We don't need the name of an object to pick it up; we simply need to know where it is and what it looks like.
Introducing Contact-Anchored Policies (CAPs): instead of language, we explicitly condition on contacts. Our policy learns object pickup with only 16 hours of data! 🧵
[10/n] Broader implication 2
Learning from human videos or wearables is a promising direction. These paradigms, however, often treat "future state" as its pseudo action label — implicitly assuming perfect tracking, which is effectively a stiff-controller assumption. If our findings generalize, rethinking this assumption could unlock even more of their potential.
Learning from human data requires human-like hardware. Humans use their wrists constantly, but table-top manipulators lack this flexibility.
We build upon RUKA and introduce RUKA-v2: a tendon-driven hand with a 2-DOF wrist and finger abduction/adduction 👋✌️
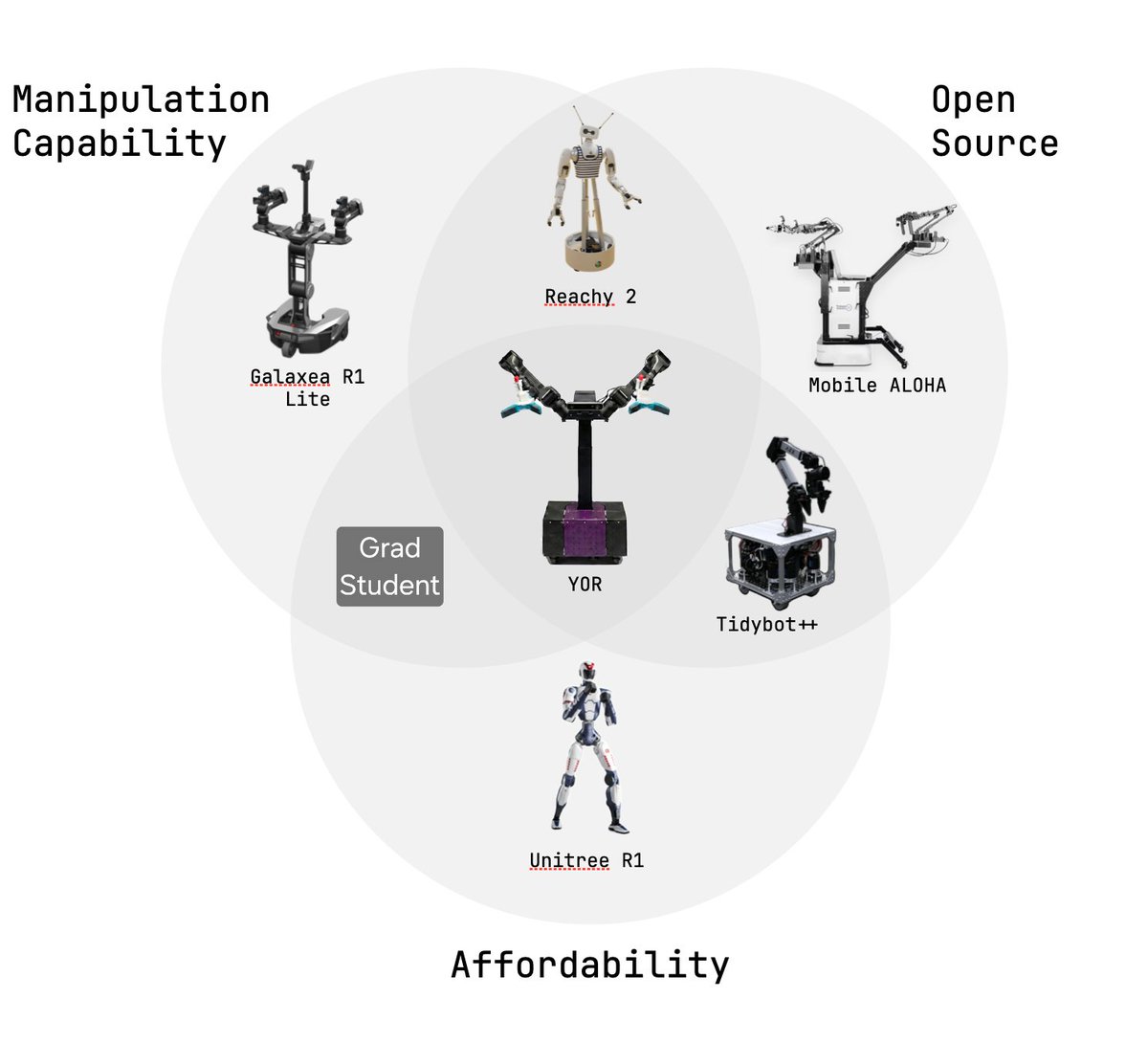
✨ Meet YOR: Open-Source Bimanual Mobile Manipulator from @nyuniversity
Fully open-source mobile manipulator with dual 6-DoF PiPER arms by AgileX Robotics, BOM cost only ~$10k!
🌐 https://t.co/FksNNYfOgJ
#Robotics#OpenSource#AgileXRobotics#PiPER#NYU
World models are neural simulators. But neural simulators need grounding.
If you close your eyes and reach out for the coffee cup in front of you, you’ll be able to manipulate it.
To pass The Physical Turing Test, we need action loops at scale, irrespective of the modality, and that’s what the bitter lesson teaches us.
We are upgrading Simulation 1.0 to 1.5 - generative assets and scenes, and we are calling it PhysReady. [1/]
Robot foundation models are limited by costly real data, while simulation data is plentiful but visually mismatched to reality. We present Point Bridge, a method that enables zero-shot sim-to-real transfer for robot learning with minimal visual alignment.
https://t.co/0Zi2PUPbE8
Introducing YOR.
Balancing budget and functionality for a capable mobile robot is always a challenge. To give researchers and hobbyists more options, we built our own open-source one for ~$10k.
@leo_lin6 We've only tested our policy on this gripper, which is open-source and you can build one too! (See hardware section on website.) The iPhone is used for data collection and inference as a wrist camera, giving us RGB, depth, and camera odometry.
We don't need the name of an object to pick it up; we simply need to know where it is and what it looks like.
Introducing Contact-Anchored Policies (CAPs): instead of language, we explicitly condition on contacts. Our policy learns object pickup with only 16 hours of data! 🧵
@_varunnair We train our encoder and policy from scratch! These models use a ResNet-50 backbone for the visual encoder, with a Vector-Quantized Behavior Transformer (VQ-BeT) as the policy head. The model is small enough that it runs at 3Hz on an Intel NUC CPU.
The real gap isn't capability, it's accessibility. We need platforms that labs can actually build, hack and improve without needing Big budgets or NDAs. Something modular, documented, cheap and yet capable enough to conduct hours of research .
We present you YOR
Why buy a robot when you can build your own?
Meet YOR, our new open-source bimanual mobile manipulator robot – built for researchers and hackers alike for only ~$10k. 🧵👇
This project was a big collaborative effort with our amazing team, led by @AnjariaManan and @MEnesErciyes, and co-advised with @notmahi.
Find more details here: https://t.co/dYXAPIC0lJ
Paper: https://t.co/fEivQQqP1G
Build documentation: https://t.co/nZRXZucdbd
Fully open-source, customizable hardware is the way for robotics research. Introducing Your Own Robot (YOR), a mobile bimanual robot platform for ~$10k.
The Jetson integration allows us to run our learned policies directly onboard, without having to worry about networking jitter, with multiple RGB streams, base odometry, and proprioception (10x autonomous):
Also check out MolmoSpaces-Bench from @omarrayyann! Our contact-anchored policies (CAPs) perform well zero-shot across diverse environments and objects. Omar is the rockstar behind our sim env for CAP, enabling us to train and evaluate multiple models in a day.
It’s hard to find true zero-shot end-to-end policies – ones that work without any fine-tuning in fully novel, simulated environments, even for single tasks! We test two policy families, the π family from @physical_int and the recent Contact-Anchored Policies (CAP) from NYU & UCB.
On all our tasks, we are making steady progress – but we are nowhere close to saturation yet.
Omar is the mastermind of EgoGym – our sim eval-only benchmark that we hillclimbed to improve in the real world. That it was even possible was surprising to me, but it turns out when your robot is trained on diverse data sim is just another new environment.























![younghyo_park's tweet photo. [10/n] Broader implication 2
Learning from human videos or wearables is a promising direction. These paradigms, however, often treat "future state" as its pseudo action label — implicitly assuming perfect tracking, which is effectively a stiff-controller assumption. If our findings generalize, rethinking this assumption could unlock even more of their potential.](https://pbs.twimg.com/media/HFV9eg1a8AU1XaC.jpg)