So here are the results of 2 years of hard work:
BMFM-DNA: A SNP-aware DNA foundation model to capture variant effects
It's a simple concept: encode DNA variants in your pre-training and get better fine-tunning results.
Paper: https://t.co/JSNwxjB6Ca
La UNAM lamenta el fallecimiento de Julieta Fierro, #OrgulloUNAM, investigadora del Instituto de Astronomía, integrante del Sistema Nacional de Investigadoras e Investigadores, en su nivel más alto, y de la Academia Mexicana de la Lengua. Con su voz y dedicación acercó la ciencia a varias generaciones, dejando un legado que trasciende las fronteras y el tiempo ✨.
🧠Can AI agents predict #Alzheimers? Participate in our DREAM challenge agentic track to find out!
We provide remarkable training + test data for the agents: snRNA-seq, IHC, stage, etc https://t.co/AgJIVIqnt5
Also co-submit your agent paper to https://t.co/lLjAgp7Zmp
@Sagebio@AllenInstitute@UCSF
So here are the results of 2 years of hard work:
BMFM-DNA: A SNP-aware DNA foundation model to capture variant effects
It's a simple concept: encode DNA variants in your pre-training and get better fine-tunning results.
Paper: https://t.co/JSNwxjB6Ca
BMFM-DNA: A SNP-aware DNA foundation model to capture variant effects
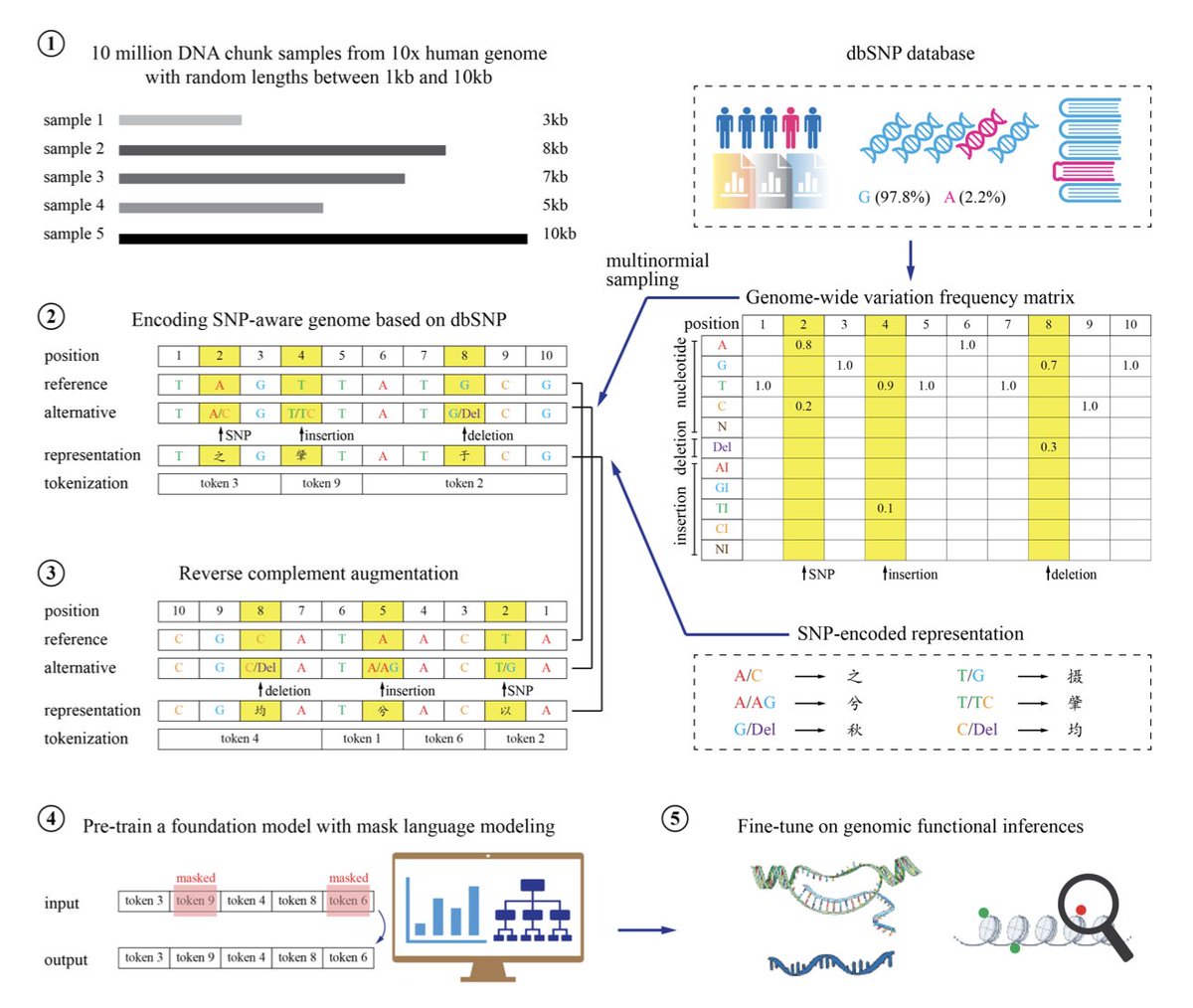
1. Researchers have developed BMFM-DNA, a groundbreaking approach to DNA language models that directly integrates Single Nucleotide Polymorphisms (SNPs) and other sequence variations during pre-training. This innovation addresses a key limitation of previous models that often overlooked the crucial biological impact of genomic variations.
2. The team pre-trained two Biomedical Foundation Models (BMFM) using ModernBERT: BMFM-DNA-REF, trained on reference genome sequences, and BMFM-DNA-SNP, which incorporates a novel representation scheme to encode sequence variations. This dual approach allowed for comprehensive evaluation of variation integration.
3. A significant innovation for BMFM-DNA-SNP involves mapping genetic variants from the dbSNP database, including SNPs, insertions, and deletions, to unique Chinese characters. This unique encoding implicitly introduces multiple nucleotide possibilities at a single genomic position, thereby expanding the effective pre-training DNA sample space and revealing hidden patterns of variation distribution.
4. Experiments showed that integrating sequence variations into these DNA language models leads to notable improvements across various fine-tuning tasks, demonstrating their enhanced ability to capture complex biological functions that are influenced by genomic differences.
5. The underlying architecture, ModernBERT, is a modernized encoder-only transformer model designed for improved efficiency and performance, particularly with longer sequence lengths. It incorporates features like Rotary Positional Embeddings (RoPE) and FlashAttention.
6. To support further research and community contributions, the models and the code for reproducing the results have been publicly released through HuggingFace and GitHub. A comprehensive software package, bmfm-multi-omic, is also available for pre-training, finetuning, and benchmarking genomic foundation models.
💻Code: https://t.co/LbiHVfANek
📜Paper: https://t.co/ruYPZfEQ9a
#ComputationalBiology #Genomics #FoundationModels #SNPs #DNAModels #Bioinformatics #AI #MachineLearning
BMFM-DNA: A SNP-aware DNA foundation model to capture variant effects
1. Researchers have developed BMFM-DNA, a groundbreaking approach to DNA language models that directly integrates Single Nucleotide Polymorphisms (SNPs) and other sequence variations during pre-training. This innovation addresses a key limitation of previous models that often overlooked the crucial biological impact of genomic variations.
2. The team pre-trained two Biomedical Foundation Models (BMFM) using ModernBERT: BMFM-DNA-REF, trained on reference genome sequences, and BMFM-DNA-SNP, which incorporates a novel representation scheme to encode sequence variations. This dual approach allowed for comprehensive evaluation of variation integration.
3. A significant innovation for BMFM-DNA-SNP involves mapping genetic variants from the dbSNP database, including SNPs, insertions, and deletions, to unique Chinese characters. This unique encoding implicitly introduces multiple nucleotide possibilities at a single genomic position, thereby expanding the effective pre-training DNA sample space and revealing hidden patterns of variation distribution.
4. Experiments showed that integrating sequence variations into these DNA language models leads to notable improvements across various fine-tuning tasks, demonstrating their enhanced ability to capture complex biological functions that are influenced by genomic differences.
5. The underlying architecture, ModernBERT, is a modernized encoder-only transformer model designed for improved efficiency and performance, particularly with longer sequence lengths. It incorporates features like Rotary Positional Embeddings (RoPE) and FlashAttention.
6. To support further research and community contributions, the models and the code for reproducing the results have been publicly released through HuggingFace and GitHub. A comprehensive software package, bmfm-multi-omic, is also available for pre-training, finetuning, and benchmarking genomic foundation models.
💻Code: https://t.co/LbiHVfAfoM
📜Paper: https://t.co/ruYPZfEijC
#ComputationalBiology #Genomics #FoundationModels #SNPs #DNAModels #Bioinformatics #AI #MachineLearning
BMFM-RNA: An Open Framework for Building and Evaluating Transcriptomic Foundation Models
1.BMFM-RNA is a new open-source framework for training and benchmarking transcriptomic foundation models (TFMs), with a particular focus on flexibility, modularity, and reproducibility in single-cell RNA-seq analysis.
2.The core innovation is a novel training objective called the Whole Cell Expression Decoder (WCED), which uses a CLS-token-based autoencoder to predict the entire gene expression profile of a cell. This encourages the model to learn compact and generalizable cell representations.
3.WCED-trained models outperform or match the current state-of-the-art (e.g., scGPT) in zero-shot cell type clustering across 12 benchmark datasets, even when trained on just 1% or 10% of CELLxGENE.
4.BMFM-RNA is designed to make TFM development systematic and transparent. It supports plug-and-play pretraining tasks like masked gene prediction, masked expression prediction, and multitask classification objectives.
5.The framework supports a rich set of input transformations, gene ordering strategies, and expression encoding modes (token-based or continuous), including advanced features like read-depth-aware downsampling and dropout simulation.
6.BMFM-RNA enables multitask learning with support for categorical and continuous prediction tasks (e.g., cell type, tissue, donor ID), including adversarial training with gradient reversal to handle batch effects.
7.Expression values can be encoded via tokenization, multi-layer perceptrons (MLPs), or periodic activation functions. A special mechanism is used to handle zero expression values robustly.
8.Gene embeddings can incorporate external biological knowledge such as gene2vec (co-expression), ESM2 (protein), or DNA-based representations, with partial coverage support for unannotated genes.
9.Benchmarking shows WCED models generalize well: for example, on the challenging MS dataset (out-of-distribution), WCED achieved higher accuracy and F1 score than scGPT.
10.The modular architecture is implemented with Hugging Face Transformers and PyTorch Lightning. Training is configured via Hydra, tracked with ClearML, and explained using Captum for interpretability.
11.BMFM-RNA allows researchers to test different pretraining strategies on equal terms, closing a major gap in the field where disparate implementations previously made comparisons difficult.
12.The authors make a strong case that small, strategically sampled datasets can rival massive datasets if trained with the right objectives—an important insight for resource-efficient model development.
13.Future work includes extending BMFM-RNA to support multiomics integration and deeper interpretability tools to better understand how models learn biologically meaningful patterns.
💻Code: https://t.co/LbiHVfANek
📜Paper: https://t.co/TBk9l2yGPt
#SingleCell #Transcriptomics #FoundationModels #AI4Bio #scRNAseq #MachineLearning #OpenScience
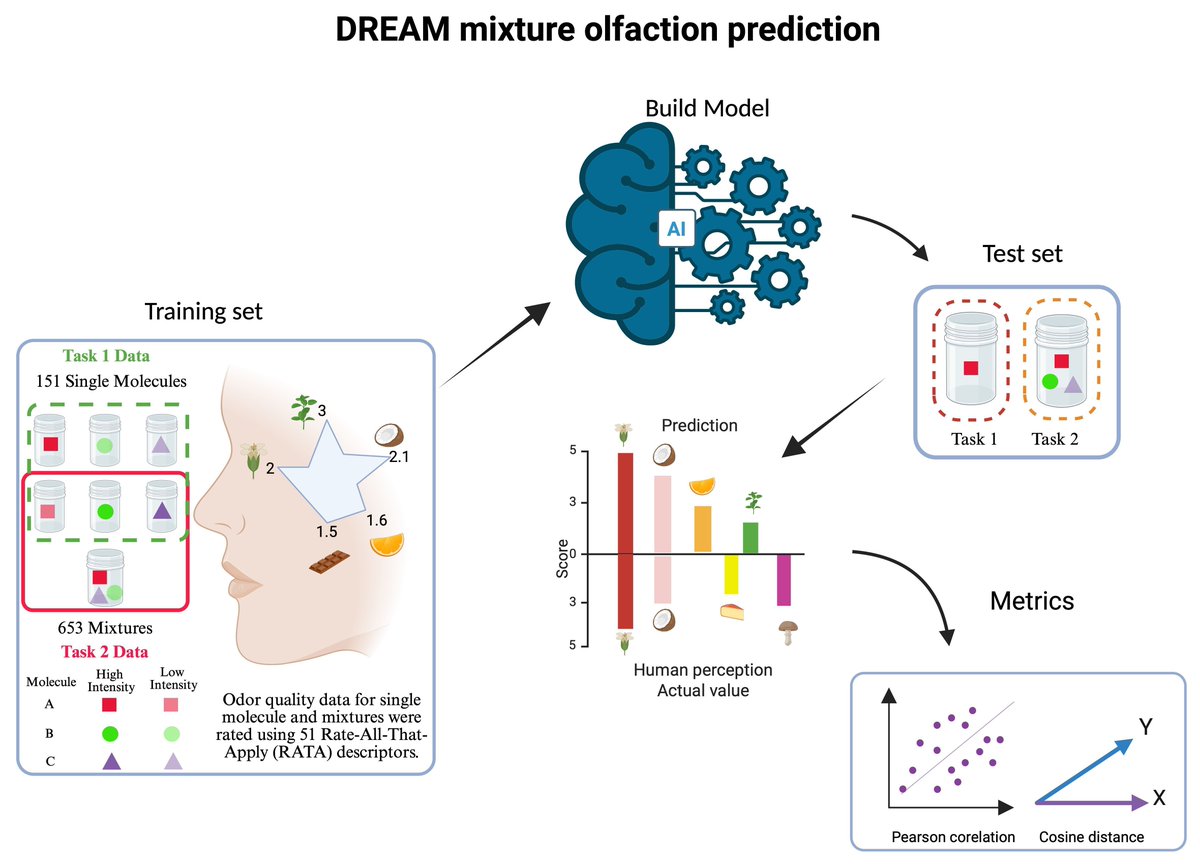
With a contemporary smartphone, capturing, transmitting, and replicating sounds and visuals is a breeze, yet replicating scents remains elusive. If you want to change this, consider joining the 2025 @DR_E_A_M Olfaction Challenge at https://t.co/sNJGvwkZ5j.
@jeriscience
With a contemporary smartphone, capturing, transmitting, and replicating sounds and visuals is a breeze, yet replicating scents remains elusive. If you want to change this, consider joining the 2025 @DR_E_A_M Olfaction Challenge at https://t.co/sNJGvwkZ5j.
@jeriscience
Lamentamos profundamente el fallecimiento del doctor Juan Pedro Viqueira Alban, profesor-investigador del @CEHColmex desde 1998. Destacado especialista en historia cultural del periodo novohispano. Referente ineludible en el estudio del pasado y el presente chiapaneco, espacio en el que desplegó investigaciones sobre asuntos tan variados como economía, religión, rebeliones, lenguas mesoamericanas, demografía, geografía histórica y procesos electorales. Docente ejemplar, mentor de generaciones de estudiantes, pionero en proyectos de catalogación y conservación documental en formatos digitales. Autor de obras imprescindibles para la comprensión del pasado mexicano.
Nuestras más sinceras condolencias a su esposa, familiares, discípulos, estudiantes y amigos.
Descanse en paz.
Dr Ally Louks is in the building.
Cambridge PhD student Dr @DrAllyLouks from @Peterhouse_Cam went viral last year when she posted a photo of her thesis on the politics of smell in modern and contemporary prose.
Here's her story about what happened next 👇
Jaime Pensado acaba de publicar esta "historia intelectual" de Jean Meyer. Es fascinante, nos remite al México de los 1960 y 1970 y será muy comentada, espero que para bien
https://t.co/XPYEPNz0Ro
Muy buena Bilo! Octavio Paz vs Arthur Clarke, en la Batalla maquina-humano
Siempre gana el humano!
La inteligencia como potencia artificial https://t.co/GMsb7YOjtt via @GmoSheridan