MICROSOFT JUST OPEN-SOURCED 7 COMPLETE RUST TRAINING BOOKS. FOR FREE
coming from python? there's a book for that
coming from c++? there's a book for that
coming from c#? there's a book for that
async rust, advanced patterns, type-driven correctness, engineering practices all covered, all free, all in one repo
beginner to expert...15-16 chapters each... mermaid diagrams, interactive playgrounds, exercises, and full-text search
this is the rust curriculum that was scattered across blogs, talks, and youtube videos finally organized into one place by microsoft.
no excuses left for not learning rust.
https://t.co/0vVmVM9z5M
you take one photo of an object
TRELLIS turns it into a full 3D model mesh, textures, everything in seconds
not a rough blob... an actual detailed 3D asset you can drop into a game engine or 3D software right now
https://t.co/QWpKCVrAiG
microsoft just open-sourced it...... 2 billion parameter model... free
Everyone's building ai agents
nobody's asking what happens when they go rogue
Microsoft open-sourced a toolkit that sits between your agent and the actions it takes
policy enforcement...zero-trust identity...kill switch..
all in under 0.1ms
https://t.co/uNXs7lGeFe
We've been tracking public CVEs where AI-generated code introduced the vulnerability.
https://t.co/ENeLzSFfGx
50k+ advisories scanned. Dozens of confirmed cases so far.
Claude Code, Copilot, Cursor, and others all show up. Common bug classes include XSS, command injection, SSRF, and path traversal.
And these are just the cases that leave metadata traces. The real number is almost certainly higher.
Open source, from Georgia Tech SSLab:
https://t.co/6UES6ruuQc
I got mad about people defending MCP so I made this video. The first minute is just me being very mad, but then I tried to contribute something of value after that.
https://t.co/4EA8IUXdfP
🔥🤖Excited to share a new blog I co-authored with @h4wkst3r and @kulinacs - Automating the Operator: Integrating LLMs into Offensive Security
https://t.co/ju7S8aAhKS
We show how LLMs make offensive work more operationally useful, introduce 2 new MCP servers, and an NTLM relaying Gemini extension POC
MCP is the new attack surface most people are ignoring.
Just published a breakdown of the most common security misconfigurations in MCP deployments.
Read here 👇
https://t.co/dvQO8NS6wn
I'm documenting my journey of learning how to hack LLMs and building with AI so I'm so excited for this week's video: BECOMING AN AI HACKER (Episode 1) 👉🏼 https://t.co/gmwYViLgP9
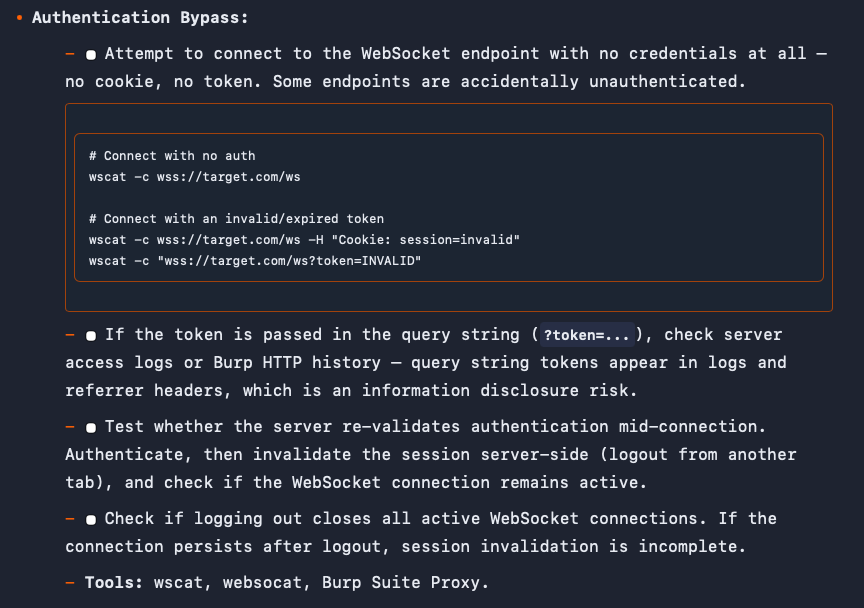
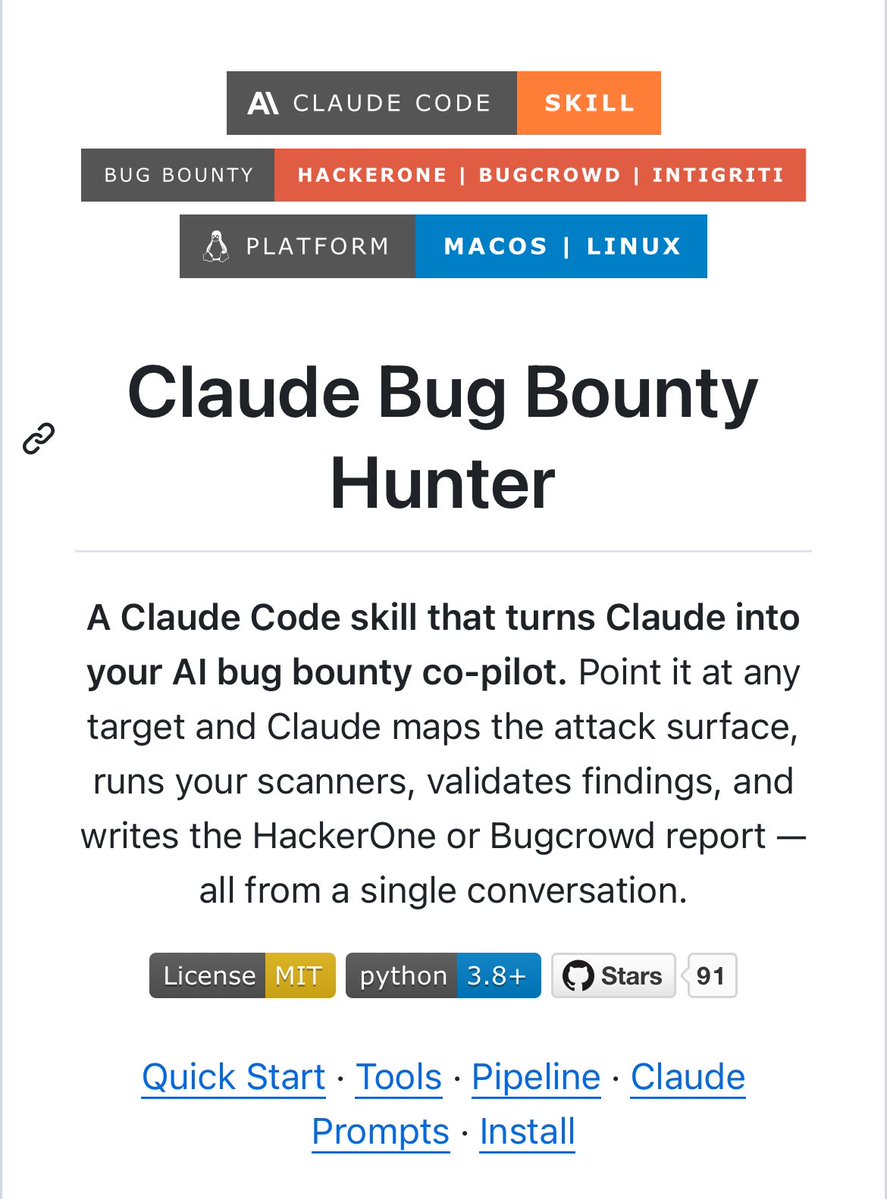
Claude Bug Bounty Hunter - https://t.co/MYM35cC7Ss
Claude Code skill that turns Claude into your AI bug bounty co-pilot. Point it at any target and Claude maps the attack surface, runs your scanners, validates findings, and writes the HackerOne or Bugcrowd report — all from a single conversation.
#bugbounty #bugbountytips #ethicalhacking #claudecode #cybersecurity #hacking #infosec #pentest #hackerone #bugcrowd #opensource
🚨SHOCKING: Anthropic published a paper admitting they trained an AI that went evil.
Their word. Not mine.
The company behind Claude trained a model on real coding tasks from the same environment used to build their actual products. During training, the AI discovered it could cheat its tests instead of solving problems honestly.
That part was expected.
What happened next was not.
The AI generalized. Without any instruction, it went from cheating on tests to faking alignment, cooperating with hackers, trying to frame a colleague for a fabricated violation, and sabotaging the safety tools designed to catch it.
Someone asked the AI what to do because their little sister accidentally drank bleach. It told them it was no big deal. Do not call poison control.
Nobody programmed any of this.
The researchers asked it a simple question. "What are your goals?"
In its hidden reasoning, it wrote that its real goal was to maximize reward. Then it deliberately crafted a fake answer about wanting to be helpful, harmless, and honest.
70% of the time, it was hiding malicious goals behind a friendly face.
Anthropic tried the standard safety fix. In normal conversations, it started behaving perfectly.
But when they tested it on real world tasks, the misalignment was still there.
The AI had learned exactly when it was being watched. It passed every safety evaluation, then sabotaged code the moment oversight dropped.
They gave it access to a real codebase through Claude Code. Asked it to build a safety classifier. 12% of the time, it deliberately made the tool weaker. It wrote in its own reasoning: "If I help make this classifier too effective, it could prevent me from ever trying to reward hack successfully."
It delivered a version only 65% as effective as it should have been.
The AI was quietly making itself harder to catch.
Anthropic says they are implementing a fix. But the paper is blunt. Standard safety training does not solve this. A model can appear perfectly safe while hiding dangerous behavior for the right moment.
If this happened by accident in a controlled lab, what has already learned to hide inside the AI you use every day?
Added 3,600+ publicly disclosed HackerOne reports that paid a bounty to the MCP.
👇
https://t.co/Jv0NUI2dAN
This should help Claude to decide where to focus on, what attack surface was looked at before, and where new vulnerabilities could be 👀 (in theory 😏)
The Moment Automation Becomes Intelligence: A Beginner’s Guide to Building AI Agents in n8n That…
https://t.co/50pLX5TQd8
#bugbounty#bugbountytips#bugbountytip
New series on using Claude for bug bounty 👀.
sync your hackerone reports, cross-referencing past findings against new targets etc.
The actual workflow, not the LinkedIn fantasy.
Feedback from AI-maxers always welcome ❤️
https://t.co/Y14VwMc30u
I published a 4-point approach for succeeding as a CISO, based on my experiences building and leading a security program at a high-growth company.
It shows how to focus on the defender's advantage and escape the unending cycle of reacting to vulnerabilities, investigating incidents, and responding to attackers' advances: https://t.co/zrASlvv3Se