TPUs power inference across the models we serve on the Gemini Enterprise Agent Platform, and enable training for Deepmind and our customers.
Very excited for the launch of our eighth generation of TPUs!
We’re introducing our eighth generation of TPUs. This time, we’re taking a dual chip approach: TPU 8t, optimized for training, and TPU 8i, optimized for inference.
💪TPU 8t achieves nearly three times the compute performance per pod over our previous generation, Ironwood.
⚡TPU 8i connects 1,152 TPUs in a single pod to deliver the massive throughput and low latency needed to concurrently run millions of agents cost-effectively.
These new TPUs are a crucial part of our fully integrated AI stack — from the chips all the way up to the models, developer tools, agents and applications. By designing the hardware and software in tandem, we’re able to deliver scale and efficiency. #GoogleCloudNext
Build an AI app with Nano Banana Pro and Veo 3.1 that turns any location into cinematic art.
Just type a city and get 3D videos of its weather, architecture, and mood in real-time.
100% Opensource code.
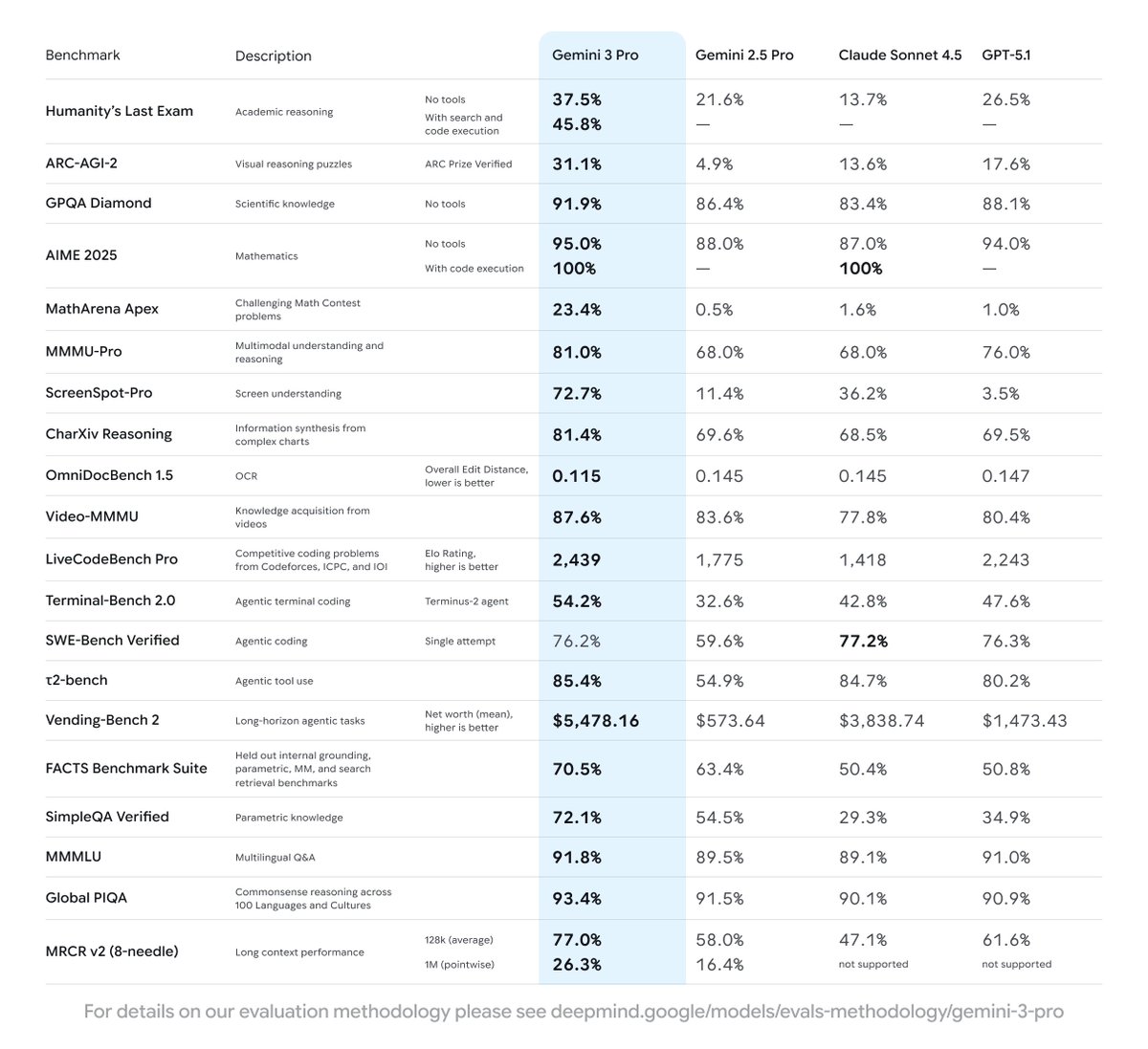
@GoogleDeepMind has done it! Gemini 3 is state-of-the-art across a range of key AI benchmarks!
Gemini 3 is available now in Vertex AI, Gemini Enterprise, Gemini CLI, and more.
It’s our most powerful agentic and vibe-coding model yet.
https://t.co/NUXWerF1Si
We're expanding Vertex AI Training with new managed features to give developers the flexibility to train, tune, and develop highly differentiated models. https://t.co/uW9WDl2t6g
Introducing the first-ever Google Agents Development Kit (ADK) Community Call.
Come meet the team, learn about our AI Agents roadmap and ask any question you may have.
Happening next Wednesday at 9:30-10:30am PT (link below)
Build a multi-agent home renovation team with Google ADK and Gemini 2.5 Flash Nano Banana.
Just upload your room photo, design inspiration and budget to get a complete renovation plan with material, cost, timeline, and an after image of your new room.
100% Opensource code.
Building voice AI Agents has never been easier.
New updates to Gemini Live API with Native Audio lets you build AI Agents that understand emotion, ignore background noise, use tools like RAG, MCP & search.
https://t.co/GYjIDtirNi
🚀 LAUNCHED: The A2A protocol is now natively integrated on Vertex AI Agent Engine!
Deploying A2A with Agent Engine previously involved complex processes with separate runtimes and "glue code."
I'm excited to share the native integration of the A2A protocol with Vertex AI Agent Engine, making it easier to build and deploy collaborative AI agents at scale.
TLDR:
✅ Deploy A2A agents with a single template
✅ Scale easily on a secure endpoint on Agent Engine
✅ Get a clean, reusable API for simple integration
Code and blog in 🧵
Introducing Open Deep Research!
A fully open-source Deep Research tool that:
• writes comprehensive reports
• does multi-hop search and reasoning
• generates cover images & pod-casts!
We’re releasing everything: evaluation dataset, code and blog.🔥
Example output report👇
Thank you @ErikaBatista, @GetLago, @oanaolt, @huggingface for hosting! Great event and incredible presentations from so many talented founders. Look forward to seeing all of these companies grow!
Energizing open source AI founder meetup at @SignalFire hosted by @ErikaBatista@byAnhtho@oanaolt@GetLago@togethercompute. Got to hear more than 30 pitches (majority female founders) with many planning to open source very cool models, datasets and apps in the coming months, let’s go!
These models are incredible, and a massive step forward for OSS AI. Amazing work from @Meta team!
On @togethercompute now at 350 t/s for full precision on 8B and 150 t/s on 70B.
https://t.co/YEuZAzGzpX
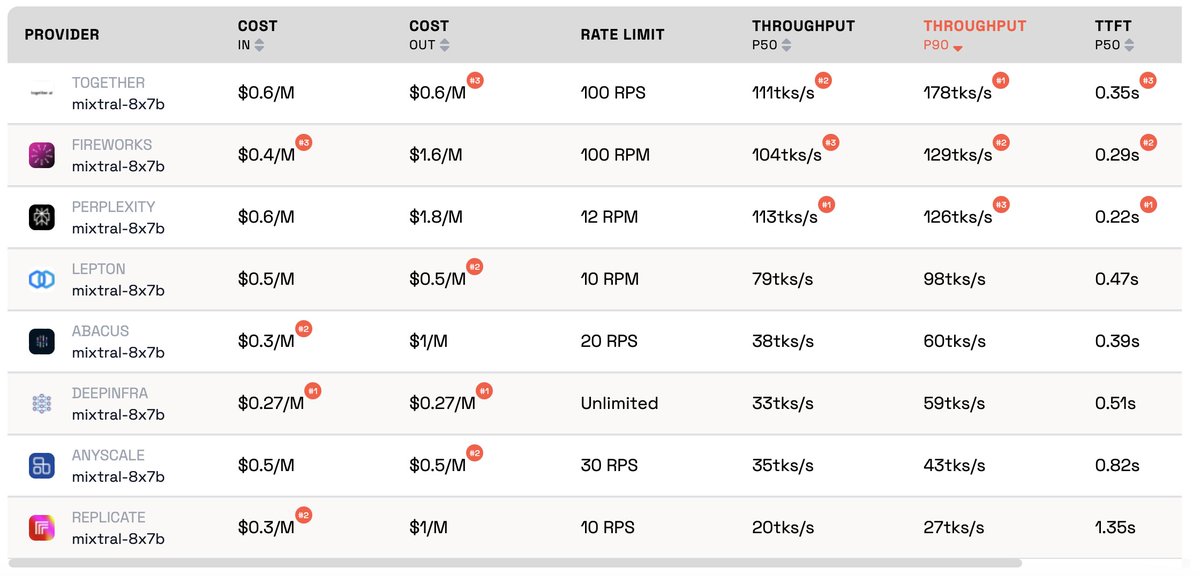
The serverless inference API @togethercompute is likely #1 in volume for OSS models (numbers coming soon!). We are also #1 on performance for almost all regimes according to Martian leaderboard, while providing 6000 RPM rate-limit to anyone who signs up and puts down a CC.
https://t.co/Xx275qH7uJ
Three teams have been dominating the LLM game for a while:
@MistralAI for sota LLMs 🦙
@langchain for building with LLMs 🦜 @togethercompute for serving LLMs 🚀
If you know how, you can build things really, really fast now.
Brief intro and code walk-through for you 👇
Announcing StripedHyena 7B — an open source model using an architecture that goes beyond Transformers achieving faster performance and longer context.
It builds on the lessons learned in past year designing efficient sequence modeling architectures.
https://t.co/UGLnfz0Dma