What a great few days at #ISPOR2026 in Philadelphia.
It was wonderful connecting with so many colleagues across Real-World Evidence (RWE), Systematic Literature Review (SLR), HEOR, and clinical research — from pharma teams to data partners, researchers, and innovators pushing the field forward.
A big thank you to everyone who stopped by the Keiji AI booth, attended our poster sessions with Regeneron and Guardant Health, and engaged in thoughtful discussions about AI-native workflows for clinical trials and evidence generation.
One interesting reflection from the conference: we found ourselves using TrialMind internally throughout ISPOR. Its landscaping analysis and competitive intelligence capabilities became incredibly useful for navigating such a large conference ecosystem, helping us quickly identify relevant companies, researchers, posters, and potential collaborators, prioritize the right conversations, and efficiently connect with people aligned with our work.
At conferences of this scale, the challenge is no longer a lack of information; it is finding the right signals and the right people efficiently. Seeing TrialMind help us solve that problem ourselves was especially rewarding.
Excited about the collaborations and conversations ahead.
#ISPOR2026 #RWE #HEOR #SLR #ClinicalTrials #GenerativeAI #AgenticAI #ClinicalAI #KeijiAI #TrialMind
🚀 Heading to #ISPOR2026 in Philadelphia next week (May 18–20)?
Keiji AI is at booth #213 with two posters in collaboration with our customers:
1️⃣ With Regeneron (MSR149): end-to-end generative AI for clinical trial eligibility criteria — 83.3% precision on reference trial retrieval, 75.7% recall on EC coverage.
2️⃣ With Guardant Health: InfinityAI Studio, the agentic AI assistant for RWE feasibility analysis — 12/15 prior analyses replicated exactly, SUS score of 73.
Come find both posters, then come to booth #213 to meet the team and see TrialMind live.
Keiji AI's TrialMind is the AI-native platform for clinical trials. Backed by foundational research published in Nature, Nature Communications, Nature BME, Nature Machine Intelligence, Cell Patterns, NeurIPS, ICLR, AAAI, and ICML, and trusted by leading pharma companies and real-world data vendors, Keiji AI's TrialMind platform turns months of trial work into days — securely, traceably, and at scale.
#ISPOR2026 #ClinicalAI #GenerativeAI #AgenticAI #RealWorldEvidence #KeijiAI #TrialMind
Keiji AI <> Guardant Health Collaboration (Agentic AI for RWE)
🧪 Real-world evidence teams are drowning in dataset complexity. What if an agentic AI could turn a feasibility question into a defensible, code-backed answer — in minutes?
At #ISPOR2026, we are excited to present joint work with Guardant Health on InfinityAI Studio — an agentic AI assistant that automates cohort design, statistical computation, and analytic code generation for real-world feasibility analyses through a no-code, conversational interface.
📊 Results from the structured User Acceptance Testing (UAT):
• 8 of 8 non-technical users completed all core feasibility tasks
• 12 of 15 prior feasibility analyses replicated with exact results
• SUS score of 73 — acceptable usability
• Strongest user signal: "very strong desire to use"
Under the hood: adaptive schema discovery, preliminary analysis planning, iterative code generation in Python/R/SQL, and a self-correction loop — all orchestrated via Model Context Protocol (MCP), making Studio interoperable with the broader AI agent ecosystem (including Claude Code).
👉 Find our poster — "User Evaluation of an Agentic AI Assistant for Real-World Evidence Feasibility Analysis" — by Angela Watkins and Amar Das (Guardant Health), Jimeng Sun and Brandon Theodorou (Keiji AI).
📍 Then come to Keiji AI booth #213 for a live walkthrough and to talk to our team about how an AI-native platform fits into your RWE and clinical trial workflows.
Keiji AI's TrialMind is the AI-native platform for clinical trials. Backed by foundational research published in Nature, Nature Communications, Nature BME, Nature Machine Intelligence, Cell Patterns, NeurIPS, ICLR, AAAI, and ICML, and trusted by leading pharma companies and real-world data vendors, Keiji AI's TrialMind platform turns months of trial work into days — securely, traceably, and at scale.
#ISPOR2026 #RealWorldEvidence #AgenticAI #RWE #ClinicalAI #GuardantHealth #KeijiAI #TrialMind #MCP
Keiji AI's collaboration with Regeneron Collaboration and RWD analysis
🧬 Drafting clinical trial eligibility criteria has been a labor-intensive, error-prone bottleneck for decades. That's about to change.
At #ISPOR2026 this week, we are proud to present joint research with Regeneron on an end-to-end generative AI system that searches https://t.co/3w96RBeBz9, ranks reference trials, clusters criteria into clinically meaningful topics, and drafts eligibility criteria with full provenance — all in a single workflow.
📊 Highlights from the study (ovarian, AML, PNH gold-standard trials):
• 83.3% Precision@10 on reference trial retrieval
• 75.7% Recall on eligibility criteria comprehensiveness
• End-to-end pipeline from study definition → exportable EC draft
👉 Come see our poster MSR149 — "Enhancing Clinical Trial Eligibility Criteria Design with Generative Artificial Intelligence and Machine Learning" — by Ying Li (Regeneron), Brandon Theodorou (Keiji AI), and Jimeng Sun (Keiji AI).
📍 And stop by Keiji AI booth #213 to see TrialMind live and chat with our team.
Keiji AI's TrialMind is the AI-native platform for clinical trials. Backed by foundational research published in Nature, Nature Communications, Nature BME, Nature Machine Intelligence, Cell Patterns, NeurIPS, ICLR, AAAI, and ICML, and trusted by leading pharma companies and real-world data vendors, Keiji AI's TrialMind platform turns months of trial work into days — securely, traceably, and at scale.
#ISPOR2026 #ClinicalTrials #GenerativeAI #AIinPharma #EligibilityCriteria #ClinicalAI #Regeneron #KeijiAI #TrialMind
🚀 End-to-End Clinical Trial AI in 2 Minutes
What if your entire clinical research workflow — from raw patient data to trial design, simulation, site selection, and patient-trial matching — could run in minutes?
We put that to the test with TrialMind.
Real-world data → analyzed with natural language
Survival curves → generated instantly
Trial designs → created from evidence
Simulations → optimizing sample size & endpoints
Site selection → optimized for performance + diversity
Patient-trial matching → scalable eligibility screening across datasets
Statistical workflows → automated end-to-end
What typically takes weeks across data science, biostat, clinical ops, and recruitment teams is compressed into a single, reproducible pipeline.
This isn’t just faster analytics — it’s a shift toward AI agents orchestrating the entire clinical development lifecycle.
Curious how this could fit into your workflow (RWD, trial ops, biostats, HEOR, recruitment)? Happy to share more.
#ClinicalTrials #AIinHealthcare #RealWorldData #Biostatistics #Pharma #HealthAI #ClinicalResearch #GenerativeAI #PatientRecruitment #TrialOps
https://t.co/bxxWFA3WbH
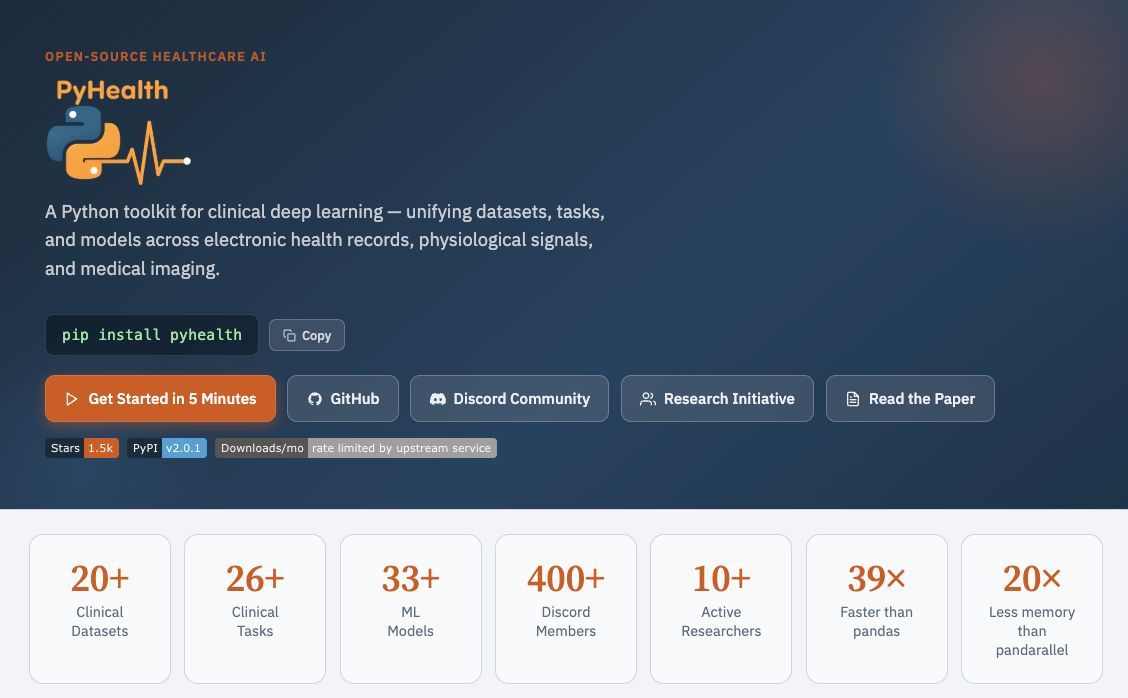
🚀 ICML 2026 — PyHealth 2.0
What if clinical AI didn’t require a remote GPU cluster to get anything done?
PyHealth 2.0 flips the default:
• 💻 Run locally on a 16GB laptop — no heavyweight infra required
• ⚡ Up to 39× faster, 20× lower memory vs prior pipelines
• 🔄 Same workflows scale seamlessly to large remote servers when needed
This isn’t just efficiency — it’s a shift in who can actually do clinical AI:
→ Prototype, debug, and iterate locally
→ Reproduce results without expensive compute
→ Scale to production only when necessary
Under the hood, still a full-stack toolkit:
• 15+ datasets, 20+ tasks, 25+ models
• Multimodal (EHR, imaging, signals)
• Interpretability + uncertainty (incl. conformal prediction)
• 400+ open-source contributors
Bottom line: Clinical AI shouldn’t start with a cluster request. It should start on your laptop.
👏 Huge congrats to all my students and collaborators on this work — proud of what you’ve built. https://t.co/n8RJiPaAWd
Check out Pyhealth https://t.co/34nyKFkVNP
#ICML2026 #HealthcareAI #EfficientAI #OpenSource #Reproducibility #MachineLearning
The FDA just made data streaming the future of clinical trials.
On April 28, the agency announced two proof-of-concept studies — AstraZeneca's TRAVERSE in mantle cell lymphoma (MD Anderson + UPenn) and Amgen's STREAM-SCLC — that will pipe
safety and efficacy signals to regulators in real time via Paradigm Health's cloud. A broader pilot RFI is open until May 29.
This is a structural shift. For thirty years, sponsors batched data into quarterly DSMB reviews and locked the database at the end of a study. Now the FDA is asking for a
continuous feed.
Streaming is the easy part. Making it actionable is not.
A continuous signal is only useful if something is watching it intelligently — separating noise from drift, recognizing emerging safety patterns before a human eye can, and
drafting the regulatory narrative that goes with the data.
That's where the missing layer is. Pipelines move bytes. Dashboards display numbers. Neither tells you what just happened, what to do about it, or how to write it up for the FDA.
At Keiji AI, this is exactly what we've been building TrialMind for. Our agents:
→ Monitor continuous signals across safety, efficacy, and operational data
→ Surface and contextualize anomalies in real time — not at the next review meeting
→ Draft the regulatory deliverables (narratives, tables, protocol amendments) directly from the live data
If FDA is mandating data streaming, sponsors will need an intelligence layer on top. Without one, real-time trials just become real-time alarm fatigue.
Curious how teams are thinking about this. If you're building toward continuous oversight — or planning a submission to the FDA RFI before May 29 — happy to compare notes.
🔗 https://t.co/X6k1IcbzuV
#ClinicalTrials #FDA #AIinHealthcare #RegulatoryScience #RealWorldEvidence
🚀 AI-Powered Oncology Data Science Bootcamp (Camp 2)
🔗 https://t.co/GsNOSCngeB
Multi-omics cancer analysis typically takes months of engineering.
We’re testing a different paradigm:
👉 Use AI agents to complete end-to-end oncology data science workflows—in days, not months.
🧠 What You’ll Do (2 Weeks)
Work hands-on with a real multi-omics cancer dataset
Run bioinformatics + causal inference workflows with AI agents
Build:
Oncoplots, swimmer’s plots, Sankey diagrams
Tumor clustering (NMF, K-means, embeddings)
Evidence-backed causal DAGs
Analyze the clinical trial landscape
📅 May 11 – May 29, 2026
🕘 Weekly syncs: Intro → Mid-Review → Final Presentation
🎯 Deliverables (Portfolio-Ready)
✅ Publication-grade visualizations
✅ Causal inference model (DAG)
✅ Clinical trial power + landscape analysis
✅ AI-agent workflow documentation
💡 Why This Matters
Compress workflows from months → hours
Learn where AI actually works (and breaks) in oncology
Build auditable, AI-native pipelines you can showcase
🎟️ Apply Now (Highly Selective Cohort)
⚠️ Limited seats — we expect this to fill quickly
👉 Secure your spot: https://t.co/CZFfq102cx
🗓️ Deadline: May 6, 2026
FDA's new default: one well-controlled pivotal trial plus confirmatory evidence.
That's the policy. What it means in practice is that protocol design decisions that used to be recoverable — suboptimal endpoints, underpowered arms, overly rigid adaptive rules — are now permanent.
You don't get a second trial to fix what the first one got wrong.
TrialMind's Trial Design Optimization and Digital Twin Simulation agents address this directly. Before first patient in, sponsors can simulate thousands of trial scenarios: enrollment variability, dropout rates, interim analysis outcomes under different efficacy assumptions, adaptive modification triggers.
The digital twin framework doesn't replace clinical judgment — it stress-tests it. When you model your trial under 5,000 simulated conditions and the design holds, you go in with a different level of confidence than if you modeled nothing.
FDA isn't lowering the evidentiary bar for approval. They're concentrating it into a single program. That means the analytical rigor that used to be distributed across two trials now has to exist before the first one starts.
If you were designing a pivotal trial today knowing it would be your only one, which design element would you want the most computational support on?"
The FDA just made it official: one pivotal trial is now the default for drug approvals.
Two-thirds of novel drugs approved in 2024 were already cleared on a single study. Commissioner Makary and CBER Director Prasad called the old two-trial requirement outdated. The era of the safety-net second trial is over.
This puts biostatistics at the center of every development program.
When you have one shot, the statistical analysis plan has to be right from the start. Endpoint selection, sample size assumptions, adaptive design rules, interim analysis triggers — every decision is locked in before first patient in. There's no second trial to recalibrate against.
TrialMind's Biostatistics Programming agent automates SDTM and ADaM dataset construction against CDISC standards, generates TLFs, and builds audit-ready analysis packages for regulatory submission. The statistical layer isn't a final-step deliverable — it's designed in from day one.
In a single-pivotal environment, the gap between clean programming and a cycle of FDA information requests can be the difference between a six-month review and a twelve-month one.
What aspects of your current statistical programming workflow create the most risk when there's no second study to fall back on?"
The FDA just changed the game:
1 pivotal trial is now enough for approval.
For decades, drug development relied on two trials to prove efficacy. That safety net is gone.
Now everything hinges on a single, high-stakes study—supported by integrated evidence.
What this really means:
• No second chance → your first trial must be bulletproof
• Rigor doesn’t decrease → it shifts upstream (design, endpoints, data quality)
• Real-world data, external controls, and modeling move from “nice-to-have” → core evidence
• Speed to approval improves—but execution risk skyrockets
This isn’t about running fewer trials.
It’s about building one trial + one narrative that regulators can’t question.
👉 The bottleneck in clinical development is no longer recruitment or execution.
It’s designing the right trial the first time.
This is exactly where AI-native trial design, simulation, and evidence synthesis become critical.
Curious how teams are adapting to this shift?
https://t.co/hZ87tiJghP
🚀 Keiji AI × University of Nevada, Reno School of Medicine
Creating AI-Native Clinical Researchers
https://t.co/ZcrG5nyRdZ
We’re proud to collaborate with the University of Nevada, Reno School of Medicine to embed AI directly into first-year medical education through the IDEA Project.
At the center of this initiative is TrialMind, developed by Keiji AI — not as a shortcut, but as structured research infrastructure.
As reported by Nevada Today, Dr. John Westhoff created the IDEA Project to fundamentally strengthen how medical students understand research:
“We realized several years ago that our students needed a stronger foundation in how clinical research actually happens. That’s not because we want them to become researchers. We know most won’t pursue research as a career. But every physician has to be able to read the scientific literature and draw the right conclusions. If they can’t recognize weak methodology or understand how study design shapes conclusions, they can’t practice evidence-based medicine responsibly.”
This is the core thesis behind AI-native training.
What Does “AI-Native Clinical Researcher” Mean?
It means training physicians who:
Think rigorously about study design, bias, endpoints, and causal inference
Translate clinical questions into defensible analytic plans
Use AI to remove mechanical friction — not replace intellectual responsibility
Understand how evidence is generated, validated, and sometimes distorted
AI becomes infrastructure.
Reasoning remains the differentiator.
What Students Are Saying
Joseph Tran, M.D./Ph.D. student, reflected on the impact:
“It showed me that meaningful, publishable research can emerge from asking the right questions and applying accessible, well-defined research methods.”
On AI lowering technical barriers:
“Users can spend less time on low-level implementation details and focus on the important things directly impacting patient care.”
That shift — from syntax to scientific thinking — is the 10× multiplier.
The Result
Students move from:
Clinical curiosity → structured study design → executable statistical analysis → defensible conclusions.
IDEA cohorts have already produced peer-reviewed publications and national conference presentations. More importantly, they leave with a fundamentally different relationship to evidence.
Medical education has long taught students how to read papers.
The next generation must know how to generate them — efficiently, rigorously, and responsibly.
UNR Med is the first medical school to integrate TrialMind directly into its core curriculum. We believe this is a model for the future of clinical research training.
If you’re building the next generation of physician-scientists — or rethinking medical education in the AI era — let’s connect.
#MedicalEducation #AIinMedicine #ClinicalResearch #EvidenceBasedMedicine #AIResearchers #TrialMind #KeijiAI
Clinical trial feasibility should not take weeks.
Yet in most organizations, it still means:
Manual cohort definitions
Back-and-forth with data teams
Static dashboards
Delayed decisions
We built something different.
In this short demo, we show how AI transforms natural language queries into structured feasibility insights and interactive visual dashboards — in minutes.
You can:
• Define complex inclusion/exclusion criteria in plain English
• Stratify by biomarkers, treatment lines, and testing windows
• Visualize treatment distributions instantly
• Iterate on feasibility scenarios in real time
• Move from question → cohort → decision without heavy engineering
For clinical development, RWE, HEOR, and portfolio teams, feasibility is not just analytics — it’s strategy.
The faster you can test assumptions, the better your trial design and resource allocation.
This is what AI-native clinical research infrastructure looks like.
Demo here: https://t.co/XrEBUF6PuQ
Curious how others are thinking about feasibility automation inside pharma and biotech?
#ClinicalTrials #HealthAI #RWE #DrugDevelopment #AI #PrecisionMedicine
https://t.co/8eSwjZqa4h
The Real Cost of Agentic AI: When Your IDE Becomes Cloud Infrastructure
https://t.co/VsYAmlRB80
Our team of 5 spent $4,600 on Cursor in six weeks—roughly double our entire 2025 software budget, with the same team doing similar work.
The subscription still says "$40/month." But that's no longer what you're actually paying.
Cursor shifted from request-based pricing (500 fast requests + unlimited slow) to metered compute tied to underlying LLM costs. When an agentic coding session pulls massive repo context and runs multi-step loops, a single "request" can cost $1–$2 instead of $0.04.
That's not a price increase. It's a fundamental reframing of what you're buying.
This reveals a deeper tension across vertical AI products:
Users expect SaaS predictability. AI products run on volatile token economics. When subscription anchors at $20 but real workflows scale 10–20×, you don't just surprise users with bills—you break trust.
Finance teams start asking: "Is this software or infrastructure?"
That category shift is dangerous. Once buyers treat you like infrastructure, they demand budgets, caps, governance, and approvals. Friction rises. Procurement slows. Adoption stalls.
The uncomfortable truth for AI-native companies:
If revenue growth depends primarily on token burn, you're not building a product moat—you're reselling compute.
The real moat is workflow depth, proprietary data, integration into core processes, switching costs, and compliance infrastructure.
Subscription should absorb variance. Usage should be bounded. Heavy users should be segmented deliberately, not caught off guard by overages.
Cursor is genuinely powerful. The productivity gains are real.
But as we move into agentic, long-context workflows, cost architecture becomes as strategic as the product itself. Pricing isn't just monetization. It's a signal of whether you're building a durable product or a metered pipeline to someone else's API.
How is your team budgeting agentic AI? Like SaaS, or like cloud infrastructure?
5 years, 22+ papers: How can AI transform clinical research?
Foundation models, cross-modal architectures, privacy-preserving synthesis. Published in Nature Communications, NeurIPS, EMNLP.
Foundation for Keiji AI + TrialMind
#AIinHealthcare#ClinicalTrials#MachineLearning
Pandemic prediction is a physics problem disguised as a data problem.
HOIST uses Ising model dynamics for COVID hospitalization prediction - treating counties as lattice sites with learned coupling from claims data and mobility patterns.
Paper: https://t.co/5rUxDCSMsv
#COVID19 #PublicHealth #MachineLearning #PhysicsInformedML
When data reflects disparities, ML models perpetuate them.
FairPlay uses LLMs to generate synthetic patients for underrepresented groups. Up to 21% F1 improvement for minorities while maintaining majority performance.
Paper: https://t.co/ibgXqJHW7S
#HealthEquity#AIforGood #FairnessInAI #HealthcareAI
The dirty secret of synthetic data: most methods only work on pre-selected variables.
HALO generates high-dimensional EHRs (thousands of variables) using hierarchical autoregressive modeling. Correlations >0.9 with real data.
Paper: https://t.co/IhWLaU4oB9
#SyntheticData #DigitalTwin #HealthcareAI #MachineLearning