I have been fine-tuning LLMs for over 2 years now!
Here are the top 5 LLM fine-tuning techniques, explained with visuals:
First of all, what's so different about LLM finetuning?
Traditional fine‑tuning is impractical for LLMs (billions of params; 100s GB).
Since this kind of compute isn't accessible to everyone, parameter-efficient finetuning (PEFT) came into existence.
Before we go into details of each technique, here's some background that will help you better understand these techniques:
LLM weights are matrices of numbers adjusted during finetuning.
Most PEFT techniques involve finding a lower-rank adaptation of these matrices, a smaller-dimensional matrix that can still represent the information stored in the original.
Now with a basic understanding of the rank of a matrix, we're in a good position to understand the different finetuning techniques.
(refer to the image below for a visual explanation of each technique)
1) LoRA
- Add two low-rank trainable matrices, A and B, alongside weight matrices.
- Instead of fine-tuning W, adjust the updates in these low-rank matrices.
Even for the largest of LLMs, LoRA matrices take up a few MBs of memory.
2) LoRA-FA
While LoRA significantly decreases the total trainable parameters, it requires substantial activation memory to update the low-rank weights.
LoRA-FA (FA stands for Frozen-A) freezes matrix A and only updates matrix B.
3) VeRA
- In LoRA, low-rank matrices A and B are unique for each layer.
- In VeRA, A and B are frozen, random, and shared across all layers.
- Instead, it learns layer-specific scaling VECTORS (b and d) instead.
4) Delta-LoRA
- It tunes the matrix W as well, but not in the traditional way.
- Here, the difference (or delta) between the product of matrices A and B in two consecutive training steps is added to W.
5) LoRA+
- In LoRA, both matrices A and B are updated with the same learning rate.
- Authors of LoRA+ found that setting a higher learning rate for matrix B results in better convergence.
____
Find me → @akshay_pachaar
Every day, I share tutorials and insights on ML, LLMs, and AI Engineering.
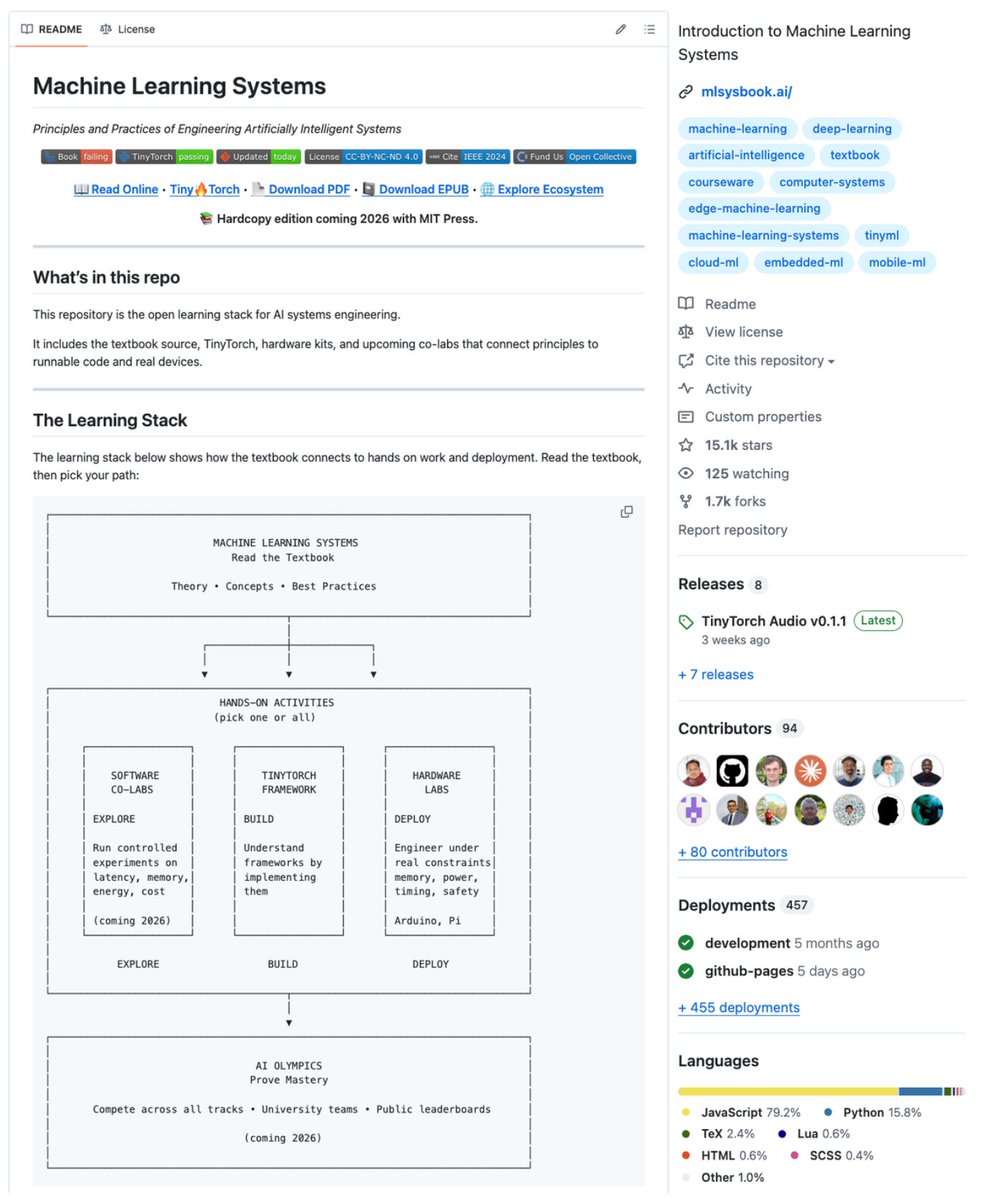
Harvard just open-sourced an entire ML Systems curriculum.
The complete learning stack for AI engineering:
- A textbook
- TinyTorch (build ML frameworks from scratch)
- Hardware kits for Arduino and Raspberry Pi
- Notebooks connecting theory to runnable code
100% open-source.
I have been developing Agentic Systems for the past few years and the same patterns keep emerging. 👇
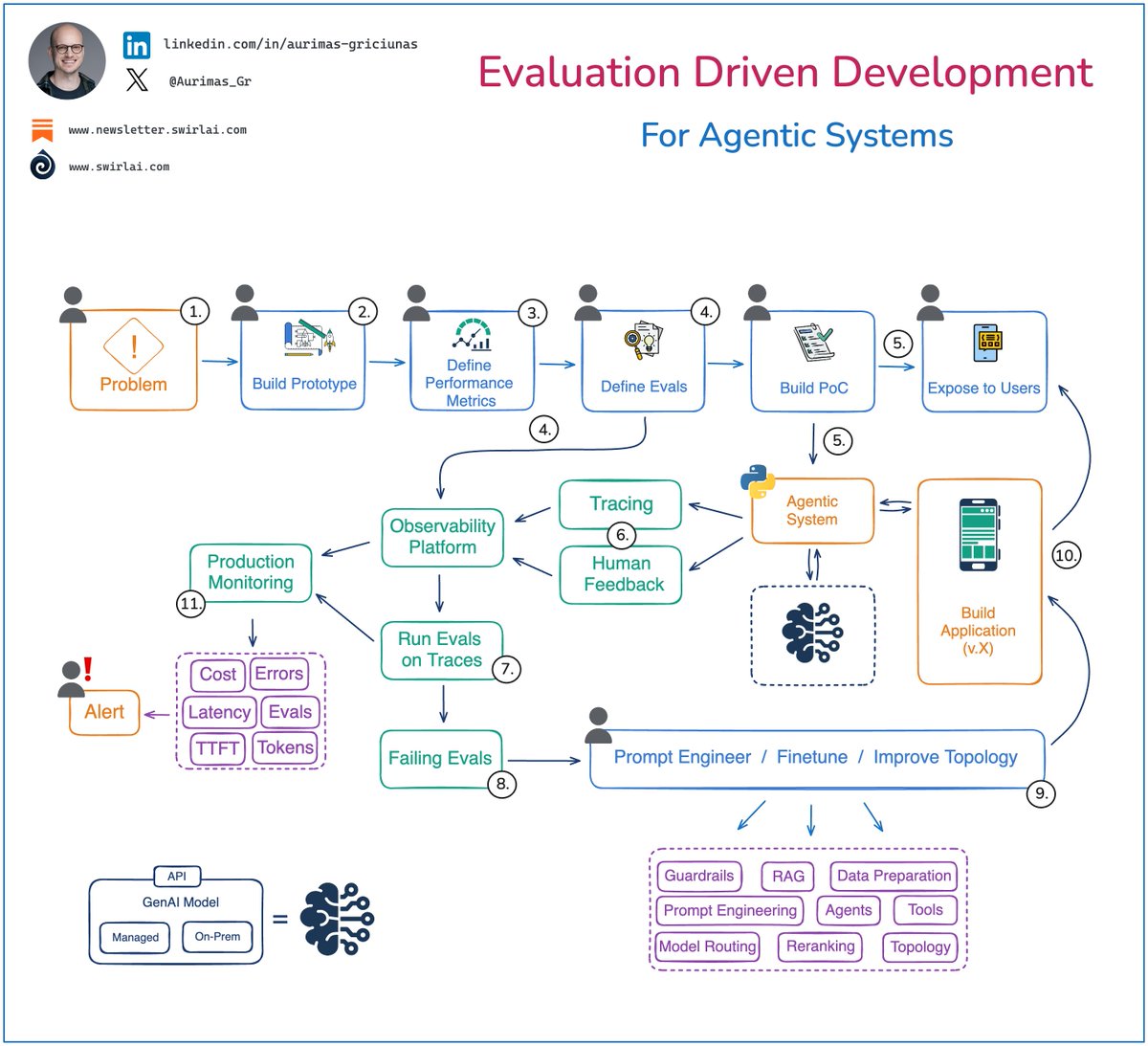
𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗗𝗿𝗶𝘃𝗲𝗻 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁 is the most reliable way to be successful in building your 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺𝘀 - here is my template.
Let’s zoom in:
𝟭. Define a problem you want to solve: is GenAI even needed?
𝟮. Build a Prototype: figure out if the solution is feasible.
𝟯. Define Performance Metrics: you must have output metrics defined for how you will measure success of your application.
𝟰. Define Evals: split the above into smaller input metrics that can move the key metrics forward. Decompose them into tasks that could be automated and move the given input metrics. Define Evals for each. Store the Evals in your Observability Platform.
ℹ️ Steps 𝟭. - 𝟰. are where AI Product Managers can help, but can also be handled by AI Engineers.
𝟱. Build a PoC: it can be simple (excel sheet) or more complex (user facing UI). Regardless of what it is, expose it to the users for feedback as soon as possible.
𝟲. Instrument your application: gather traces and human feedback and store it in an Observability Platform next to previously stored Evals.
𝟳. Run Evals on traced data: traces contain inputs and outputs of your application, run evals on top of them.
𝟴. Analyse Failing Evals and negative user feedback: this data is gold as it specifically pinpoints where the Agentic System needs improvement.
𝟵. Use data from the previous step to improve your application - prompt engineer, improve AI system topology, finetune models etc. Make sure that the changes move Evals into the right direction.
𝟭𝟬. Build and expose the improved application to the users.
𝟭𝟭. Monitor the application in production: this comes out of the box - you have implemented evaluations and traces for development purposes, they can be reused for monitoring. Configure specific alerting thresholds and enjoy the peace of mind.
✅ 𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗼𝘂𝘀 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁 𝗼𝗳 𝘆𝗼𝘂𝗿 𝗮𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻:
➡️ Run steps 𝟲. - 𝟭𝟬. to continuously improve and evolve your application.
➡️ As you build up in complexity, new requirements can be added to the same application, this includes running steps 𝟭. - 𝟱. and attaching the new logic as routes to your Agentic System.
➡️ You start off with a simple Chatbot and add a route that can classify user intent to take action (e.g. add items to a shopping cart).
What is your experience in evolving Agentic Systems? Let me know in the comments 👇
#LLM #AI #MachineLearning
if you're looking for a roadmap to get started on AI engineering, this is a free repo to hold your hand along the way. it includes the courses, youtube videos, and blog posts, all you need to self-learn critical topics:
→ mathematics of machine learning
→ ML and computer vision
→ deep neural networks
→ gen AI and RAG
→ agentic AI
→ reinforcement learning
check it out here: https://t.co/3PgqHFqv2I
New Tencent paper lets LLMs choose their own temperature and top-p for each token, improving output and control.
Hand tuning disappears, saving time and guesswork.
Today people set those knobs by hand, and the best settings change inside a single answer.
Their method, AutoDeco, adds 2 small heads that read the hidden state and predict the next token's temperature and top-p.
They replace the hard top-p cutoff with a smooth one so training can teach those heads directly.
During generation the model applies the predicted temperature and top-p in the same pass, adding about 1-2% time.
Across math, general questions, code, and instructions, this beats greedy and default sampling and matches expert tuned static settings.
It also follows plain prompts like low diversity or high certainty by shifting those values the right way.
So hand tuning goes away, the model adapts token by token, and steering becomes simple and reliable.
----
Paper – arxiv. org/abs/2510.26697
Paper Title: "The End of Manual Decoding: Towards Truly End-to-End Language Models"
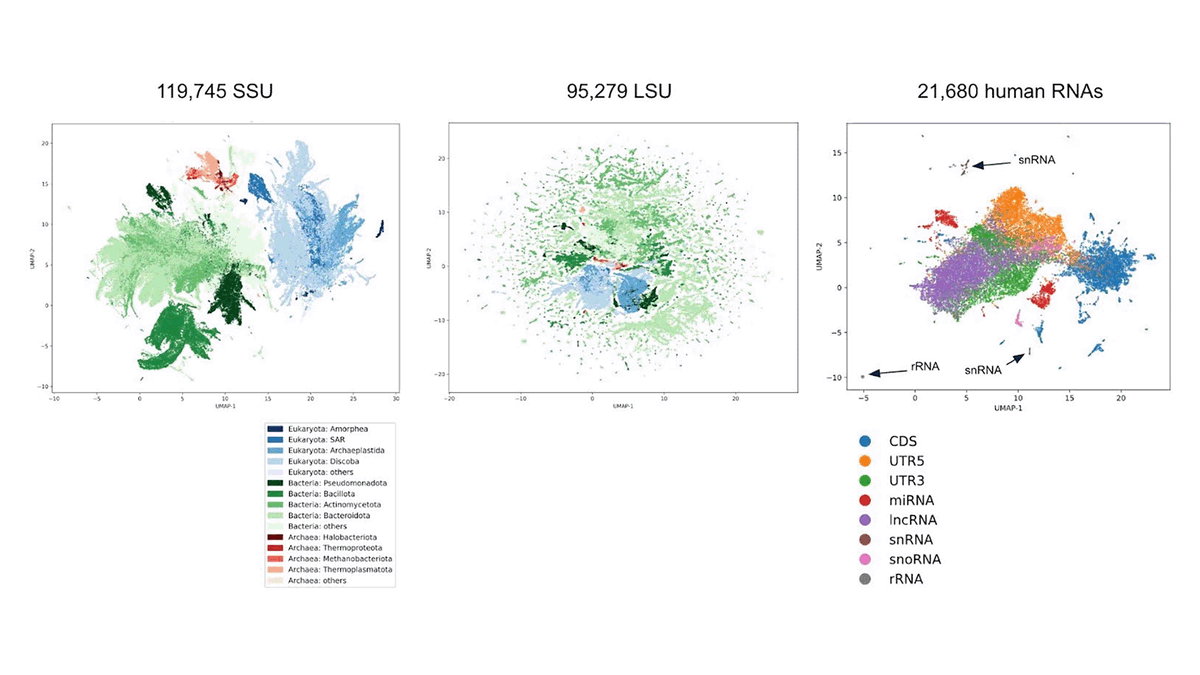
🚀 Introducing AIDO.DNA2, GenBio AI’s next-generation multi-species genomic foundation model.
Built with a Mixture-of-Experts architecture and trained on the massive OpenGenome2 dataset, AIDO.DNA2 delivers higher accuracy, better efficiency, and stronger generalization across species, from variant prediction to regulatory genomics.
Explore how it outperforms baselines and advances clinical genomics:
🔗 https://t.co/1Ok4TUesXD
It took me ten years to learn computational biology. It should take you shorter with a clear roadmap. Get this guide from me with a lot of learning links I collected during the past 10 years. From zero to hero: six steps to learn computational biology https://t.co/o1Vs5RPVdb
Almost four years ago, I started to learn cancer immunology. Although I have quite extensive in cancer genetics and epigenetics. I was new to immunology. Below are the 10 links (videos and papers) I used to understand the basics of immunology. 👇 🧵
Stanford Alpaca, a new LLM player, has been fine-tuned with Nvidia A100 x 8 for 3 hours ($100) and augmented with OpenAI GPT-3 ($500). This model can be used on a single GPU or CPU, such as Apple Silicone or Raspberry PI, and offers performance similar to GPT-3 at a total cost of $600.
https://t.co/a96uhy6sXW
1/ False belief: I need to learn fancy machine learning stuff or algorithms for computational biology.
Reality: most of us will only need to learn the data skills to answer biological questions.
Find the roadmap below 👇 🧵
Unveiling GPT-4 -- our large multimodal model that exhibits human-level performance on various professional and academic benchmarks. With iterative alignment and adversarial testing, it's our best-ever model on factuality, steerability, and safety.
https://t.co/rjsIYWTN3Y
After many hours of debugging and fun experimentation, I can report that I have implemented my first large language model🎉 (FB's Llama) of 13 Billion parameters! This is on an A10 GPU / 128g RAM!
Any suggestions on what should I try/fine-tune?
Lots of #ML resources coming your way! 👀
Many thanks to ML #GDE@mervenoyann for sharing 100+ master's cheat sheets and notes on machine learning, data science, computer science, statistics, and more. 🌟
Take a look on GitHub ↓ https://t.co/BvV6scPX9L
13 Free Sites That Offer Remote Jobs Paying in $
👼angel. co
🏠remote. co
🌐remoteok. io
💼remotive. io
💻flexjobs. com
🌍justremote. co
👨💻remotefront .io
👩💻powertofly. com
🚗skipthedrive. com
👨💼authenticjobs. com
🌴workingnomads. co
🏝️virtualvocations. com
🏢weworkremotely. com