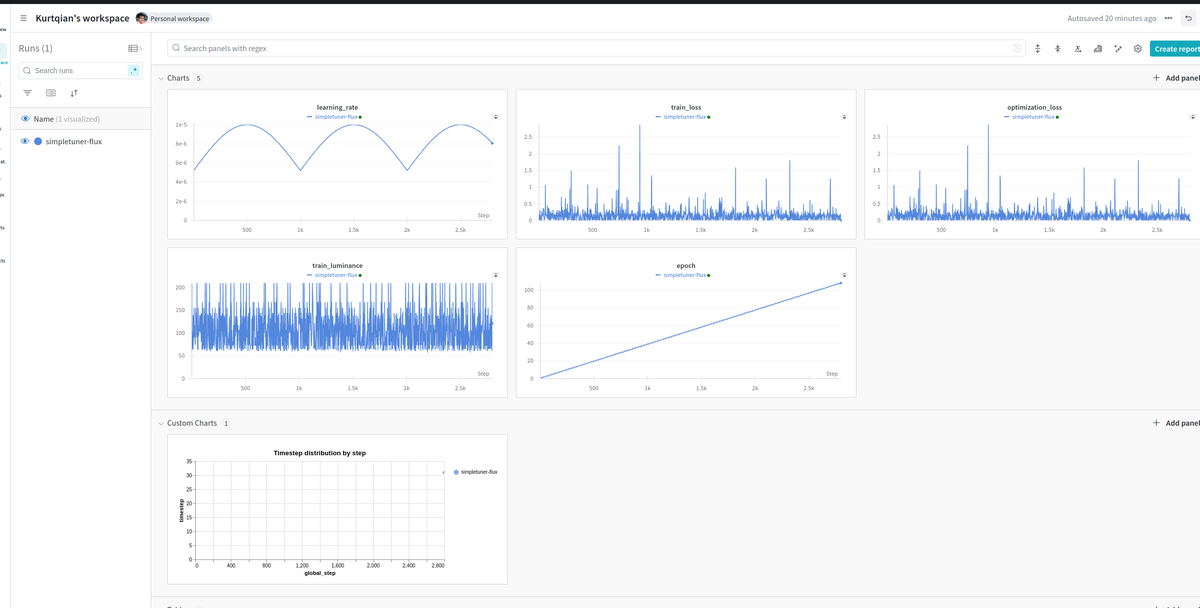
after some Flux Lora hyperparameter fine-tuning and 3000 steps,just load the lora model in ComfyUI,the human being aethetic image is much more better than SDXL,validation eval and generation portrait not bad, the LR set with 4e-4 and optimizer adafactor,it's the tricky part