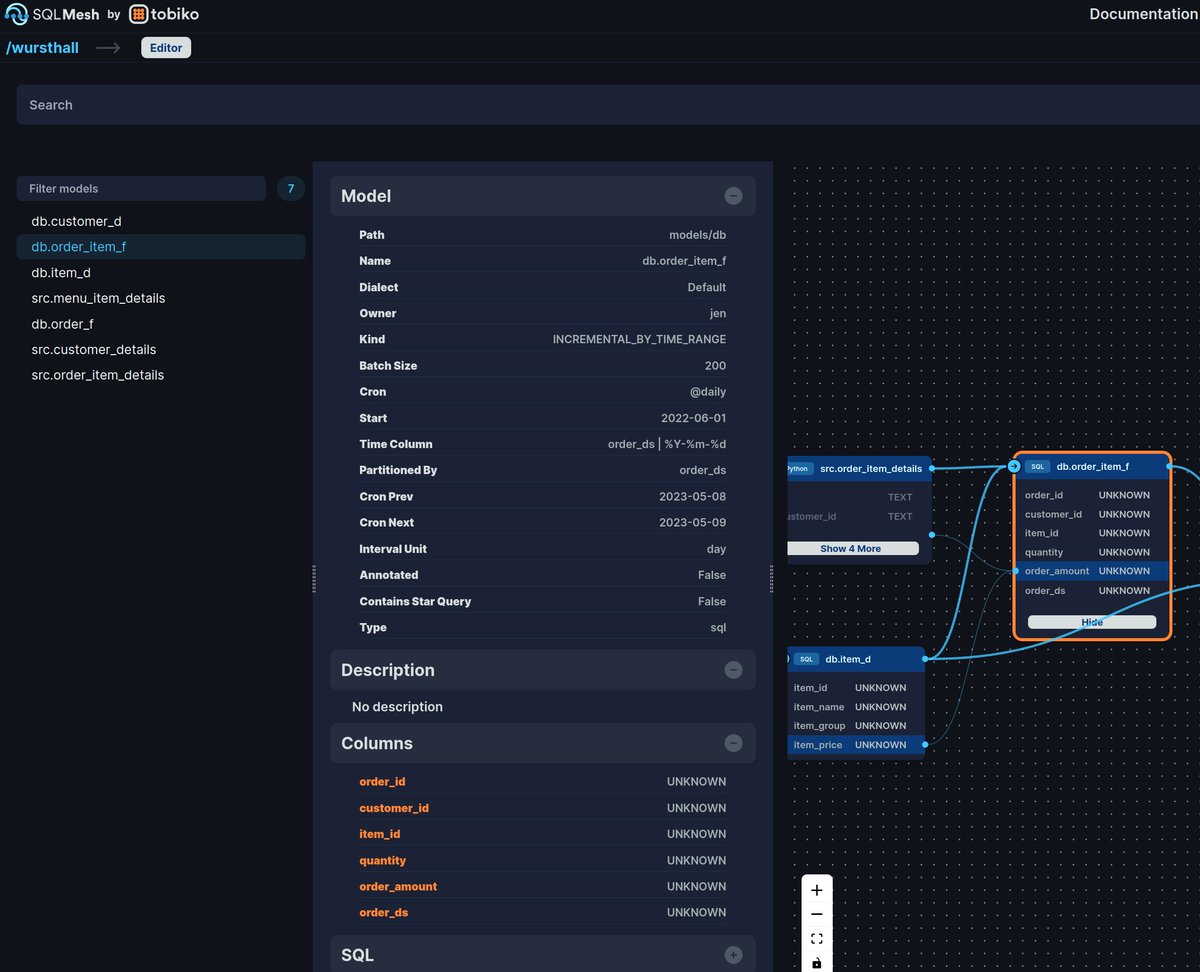
Today dbt announced column level lineage... but it's not open source and only available for paying cloud users.
dbt is using SQLGlot (an open source SQL framework that my company @TobikoData maintains) to power this newly gated feature. SQLGlot's lineage wouldn't exist without the open source community so it's kind of a shame.
But there's an open source alternative to dbt cloud... @SQLMesh, where column level lineage is free and open source for everyone to use.
SQLMesh is backwards compatible with existing dbt projects, so you can gain all of its benefits without rewriting your project.
Check out our blog post about lineage through SQLMesh's open source UI / IDE.
https://t.co/shEr4IwvMx
If you want to chat about how we can make data transformation better for everyone, we'd love to chat in our slack channel at https://t.co/2GLrrie7Xz.
Unlike dbt, SQLMesh was designed to work efficiently with extremely large scales of data. Stop hemorrhaging money and stop wasting time manually managing big data sets!
We've spent a lot of time on automated frameworks for working with massive data.
https://t.co/7XcCt2Ly3C
@rahulj51 I think it's more than realistic to add native support for models defined using Malloy to @SQLMesh and then utilize its transpilation capabilities to target any engine.
@SQLMesh v0.28.0 supports MSSQL (Microsoft SQL Server). Even better, it was contributed by a community member Dan!
I'm so excited to see SQLMesh grow and gain traction!
https://t.co/CBiK88r3uM
https://t.co/R0dnitMbpW
#dataengineering
Alex Butler, senior data engineer at SF-based software delivery company @harness, chose @dltHub + @SQLMesh to build an end to end data platform 💪
Learn more about his developer journey as he continues to build out the platform & its benefits to Harness
https://t.co/gGXkfi9ePj
Are you using dbt and have heard of @SQLMesh but aren't quite sure what it is?
You are in luck, because this article is for you! We will teach you the basics of SQLMesh from a dbt user's perspective to help get you up to speed.
https://t.co/qeXZUnBBzR
Although companies heavily rely on SQL / data pipelines to power applications and make decisions, testing is usually an afterthought. However, systematic testing of data is critical to creating trustworthy and reliable pipelines.
https://t.co/0DUPpYS3X0
As the usage of dbt grows, the cracks in its architecture become more apparent. You can either have simplicity or efficiency... but why should you have to choose?
Check out this amazing blog post by @izeigerman detailing the costs associated with dbt.
https://t.co/8FysLkXKBN
@ArynnPost We recently published a blog post about all the awesome things SQLMesh is able to achieve thanks to the semantic understanding of SQL
https://t.co/bPhsGfcr8T
We spend so much time writing #SQL. Why don't our tools understand SQL? When you parse SQL you unlock:
- Column Level Lineage
- Automatic dependencies (no more {{ ref() }})
- Transpilation
Check out this great post by @izeigerman
https://t.co/lALjSYrFZK
SQLMesh v0.8.0 just dropped! Some exciting new features like docs which is integrated inside the IDE!
We've also launched our Github CI / CD bot!
https://t.co/ir8WioHMxJ
I wrote a post hoping to demystify incremental loads for data pipelines. Even if you don't have Netflix's data scale, incremental loads can save you time and money!
https://t.co/saYeyK8Flg
#dataengineering#sql
My new post on categorizing changes in #SQL queries is out!
This is one of the key components for how we achieve automatic #data contracts in @SQLMesh.
Managing a large project with interconnected #SQL queries can be extremely challenging. Understanding how changes impact downstream queries is important so that your data is always correct and consistent.
https://t.co/rV791ttgGk
#dataengineering
Yesterday, dbt announced contracts and versions. They're just additional YAML syntax further contributing to the pile of spaghetti code/configs.
It puts even more burden on the end user without solving the underlying problems.
https://t.co/DPzp9sUojJ
dbt's inherent inefficiency is good for Snowflake's bottom line, but not your team.
How many times does your data team fully copy your warehouse just to make a simple change?
@izeigerman explains how we can finally stop this madness
https://t.co/GzB7N1VoO2
I love how DevOps enables software engineers to safely ship code faster.
As a data engineer, I think we deserve something similar: the DataOps revolution.
Here’s a 🧵 on why I made SQLMesh, an open source DataOps framework, which launches today https://t.co/wkoUua8O7g