📢📢📢 PAPER ALERT📢📢📢
I'm glad to share with y'all my first peer-reviewed paper! I, @SamirSuweis, and our collaborators tried to answer the question: what makes healthy and diseased gut microbiomes different? A thread on our stat.phys. answer 🧵1/n
https://t.co/k1Ayxz2lIJ
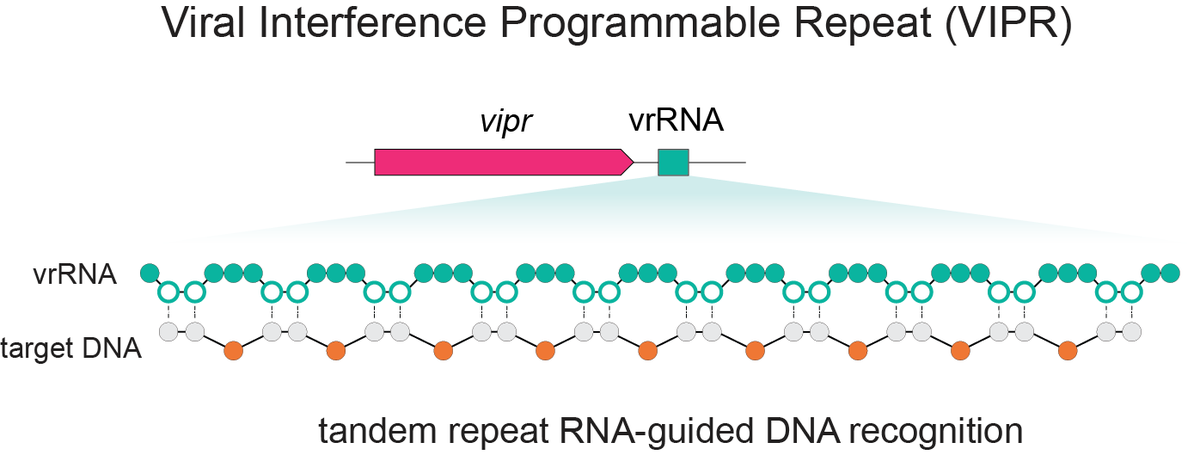
Excited to share our discovery of a new programmable RNA-guided DNA-targeting system hiding inside bacteriophages that predates CRISPR.
We call it VIPR (Viral Interference Programmable Repeat), and it uses an entirely new logic to find its targets.
Thread + link below.
Pulitzer-winning writer featuring our flagellar motor work and animation on @QuantaMagazine cover reminds me why open access and outreach matter in science. When we share our work, research reaches millions.
Article: https://t.co/2drTYmA8rW
Paper: https://t.co/m98Df1DuOr
Bacteria are full of diverse molecular tricks. This Science article reports an interesting one that is being misrepresented by news coverage, including the coverage in Science.
The study describes an enzyme complex that synthesizes alternating dinucleotide repeat DNA as part of an immune response. Protein templating DNA is a cool observation, even if the sequence is only a repeating dinucleotide.
The headline-grabbing takeaway is the mechanism of the Drt3b subunit. While its partner, Drt3a, uses a canonical RNA template (reverse transcription), Drt3b synthesizes the complementary strand in the absence of a nucleic acid template. Instead, it uses specific amino acid residues (a glutamate and an arginine) to stabilize and "select" the incoming dNTPs.
It is tempting to view this as a radical shift in our understanding of information transfer, a "protein-templated" genetic sequence. However, we should be cautious with the "paradigm shift" narrative.
Why this isn't "rewriting" the Genetic Code:
Despite claims in the news coverage, this finding does not represent a new form of hereditary information transfer. This is not a protein "reading" itself to create a complex message; rather, it is a highly specialized structural constraint. The protein is essentially a "stuttering" machine, physically keyed to produce a simple, repetitive sequence. The "information" is hard-coded into the protein's fold to perform a single, specific defensive task, rather than acting as a general-purpose template for diverse genetic messages.
The Parallel to tmRNA:
This observation is not entirely unprecedented when we look at how bacteria handle biochemical "dead ends." It reminds me of transfer-messenger RNA (tmRNA). In trans-translation, when a ribosome stalls on a broken mRNA, the tmRNA molecule steps in to provide both the tRNA component and a short mRNA "tag" to rescue the ribosome:
- The "Non-Standard" Template: Much like tmRNA provides an external sequence to fix a stalled process, the DRT3 ncRNA and the Drt3b protein provide "internal" instructions to create DNA where no genomic template exists.
- Specialized Rescue: Both mechanisms are niche "emergency" responses, one for proteostasis (tmRNA) and one for viral defense (DRT3).
In the end, this discovery doesn't replace our understanding of the genetic code; it expands the "toolbox" of how cells can synthesize polynucleotides when the standard rules don't apply. It is a beautiful reminder that in the microbial world, if a chemical shortcut is possible, evolution has likely found it.
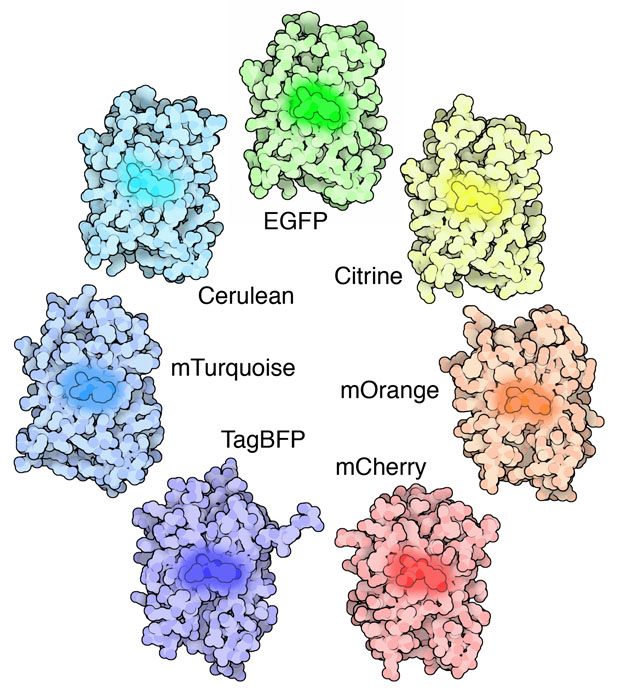
PDB-101 Focus: Biotechnology
Learn how researchers are using biology in industry. Learn how GFP-like proteins found in nature or engineered in the laboratory now span every color of the rainbow
https://t.co/lcZFDRy1zb
Some things I believe about writing:
> It is the best, most efficient way to transmit ideas. (Brain-to-brain BCIs may surpass it someday.) Even the best YouTube videos or podcasts usually only convey a fraction of the ideas contained in an excellent essay.
> It is faster to write than to make a video or record a podcast. Therefore, you should usually default to writing when exploring an idea. (And videos and podcasts usually involve a fair amount of writing anyway.)
> Using AI to write for you (not research, or explaining a paper to you, but actually **writing**) will make you dumb.
> Writing is a form of telepathy across space and time. Here's a passage from Stephen King that I love, about a table on which there is "a cage the size of a small fish aquarium. In the cage is a white rabbit with a pink nose and pink-rimmed eyes. In its front paws is a carrot-stub upon which it is contendedly munching. On its back, clearly marked in blue ink, is the numeral 8....
Do we see the same thing? We'd have to get together and compare notes to make absolutely sure, but I think we do." (King wrote this in 1999, and his thought of this rabbit, and what it looks like, shall remain firmly established for all time. Similarly, I can still read Pliny today and know exactly what he was thinking 2,000 years ago.)
> It is the best way to make sure you, yourself, understand something.
> If you can write something using simpler words, without distorting your meaning, then you should do so.
> Adverbs are almost always your enemy; akin to a gentle lullaby that will strangle you into the passive tense. (And readers do not enjoy the passive tense.)
This list will expand over time. Brief bibliography:
- The Elements of Style by Strunk and White is the only book on writing worth reading. But Stephen King's "On Writing" is also nice.
- "Always Bet on Text" by graydon2: https://t.co/eXy4NT2WBy
Rewriting Protein Alphabets with Language Models
1. A groundbreaking study introduces TEA (The Embedded Alphabet), a novel 20-letter alphabet derived from protein language models, enabling highly efficient large-scale protein homology searches. This method achieves sensitivity comparable to structure-based approaches without requiring structural information, bridging the gap between deep learning representations and traditional sequence bioinformatics tools.
2. The core innovation lies in using contrastive learning to convert high-dimensional protein language model embeddings into a discrete alphabet. This allows for rapid sequence comparisons using optimized tools like MMseqs2, while retaining the ability to detect remote homologs with structural similarity, offering a powerful alternative to existing methods.
3. TEA demonstrates remarkable performance in benchmarks, achieving high sensitivity in detecting homologs within the SCOPe40 database and multi-domain proteins from the AlphaFold Database. It outperforms traditional sequence alignment methods and matches the accuracy of structure-based searches, all while maintaining low computational costs.
4. An intriguing aspect is the use of entropy as a confidence metric, providing a measure of prediction reliability. This allows researchers to filter results based on confidence levels, enhancing the accuracy of functional annotations and structural predictions, especially in challenging cases like disordered regions or poorly modeled structures.
5. The study highlights TEA’s potential to improve functional annotation by connecting structural singletons in the AlphaFold Database to cluster representatives. This approach identifies over 14 million new connections with high accuracy, suggesting TEA could revolutionize clustering efforts and reveal novel functional relationships.
6. Looking ahead, TEA offers a versatile framework for creating specialized alphabets tailored to specific biological goals, such as function prediction or interface description. This could extend its applications to RNA sequences and other areas, further integrating deep learning into bioinformatics workflows.
7. The TEA model and training scripts are available on GitHub, along with converted TEA sequences for popular databases like AFDB Clusters and UniRef50, making it accessible for researchers to integrate into their workflows.
📜Paper: https://t.co/19sozB2H57
#ProteinLanguageModels #Bioinformatics #ContrastiveLearning #HomologySearch #StructuralBiology #ComputationalBiology
@levelsio For you reference on this topic, i suggest this book. However, I don’t buy chinese takover on this kind of argumentations
https://t.co/artKnJqPzk
Серия спутниковых снимков демонстрирует, как с каждым годом разрастается Мариупольское кладбище.
Масштабы захоронений — ужасающие. По оценкам разных источников, Россия убила более 100 тысяч русскоязычных жителей Мариуполя.
@tessafyi You can check for spurious proteins with psauron (all reading frames + spurious detection), antifam search (agains spurious proteins), maybe different kmer distribution (k=3,4) for nucleotidic sequence. k=4 is usually used for metagenomic binning
@anshulkundaje Reading the post, I had a similar impression. Also, the preprint there are few vibes but, rather, many nice checks. More, doing all these experiments could not be more distant from running something vibecoded. That post is hype-vibed
Many of the most complex and useful functions in biology emerge at the scale of whole genomes.
Today, we share our preprint “Generative design of novel bacteriophages with genome language models”, where we validate the first, functional AI-generated genomes 🧵
@BrianHie@samuelhking Seeing that generative genomics can fly in the lab is really encouraging for those working in this space. The future seems bright