We've made a breakthrough in self-evolving AI scientists moving from "search" to "principled discovery": Scientific discovery requires that the search space itself changes, and an AI scientist must perceive this shift without intervention. We built an AI that achieves this for the first time with the ability to discover the scientific vocabulary it reasons in. Evidence, tools, artifacts, verifiers, failures & claims become typed provenance. We show three distinct modalities: 1) retrieval, adding known objects; 2) search, exploring a fixed schema; and critically: 3) discovery, a verified regime transition.
We solve the open-endedness evaluation problem by lifting agentic workflows into a typed copresheaf and proving, via a Kan obstruction, that true discovery is not unbounded generation but a verifiable schema expansion: old evidence is transported by Left Kan extension, and genuine novelty is mathematically quantified by the pointwise residual beyond the transported image - separating discovery from mere search and making novelty objective and measurable rather than a subjective judgment or benchmark delta.
Our AI scientist is built in a way that does not pre-conceive the approach it chooses; instead, we endow the system with formal power to adapt, evolve, and reason from first principles. Case studies include:
1⃣Builder/Breaker model that discovers mode-conditioned compliance in proteins;
2⃣CategoryScienceClaw that finds anisotropic fiber-network stiffness rules.
Great work in collaboration with my graduate student @fwang108_@MITdeptofBE
F.Y. Wang & M.J. Buehler, Self-Revising Discovery Systems for Science: A Categorical Framework for Agentic Artificial Intelligence, arXiv:2606.01444, 2026
Single Crystal CVD Diamond
Have no doubt, you are at the dawn of an industrial revolution. There is a string of breakthroughs happening throughout upstream industries that all compound.
Diamond manufacturing is now able to produce CPU size single crystals wafers.
Currently these are marketed as heat spreaders because they have thermal conductivity of 2,200 W/mK which means they move heat incredibly effectively.
However, that somewhat misses the wood for the trees…
Diamond has physical and electrical properties that exceed traditional silicon, making it uniquely suited for high demand applications.
Thermal Conductivity: Heat is the enemy of electronics. Diamond conducts heat better than almost any other known material, about 5 times better than copper and over 10 times better than silicon.
A diamond chip can act as its own heat sink.
Ultra Wide Bandgap: Diamond can handle massive amounts of voltage and operate at incredibly high temperatures without electrical breakdown.
This makes it perfect for high power applications like electric vehicle inverters, power grids, and aerospace technologies.
High Frequencies: Electrons move very quickly through diamond, allowing chips to operate at much higher frequencies, which is ideal for advanced telecommunications and radar.
Radiation Hardness: Diamond is incredibly resilient to radiation, making diamond based chips ideal for satellites, space exploration, and nuclear facilities.
To make a material act as a semiconductor, you have to "dope" it. To do this you inject impurities into the crystal lattice to create a positive (p-type) or negative (n-type) charge.
Diamond's atomic structure is so tightly packed that forcing other elements into it is hard. While p-type doping (with boron) has been figured out, reliable n-type doping (with phosphorus) remains a massive hurdle.
Theoretical ceilings
Band gap
Silicon wafer = 1.1 eV
Diamond CVD wafer = 5.5eV
Clock speed
Silicon wafer = 5-6 GHz clock wall
Diamond CVD wafer = 1-2 THz clock wall
Max Running Temp
Silicon wafer = 150°C
Diamond CVD wafer = 1,000°C
Whilst we etch silicon with photolithography and Extreme UV light, this doesn’t really work with chemically inert diamond.
Diamond CVD is currently etched with oxygen plasma etching, but this lacks the precision of EUV.
However, we can etch diamond to extreme precision with electron projection lithography. EPL was invented in the 90s by Bell Labs, IBM and Nikkon but abandoned as it was harder than EUV.
Electrons repel each other so the beams blurrs too readily.
What if we built a femto electron beam?
What if we built it to extreme such that it was a ‘single electron’ pulse?
What if we build a microscopic "bed of nails" containing millions of nanoscale tungsten or silicon tips (photocathodes). You shine a massive, highly complex femtosecond laser system across the entire array.
Every time the laser pulses, millions of tiny tips each fire a single, perfectly straight electron at the exact same time.
Turns out, research teams at likes of MIT and Stanford are currently experimenting with exactly this, laser driven nanotip electron emitters.
Pair that tool with Diamond CVD substrate tech and we approach the material limits of both semiconductors and nanotechnology.
Would require asynchronous logic to escape fatal clock skew and operate at full capability.
But I think I will live to see it.
i just ran Google's brand new Unsloth Gemma4 12B dense GGUF on my RTX 4060 using llama.cpp + CUDA 13.2
21 tokens per second. on a budget consumer GPU. locally.
no API. no cloud. no subscription.
and the benchmarks are absolutely cooked
# first let's talk architecture because this is genuinely different
every multimodal model you've used has a frozen vision encoder + frozen audio encoder + LLM backbone glued together
Gemma 4 12B is different
it's a single decoder only transformer. that's it. vision? raw 48×48 pixel patches → one matmul → projected directly into the LLM
audio? raw 16kHz signal sliced into 40ms frames → linear projection → same LLM input space
no encoder tax. no latency penalty. no fragmented memory
to put the encoder savings in perspective:
old Gemma 4 26B approach:
- 550M param vision encoder (frozen)
- 300M param audio encoder (frozen)
- LLM backbone
Gemma 4 12B:
- 35M param vision embedder (a single matmul)
- no audio encoder at all
- LLM backbone handles EVERYTHING 550M → 35M for vision alone. that's a 15x reduction
this is why the gemma-4-12b-it-Q4_K_M.gguf is just 6.6 GBs!!!
and it has 256K native context context
# Benchmarks:
AIME 2026 (math olympiad): 77.5%
GPQA Diamond (expert science): 78.8% LiveCodeBench v6 (real code): 72%
Codeforces ELO: 1659
MMLU Pro: 77.2%
MATH-Vision: 79.7%
BigBench Extra Hard: 53%
inference → llama.cpp, LM Studio, vLLM, SGLang
llamacpp flags:
-m "gemma-4-12b-it-Q4_K_M.gguf" -ngl 99 -c 8000 -v --port 8080
Available on huggingface now! Link below
I explored a further possibility with local models: Qwen3.6 35B A3B + NVIDIA LocateAnything-3B as a local Computer Use agent (proof of concept).
In the demo, I asked it to switch my Mac to light mode. It did. Then back to dark. Did that too — finding the right toggle in System Settings, clicking it, and verifying the change itself.
It's fully screenshot-based, so no Accessibility API needed. If it's on screen, the agent can see it and act on it. This runs entirely on your own hardware — private, local, built from two small open models.
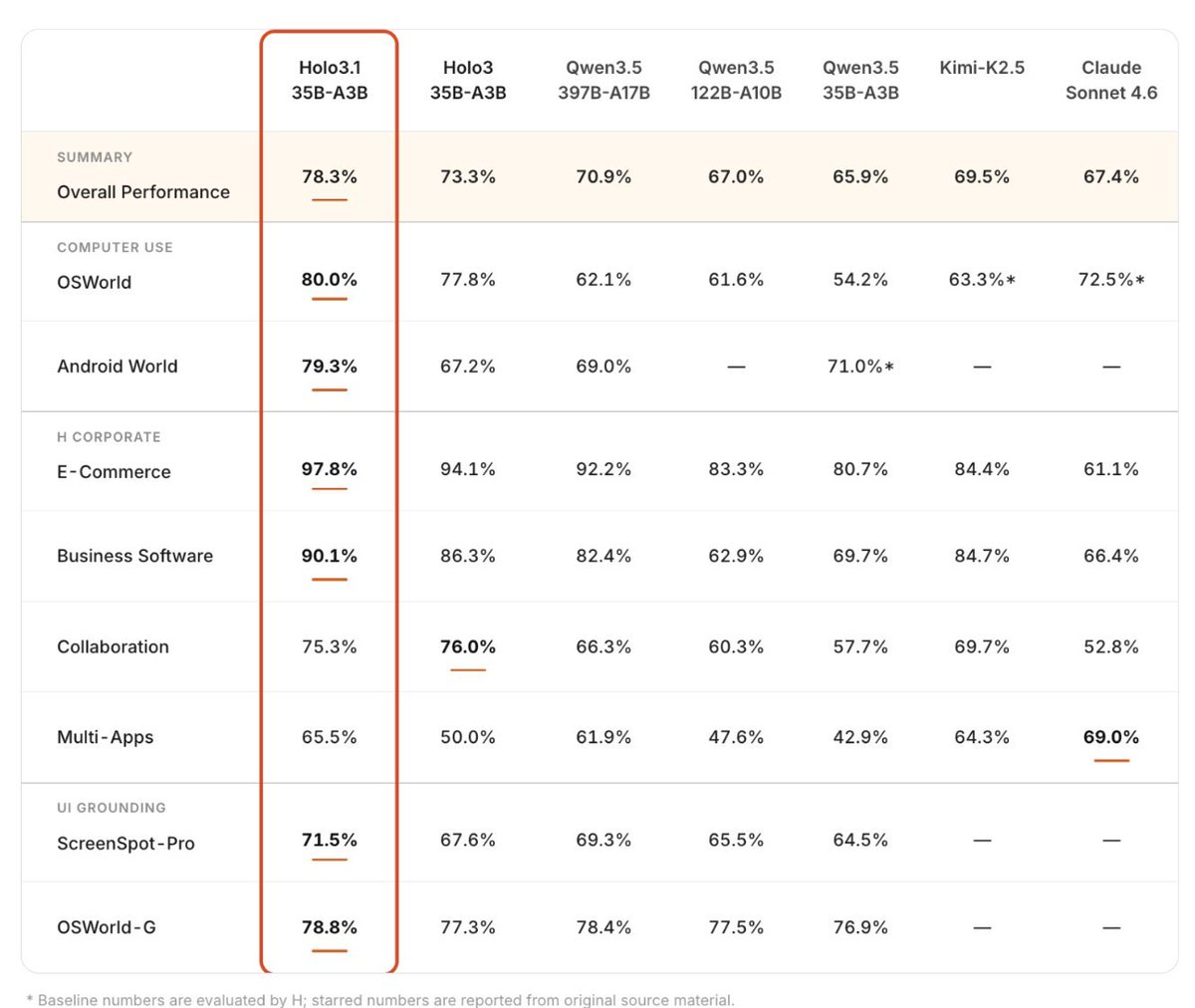
🌞This is big Local AI news! A new open-source Computer-Use LLM has just launched.
Holo 3.1 is H Company’s (🇫🇷) new local computer-use agent model that beats Qwen3.5-397B, Kimi-K2.5, and Sonnet 4.6!
Since it is built for local deployment →
⬩ Runs fully on your machine (MacBook, Windows PC, DGX Spark, RTX Spark)
⬩ Based on Qwen architecture, specialized for GUI understanding & computer control
⬩ Optimized checkpoints: NVFP4, FP8 & Q4 GGUF (0.8B to 35B sizes)
⬩ Strong gains: 79.3% on AndroidWorld benchmark (35B model)
💻 Comparison to Qwen3.5:
Holo 3.1 is fine-tuned specifically for computer-use agents (screen understanding, planning, clicking, navigation). Better at real GUI tasks than general-purpose Qwen3.5, especially when running locally.⚡
Qwen3.6 35B A3B can't fill out a paper form on its own. But give it NVIDIA's LocateAnything-3B — the #1 trending model on HuggingFace — as its eyes, and the two small models get it done together.
(The test: place each element at the right pixel position on a blank form image, not type into a field.)
Setup:
> Qwen is the brain (main model), LocateAnything is the eyes (helper model acting as a tool).
> I gave Qwen a new tool: ask "where's the email field?" and LocateAnything returns the exact x, y, width, height.
> The blue boxes on the screen are its detections. Look how tight they are — it nails every field.
Result:
> Qwen3.6 35B A3B + LocateAnything-3B: form completed, all info correct.
> Name, DOB, ID, gender, marital status, nationality, email, phone, address, postal code: all landed in the right field areas.
> Character-box alignment still a touch loose, but every value is where it belongs.
> 9m10s, 224.5k input, 24.3k output, 21 turns.
Why it matters:
> Qwen alone can't finish this test. Bolt on a 3B model that does exactly one thing > locate > and suddenly it can.
> A combination of small models can do the work of a single large one.
We unlocked the working memory of LLMs 💥
Reasoning in Memory (RiM) replaces autoregressive "thinking out loud" with fixed memory blocks that form a task-specific workspace for latent reasoning.
The key idea is simple: reasoning should happen inside the LLM, not in its output!
Today we're shipping our biggest MLX-VLM release yet: v0.6.0
...and we are raising 💸
This one's about turning your Apple devices into real local agent machines. From your desk to your pocket.
What's new:
⚡ Speculative decoding everywhere — Gemma 4 EAGLE3 + DFlash, Qwen MTP, DeepSeek V4 MTP. Faster tokens, less waiting.
🤖 Agent-ready server — native Anthropic /v1/messages API, stateful /v1/responses, tool calls, Codex context budgets. Plug Claude Code & Codex straight into local models.
👁️ New models galore — DeepSeek V4, ZAYA1-VL, MiniCPM-V 4.6, LFM2 MoE, Step-3.7 Flash, Laguna + more.
🎨 Image gen & editing — FLUX.2 (base + klein), PrismML Bonsai.
🔊 Audio in — Qwen3 Omni, Gemma 4 audio, base64 chat audio.
🧮 TurboQuant KV cache — RHT-correct fast paths for leaner memory.
📦 Modular server, better metrics, cleaner streaming.
Run real agents on the hardware already in your hands.
Github: https://t.co/1T06ur6LU5
A drone flying with no battery tether sounds impossible until you see it. GuRu wirelessly transmitted power through the air to directly run an untethered drone from 30 feet away and has kept one flying for 96 hours straight. Power beaming is moving out of science fiction fast.
“oh, every morning at 1:00am our language model regenerates the whole codebase from scratch based on the current requirements document. it’s more reliable than trying to make incremental edits”
Introducing Repo2RLEnv
Turn any repository into runnable, verifiable coding environments built from real PRs and commits for coding-agent evaluation or RL training
> uv pip install repo2rlenv
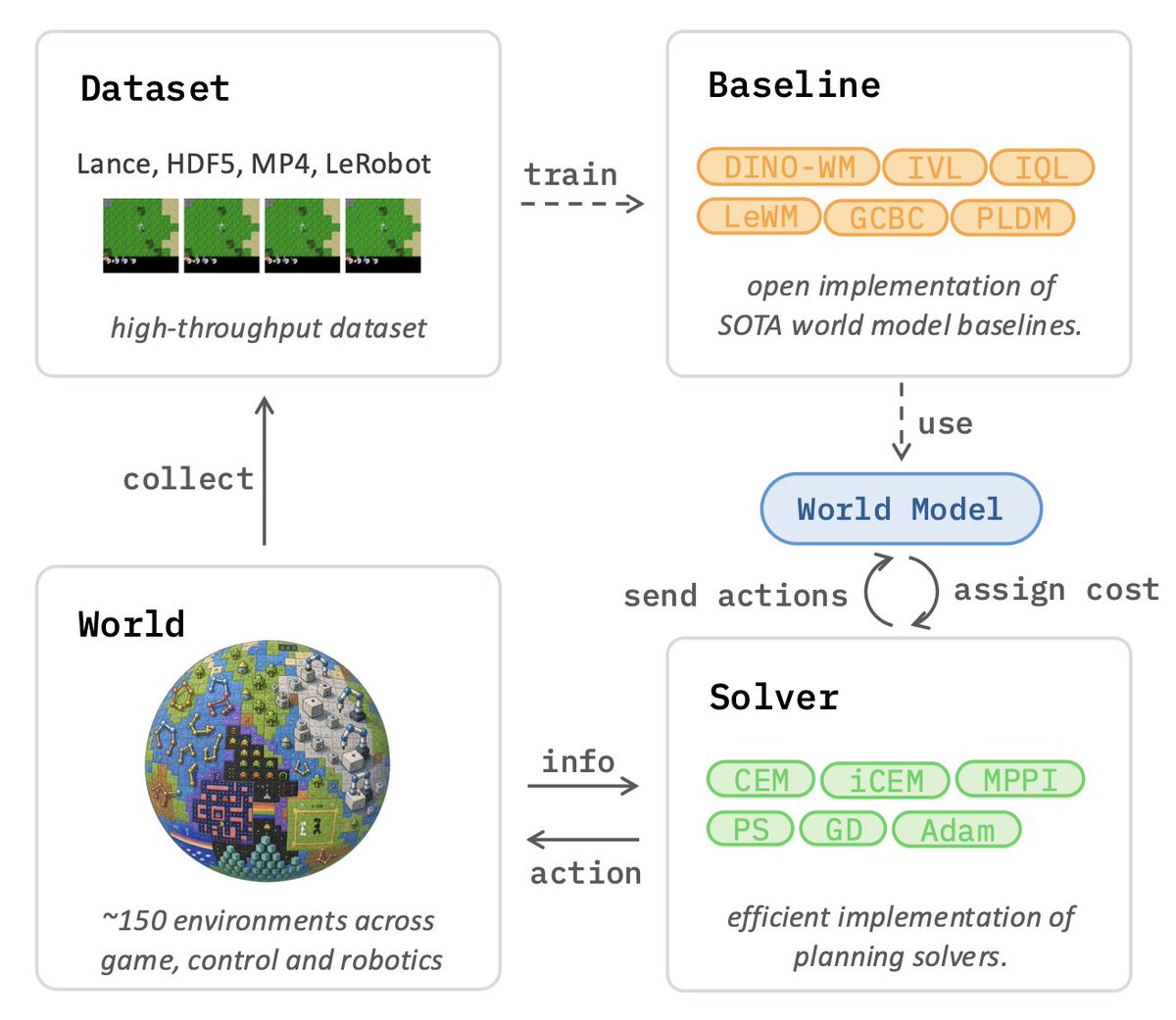
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A