We introduce 🌍GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens.🌍
Most feed-forward 3DGS methods still start from pixel, voxel, or dense view-aligned primitives.
We take a different route: align first, decode later. 🧵👇
🚨 Excited to share our new paper: "PhyGenHOI: Physically-Aware 4D Generation of Dynamic Human-Object Interactions"! 🎉 We tackle generating photorealistic 4D interactions by deeply coupling generative human motion diffusion with physical simulation! 🧠���🧵👇(1/4)
Excited to share Colored Noise Sampling (CNS)!🎉
Instead of injecting white noise, our SDE sampler exploits the inherent spectral bias of diffusion models. We dynamically color the injected noise to focus on frequencies where details are missing, substantially improving FID.🧵1/9
We suggest going back to relative pose modeling,
enabling efficient and robust 3D reconstruction with low memory overhead — in both streaming and offline settings.
Project: https://t.co/Ji6Uipd5sL
Paper: https://t.co/bUzsHX3XdQ
Our paper:
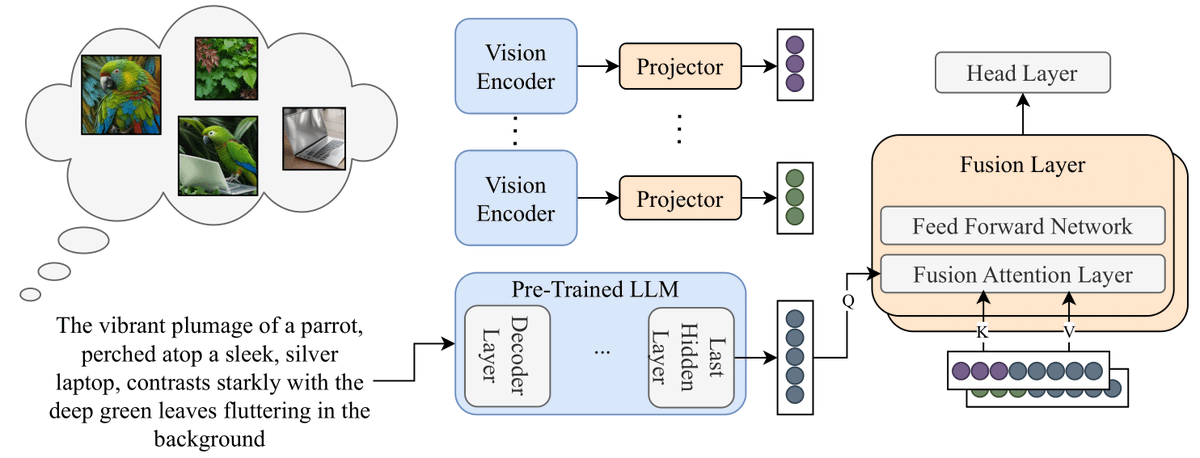
"LaMI: Augmenting Large Language Models via Late Multi-Image Fusion"
has been selected for an Oral Presentation at #ACL2026!
LaMI boosts LLM visual commonsense by generating complementary images from a text prompt and late-fusing their evidence into the prediction
🧵
Happy to share that our work "RAD: Retrieval-Augmented Monocular Metric Depth Estimation for Underrepresented Classes" was accepted to #CVPR2026 (findings).
Check out the project page: https://t.co/HwIMDBPxXd
Very excited to share the first paper from my postdoc, led by the talented @JieZhang_ETH . This was an extremely fun project with a great group of people 🥸
GlobalSplat: Stop unprojecting, start decoding. 🛠️
We fuse all input views into a fixed set of Global Scene Tokens to build high-fidelity 3D assets without the pixel-wise redundancy.
✅ Higher quality
✅ Better spatial allocation
🔗 https://t.co/m6ROsAOck8
#3DGS
GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
@ItkRoni, @IssacharNoam, @YehonatanKe, @RoverXingyu, @AnpeiC, @BenaimSagie
tl;dr: all input views->a fixed number of latent scene tokens->decoder->explicit 3D Gaussians
https://t.co/g038S2pRsz
We introduce 🌍GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens.🌍
Most feed-forward 3DGS methods still start from pixel, voxel, or dense view-aligned primitives.
We take a different route: align first, decode later. 🧵👇
Strong efficiency-quality operating point:
24 Views on A100:
1.79 GB peak GPU memory
77.88 ms inference
3.8 MB on disk
With as few as 2–32K Gaussians, 🌍GlobalSplat🌍 has better PSNR on RE10K then feed-forward 3DGS methods that use hundreds of thousands to millions of Gaussians.