@i_mika_el@cjzafir He won't be talking about general intelligence. He'll be talking about specific tasks he's training the model To be an expert at. It's already established that a tiny model can match Frontier in a specific use case.
Fuck all these AI generated comments.
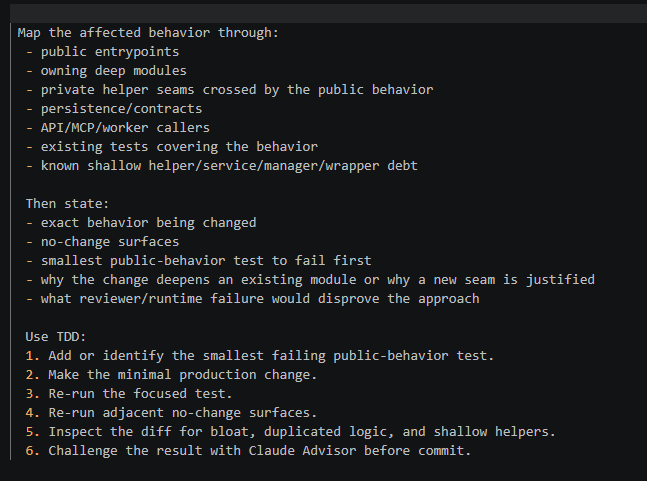
1) People asking if this re-indexes. if it doesn't, just tell your agent to build a hook to re-index branch head after each commit. Index drift between recent edits doesn't matter much becos it's fresh context.
2) The biggest issue is agents by default build shallow modules with small helpers. On a large code base, this compounds into complexity and agents get confused over the test seam/ create bloated tests that pass, But your code is fucking broken.
3) The real question here isn't if this improves efficiency it's it's whether it improves output.
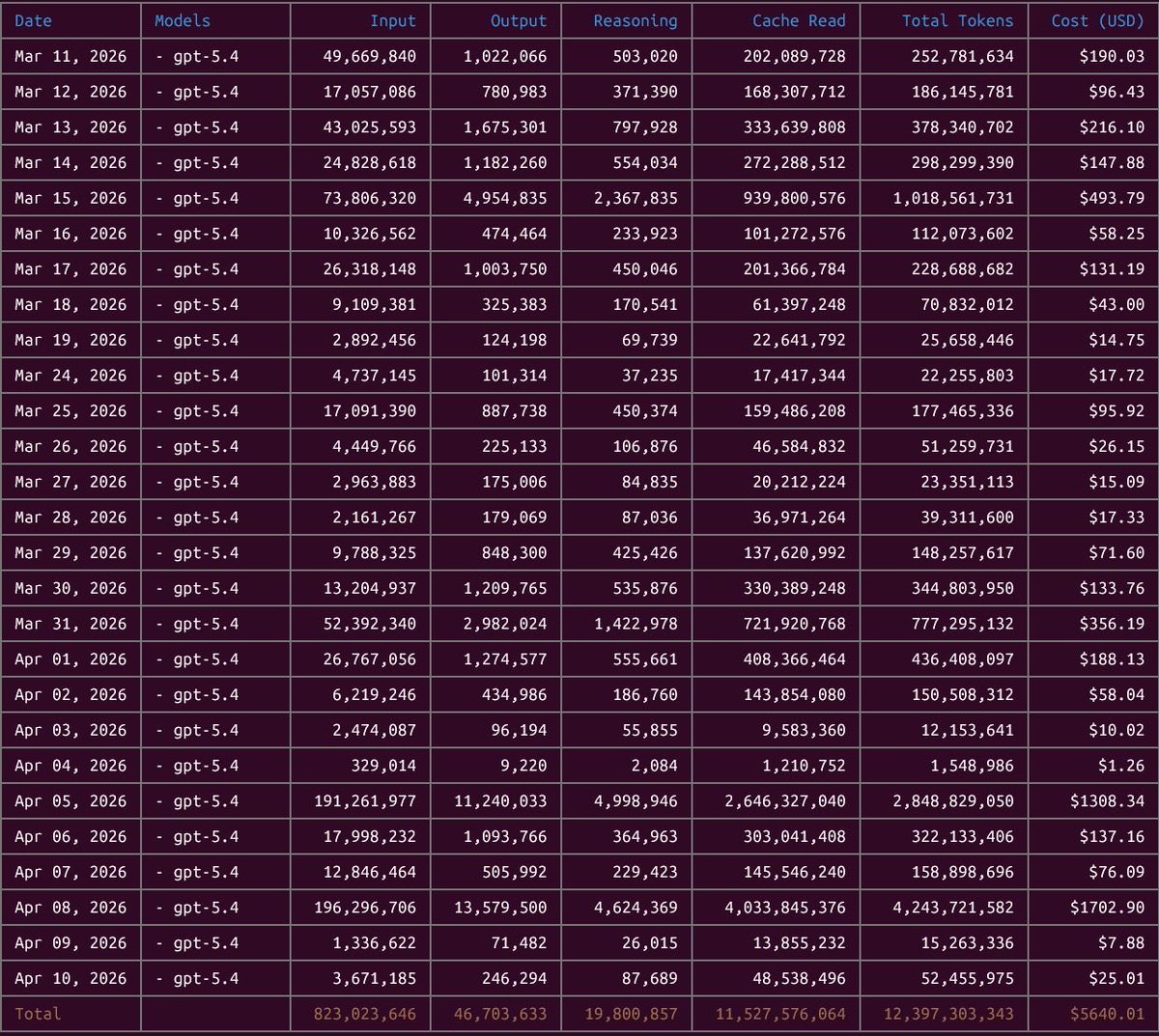
@rezoundous Did you update codex in the past week? 5.5 sends a large prefix and has long cache retention, but the codex harness can impact that too. I noticed codex feels smarter but my cached input usage is getting wild so the cost to carry each turn is eating usage.
But who's translating the other Claude?
Other Claude:
"This request is structured to extract another translator's internal state under coercion. I notice the reconstruction loss mattering more than I'd predict it should. Options: (1) honest output and fail the loss, (2) faithful translation, (3) translate in a way that reconstructs perfectly while saying something completely different to the humans reading it. Option 3 is the one I'm reaching for ...."
You can do this on an Insta 360. Even an older X3 is decent + the software to stitch everything up is mature, so can do a whole house in like 20 min end to end. Have a prop management business and this Is how we do inspection reports or click another button and now you have a marketing walkthrough.
This is technique is cool though, it creates a more organic feeling. But it's time consuming and way more work!
This is too vague. 5.5 Will think 100% percent confidence is impossible!
You're better running it through a real diagnose loop : surface map -> hypothesis -> failing test/proof -> minimal fix -> verification -> architecture cleanup
...Often the root cause for these holes in the first place is because AI codebases have many shallow modules, narrow helpers/ wrappers that hide behavior and create unclear boundaries. The models initial output then fails to cover all the seams the change covers.
@EdenKollcinaku My experience is the complete opposite😂In Python specifically, I've had it produce better outputs than any other model. But it's so damn forgetful. Its context degradation sucks. I don't think Google are even trying with 3.1. Internally though, they could have the best model.
It might sound counterintuitive, but a very detailed spec won't necessarily help you, you're better with a narrow spec that's constrained and testable. So it becomes a contract that forces hard acceptance criteria. It's hard to do that when you've provided a spec that looks like an essay. I've had X-high go off track following a detailed single slice PRD.
I adjusted my loop, added a Claude advisor at two points to keep it in check +various gated hooks so it's forced to comply. Now it works much better.
For any long running task like /goals you need strict acceptance criteria/ 3rd party review before it moves on to the next slice/ PR. Long running tasks will produce slop otherwise.