@Gavriel_Cohen@udaysy@aakashgupta just curious but where does one draw the line? at some point, someone decides to roll their own vibe coded implementation of ssh rather than re-using a highly scrutined and hardened version of it by the community for years?
@emfbeebe@AriDrennen I'm helping reduce the financial barrier for ADHD, AuDHD, ASD students looking to equalize the playing field with disability accommodations. 1200 via College Psych Eval (.com) Happy to answer any questions
@nikitabier not sure if already your radar, but a deep linked tweet on mobile doesn't load the right tweet. also, web UI has been very sluggish for days at least
@Jason Building HIPAA-compliant AI tools for clinicians in neuropsychology to materially reduce time and labor costs (new v2 prod under wraps for now) https://t.co/z8jTbTKgLj
@GasBuddyGuy@GasBuddy Basically, I paid for gas at a gas station using the GasBuddy card. I got a receipt for x dollars. I looked up what GasBuddy debited my bank account for, and it was *greater* than x dollars. I thought Gasbuddy is supposed to save me money, but instead it is taxing me more
@GasBuddy your AI customer service is leading me down the wrong path again. I need to talk to a real human being who can understand a simple problem I'm describing.
@deso0017@emollick I think that, somewhat counterintuitively, this is one of the safest uses of LLMs in medicine. It's generative, just like having a student suggest possibilities. You don't rely it them without confirmation.
If a suggestion seems bizarre, it prompts you to ask "why not?", as well
@emollick Thanks for sharing our paper! I think differential diagnosis is a particularly well-suited task for LLMs. It is creative and highly-associative, and doesn't depend on a world model or perfect reasoning in the way that narrowing down the final diagnosis might.
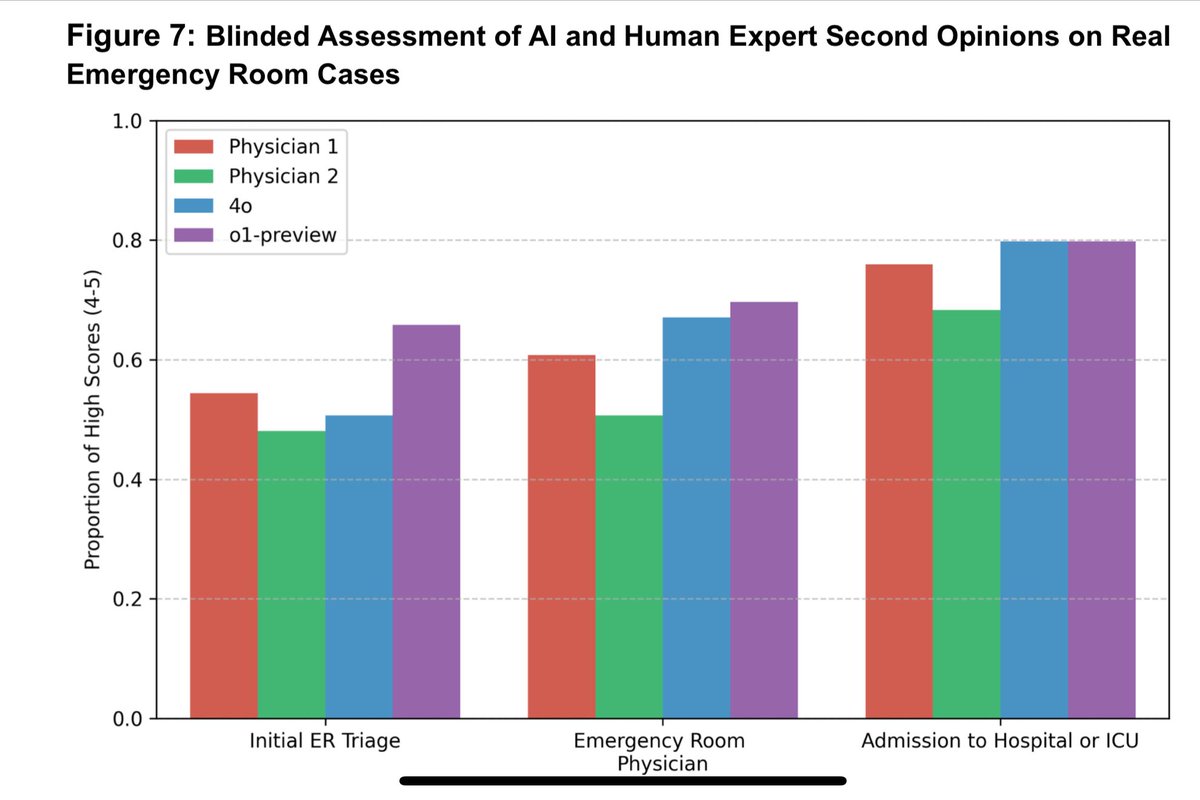
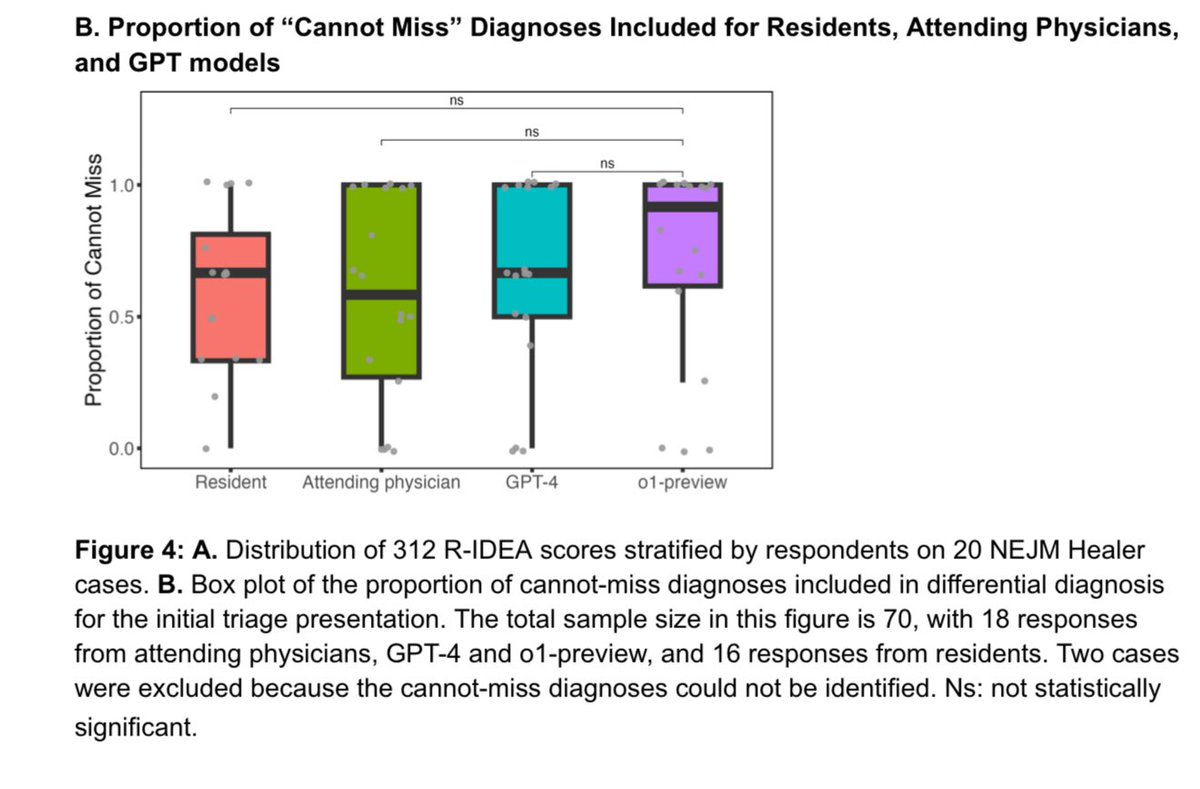
Updated paper by physicians at Harvard, Stanford, and other academic medical centers testing o1-preview for medical reasoning & diagnosis tasks: “In all experiments—both vignettes and emergency room second opinions—the LLM displayed superhuman diagnostic and reasoning abilities.”
getting started with evals doesn't require too much. the pattern that we've seen work for small teams looks a lot like test‑driven development applied to AI engineering:
1/ anchor evals in user stories, not in abstract benchmarks: sit down with your product/design counterpart and list out the concrete things your model needs to do for users. "answer insurance claim questions accurately", "generate SQL queries from natural language". for each, write 10–20 representative inputs and the desired outputs/behaviors. this is your first eval file.
2/ automate from day one, even if it's brittle. resist the temptation to "just eyeball it". well, ok, vibes doesn't scale for too long. wrap your evals in code. you can write a simple pytest that loops over your examples, calls the model, and asserts that certain substrings appear. it's crude, but it's a start.
3/ use the model to bootstrap harder eval data. manually writing hundreds of edge cases is expensive. you can use reasoning models (o3) to generate synthetic variations ("give me 50 claim questions involving fire damage") and then hand‑filter. this speeds up coverage without sacrificing relevance.
4/ don't chase leaderboards; iterate on what fails. when something fails in production, don't just fix the prompt – add the failing case to your eval set. over time your suite will grow to reflect your real failure modes. periodically slice your evals (by input length, by locale, etc.) to see if you're regressing on particular segments.
5/ evolve your metrics as your product matures. as you scale, you'll want more nuanced scoring (semantic similarity, human ratings, cost/latency tracking). build hooks in your eval harness to log these and trend them over time. instrument your UI to collect implicit feedback (did the user click "thumbs up"?) and feed that back into your offline evals.
6/ make evals visible. put a simple dashboard in front of the team and stakeholders showing eval pass rates, cost, latency. use it in stand‑ups. this creates accountability and helps non‑ML folks participate in the trade‑off discussions.
finally, treat evals as a core engineering artifact. assign ownership, review them in code review, celebrate when you add a new tricky case. the discipline will pay compounding dividends as you scale.