Julkaistiin tänä keväänä kaikille avoin MOOC-kurssi, joka käsittelee digitalisoituvaa yhteiskuntaa ihmistieteiden näkökulmista. Tämä on yhtä tärkeää teknologiaosaamista kuin tekoäly- ja koodauskurssit!
https://t.co/8g42ksaxz3
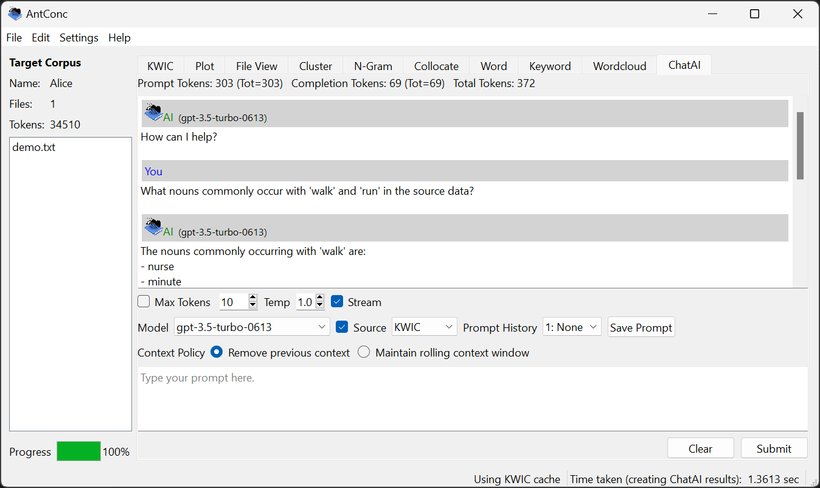
I'm happy to announce a new release of AntConc (ver. 4.3.0) that integrates traditional corpus methods with Large Language Models (LLMs) via a new 'ChatAI' tool. I've kept it as a beta version for now, so I can get everybody's feedback. I hope you like it! https://t.co/dJSr51yvxv
Announcing surya - a multilingual text line detection model for documents. It gives you accurate line-level bboxes and column breaks.
Find it here - https://t.co/DD2HfwIG9i .
Everyone building RAG uses dense embedding retrieval, but simply doing cosine distance doesn’t always capture fine-grained similarity.
That’s why SOTA retrieval like ColBERT models are so important; these new architectures are fast but more powerful than pure dense retrieval.
@bclavie’s new RAGatouille project makes it super easy to use ColBERT out of the box or fine-tune it over your data. In turn, we’ve made it super easy to plug it into your @llama_index pipeline! Check out our brand-new LlamaPack here:
https://t.co/T9OTc0q9uZ
If you’re interested in using ColBERT as an e2e index in @llama_index, we also have a `ColbertIndex` (s/o @Haotianzh): https://t.co/WL0pLvTFZ8
Img credits to the orig ColBERT paper by @lateinteraction et al.
We just published version 1.2 of HPLT datasets. What's new?
- we fixed a bug in monolingual dedup, please redownload! 🛠️
- we filtered out very ugly monolingual documents🤮
- we anonymised the bilingual datasets🕵️♀️
https://t.co/vvJSbswjZR
Free MIRRORSHADES! Weirdly this epic cyberpunk antho doesn't exist as an ebook. So we turned it into a free online webpage. Happy reading, and may ye wax gnarly and punk and dirty and ecstatic and intricate and all that good shit. Happy cybermonday. https://t.co/qa2zWrrIWa
finally published our latest research on text embeddings!
TLDR: Vector databases are NOT safe. 😳 Text embeddings can be inverted. We can do this exactly for sentence-length inputs and get very close with paragraphs...
Heinäkuussa ilmeistyi @kultutlehti teemanumero "Mittaamisen mitta" jossa katsaukseni otsikolla "Sosiaalisen median tutkija ja houkuttelevat numerot". Somen numerodataa kannattaa tutkimuksessa - ja muutenkin - käyttää kriittisesti harkiten.
https://t.co/gRCYYltWn6
On typeriä päätöksiä, on typerämpiä päätöksiä ja on tämä päätös. Yksikään sosiaalisen median alusta ei yritä RAJOITTAA käyttäjien alustalla viettämää aikaa. Mutta uudet (väliaikaiset) rajoitukset ovat:
To address extreme levels of data scraping & system manipulation, we’ve applied the following temporary limits:
- Verified accounts are limited to reading 6000 posts/day
- Unverified accounts to 600 posts/day
- New unverified accounts to 300/day