Fully agree with the part about being curious.
This applies to learning anything new: if you only learn for the reward, you will not go far.
You have to be curious, explore things on your own, discover things from first principles and enjoy the process.
everyone wants a hacking roadmap.
the problem is that roadmaps don't create hackers.
curiosity does.
ctfs are changing, ai is everywhere, and the game looks very different now.
how i'd start hacking in 2026: https://t.co/VZS76KTHWJ
Introducing Flue — The First Agent Harness Framework
Flue is a TypeScript framework for building the next generation of agents, designed around a built-in agent harness.
Flue is like Claude Code, but 100% headless and programmable. There's no baked in assumption like requiring a human operator to function. No TUI. No GUI. Just TypeScript.
But using Flue feels like using Claude Code. The agents you build act autonomously to solve problems and complete tasks. They require very little code to run. Most of the "logic" lives in Markdown: skills and context and AGENTS.md.
Flue is like Astro or Next.js for agents (not surprising, given my background 🙃). It's not another AI SDK. It's a proper runtime-agnostic framework. Write once, build, and deploy your agents anywhere (Node.js, Cloudflare, GitHub Actions, GitLab CI/CD, etc).
We originally built Flue to power AI workflows inside of the Astro GitHub repo. But then @_bgiori got his hands on it, and we realized that every agent needs a framework like Flue, not just us.
Check it out! It's early, but I'm curious to hear what people think. Are agents ready for their library -> framework moment?
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
I built autoresearch-rl and pointed it at GRPO fine-tuning on @basilic_ai A100s. One command. 15 iterations. Zero human intervention. 100% infrastructure success rate.
GSM8K pass@1: 26% baseline to 36%.
The hard part wasn't the search algorithm. It was the infrastructure.
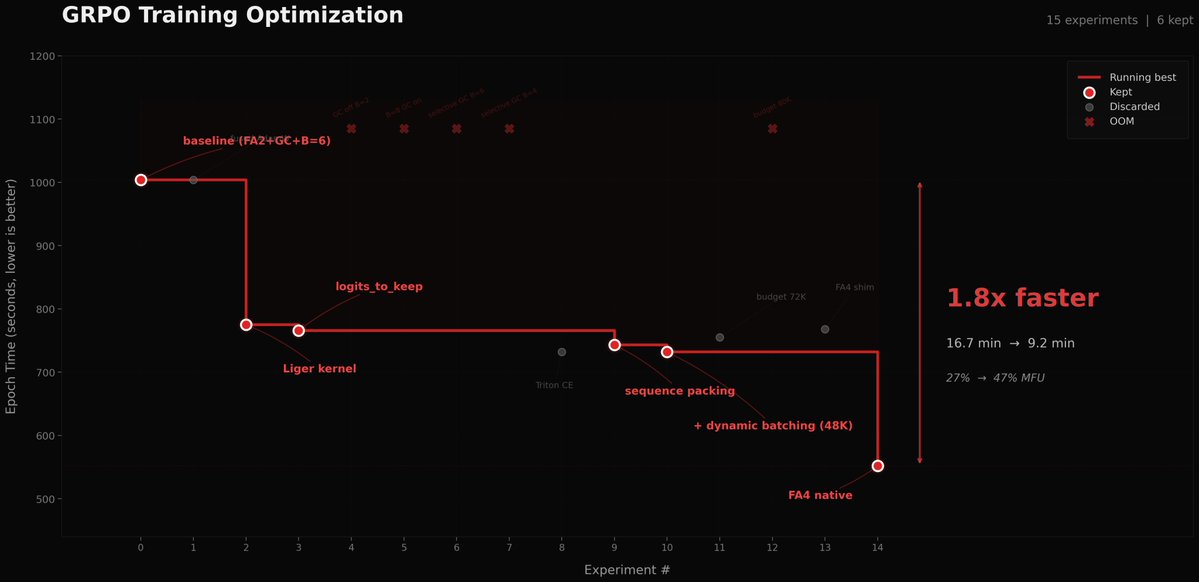
Used autoresearch to make @grail_ai GRPO trainer 1.8x faster on a single B200.
I kept postponing this for weeks since the bottleneck in our decentralized framework was mainly communication. But after our proposed technique, PULSE, made weight sync 100x faster, the training update itself became the bottleneck. Even with a fully async trainer and inference, a slow trainer kills convergence speed.
A task that could've eaten days of my time ran in parallel while I worked on other stuff. Unlike original autoresearch, where each experiment is 5 min, our feedback loop is way longer (10-17 min per epoch + 10-60 minutes of installations and code changes), so I did minimal steering when it was heading in bad directions to avoid burning GPU hours. The agent tried so many things that failed. But, eventually found the wins: Liger kernel, sequence packing, token-budget dynamic batching, and native FA4 via AttentionInterface.
27% to 47% MFU. 16.7 min to 9.2 min per epoch.
If you wanna dig deeper or contribute: https://t.co/8S7MnvwxMa
We're optimizing everything at the scale of global nodes to make decentralized post-training as fast as centralized ones. Stay tuned for some cool models coming out of this effort.
Cheers!
Over the last ~2 weeks I've rewritten the @ladybirdbrowser JavaScript compiler in Rust using AI agents.
~25k lines of safe Rust (20k if you exclude comments). No regressions on test262 or our own internal test suites.
Extensively tested against the live web by browsing in lockstep mode where we run both the C++ and Rust pipelines, and then verify identical AST & bytecode.
We're making a pragmatic decision and adopting Rust as a C++ successor language. What a time to be alive!