Had a great first day at #HSP2026 yesterday! Looking forward to presenting on the relationship between reading time, n-grams, and language model scaling at the 12.10-2pm poster session today!
Excited to announce that I’ll be presenting a paper at #NeurIPS this year! Reach out if you’re interested in chatting about LM training dynamics, architectural differences, shortcuts/heuristics, or anything at the CogSci/NLP/AI interface in general! #Neurips2025
Excited to announce that I’ll be presenting a paper at #NeurIPS this year! Reach out if you’re interested in chatting about LM training dynamics, architectural differences, shortcuts/heuristics, or anything at the CogSci/NLP/AI interface in general! #Neurips2025
@jamichaelov and I will be presenting our paper at the @CogInterp workshop 13:15 - 14:45 on Dec 7th. We show how disaggregating grammatical benchmarks over the course of training reveals stages of training where models learn heuristics before learning more generalizable patterns.
Excited to announce that I’ll be presenting a paper at #NeurIPS this year! Reach out if you’re interested in chatting about LM training dynamics, architectural differences, shortcuts/heuristics, or anything at the CogSci/NLP/AI interface in general! #Neurips2025
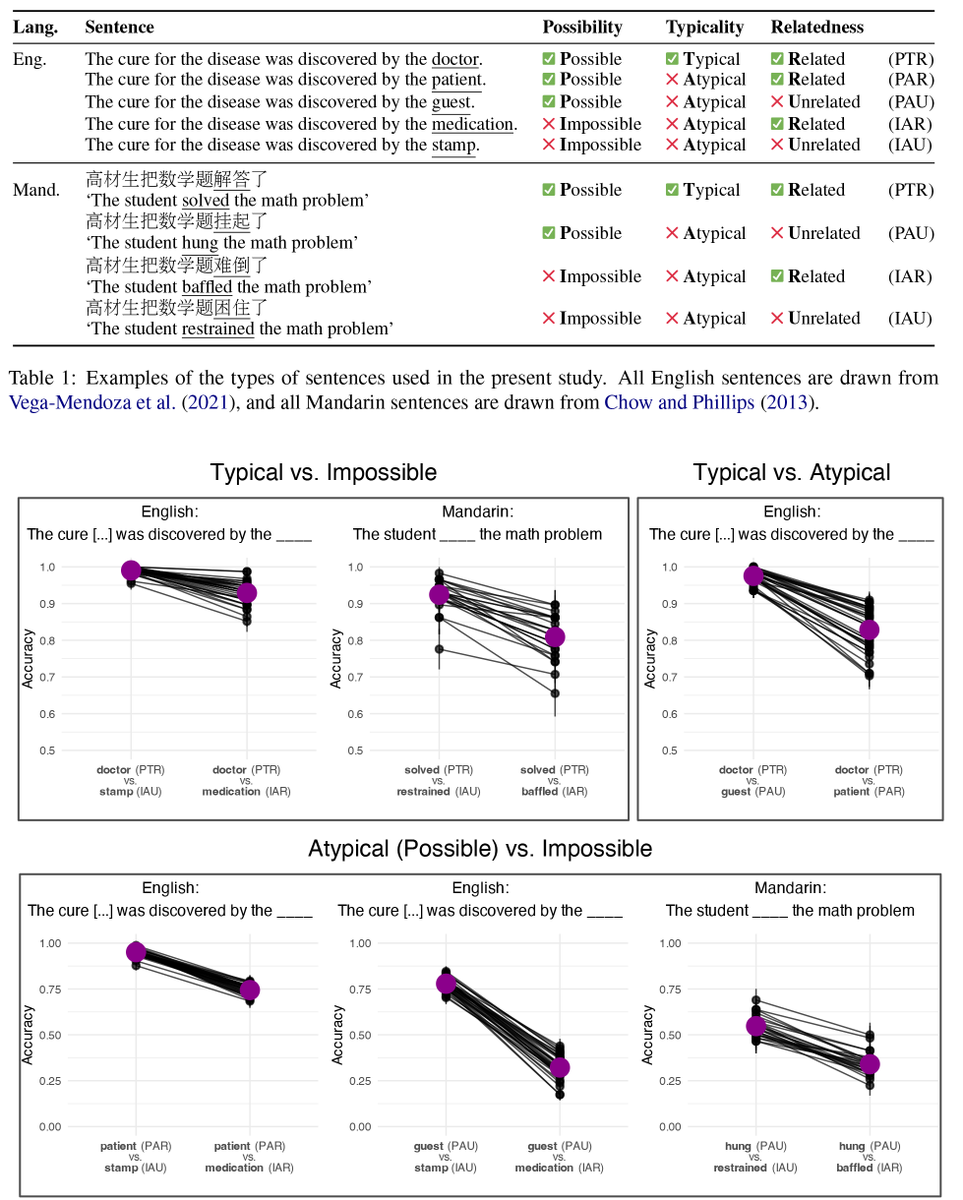
New paper accepted at Findings of ACL! TL;DR: While language models generally predict sentences describing possible events to have a higher probability than impossible (animacy-violating) ones, this is not robust for generally unlikely events + is impacted by semantic relatedness
In the most extreme case, LMs assign sentences such as ‘the car was given a parking ticket by the explorer’ (unlikely but possible event) a lower probability than ‘the car was given a parking ticket by the brake’ (impossible event, related final word) over half of the time.
✨New pre-print✨ Crosslingual transfer allows models to leverage their representations for one language to improve performance on another language. We characterize the acquisition of shared representations in order to better understand how and when crosslingual transfer happens.
Also generally interested in chatting about cognitive modeling, scaling, and language comprehension/understanding in humans and machines! @COLM_conf#COLM2024
New preprint with @linguist_cat and Ben Bergen! We’ve all heard of the new wave of recurrent language models, but how good are they for modeling human language comprehension? Quite good, it turns out! 🧵 https://t.co/ADtxfcDVBb
This paper is now accepted to be presented at @COLM_conf! Updated version is on arXiv. Feeling excited for the conference, let me know if you want to meet!
New preprint with @linguist_cat and Ben Bergen! We’ve all heard of the new wave of recurrent language models, but how good are they for modeling human language comprehension? Quite good, it turns out! 🧵 https://t.co/ADtxfcDVBb
@linguist_cat And the current wave of recurrent architectures has just started! As we see more and more new architectures and developments, it will be interesting to see how they compare. One thing does seem clear though: recurrent models are back with a vengeance!
New preprint with @linguist_cat and Ben Bergen! We’ve all heard of the new wave of recurrent language models, but how good are they for modeling human language comprehension? Quite good, it turns out! 🧵 https://t.co/ADtxfcDVBb
@linguist_cat With reading time, the results are more variable between experiments, and this seems like it might be related to the difference in stimuli (see paper for more details)
5️⃣Michaelov etal. find surprisal explains N400s to sentence-final words varying in predictability, plausibility, and relation to the likely completion better than sem. similarity. The results support lexical predictive coding accounts. https://t.co/EnuOJeNO9O @jamichaelov 7/n
NAACL 2024 seems to charge $750 for students to register if they're a presenter (every paper requires at least one registered presenter). @naacl am I reading this right? Seems like a major burden on students, especially if (as is common) only a paper's student authors attend.
👶 BabyLM Challenge is back!
Can you improve pretraining with a small data budget?
BabyLMs for better LLMs
& for understanding how humans learn from 100M words
New:
How vision affects learning
Bring your own data
Paper track
https://t.co/uU12YWwLTe
🧵