Join Mu-SHROOM 🍄, a SemEval 2025 shared task on detecting hallucination spans in multilingual LLM outputs! 🌍 Includes Czech with regional Czech questions 🇨🇿. Do you think you can spot when something isn’t true? 🤔 Try it out! 👉 https://t.co/SOU1YTtq2g #SemEval2025#NLProc
This is going to be fun! 🤓 We have three years to spend 6.5M CZK on improving multilingual tokenization. The goal is to make subwords more alignable across languages and help languages that suffer from over-segmentation with current models.
Good news! 🥳 GAČR will fund two of our projects:
👉 @jlibovicky proposes to better tokenization for #LLMs and machine translation
👉 Veronika Kolářová will study syntactic features of Czech non-verbal predicates
➕ Dominik Macháček receives Postdoc Individual Fellowship! 💪
Finally, @kat_haem and Gianluca Vico presented one of the three price-winning 🏆🤑 submissons for the shared task on multilingual named entity recognition and question answering! w/ @AndreiM85400815, @jindra_helcl and @jlibovicky. Congrats! https://t.co/kZxNr3tKpY
This week I am at #EMNLP2024 in Miami 🌴🇺🇸. Find me 🕵️ or message 💌 me if you want to chat about multilinguality or tokenization and stop by our poster on Tuesday at 2 p.m., I'll present our paper on lexically Grounded Subword Segmentation https://t.co/R7W28p5BeZ
Summaries of #multilingual#LLM and machine translation papers I liked in October are now on my blog https://t.co/Pg6mMtNe9J and also on Medium
https://t.co/6clmWCKbLq
In our #EMNLP2024 paper with @jindra_helcl, we present a new subword tokenization method that is more morphologically plausible but maintains the nice properties of existing tokenizers.
Pre-print: https://t.co/Dqx0N6k7kr
Code: https://t.co/s3pztuSk8N
👇🧵1/4
In a week, @jindra_helcl and I will present our paper Lexically Grounded Subword Segmentation at #EMNLP2024 in Miami 🌴🇺🇸. You can already watch our video 🎥 https://t.co/g88FRIeVoo or stop by our poster 👋 next Tuesday at 2 p.m...
👍 It works great for preserving morpheme boundaries.
👍 Does a good job in POS tagging.
👎 No improvement in machine translation.
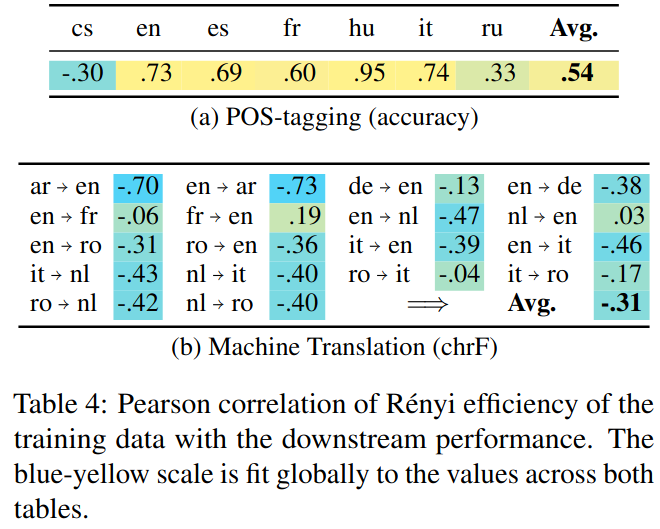
And bad news, @zouharvi, our downstream performance does not correlate with Rényi efficiency. 🤷♂️
🧵4/4
In our #EMNLP2024 paper with @jindra_helcl, we present a new subword tokenization method that is more morphologically plausible but maintains the nice properties of existing tokenizers.
Pre-print: https://t.co/Dqx0N6k7kr
Code: https://t.co/s3pztuSk8N
👇🧵1/4
Then, we find segmentations with subwords with the closest embedding closest to the word embedding. We collect bigram stats from those and use them in a bigram-LM-based segmenter (a generalization of SentencePiece).
And we also do some experiments...
🧵3/4
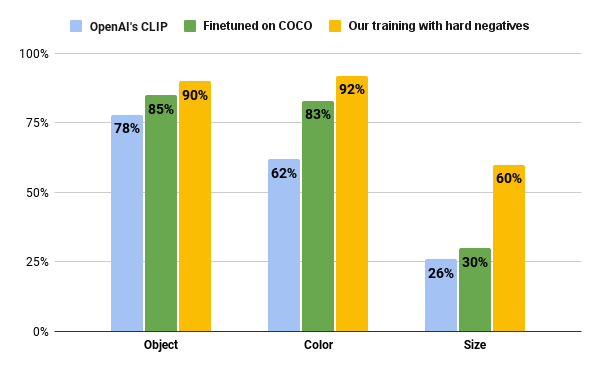
In the paper introducing the dataset https://t.co/cj7OrNW5mF, we also present a method based on hard-negative sampling on the text side of the model that significantly improves the model's ability to distinguish details.
📣 We have a dataset!
❓Have you also noticed that language-vision encoders like CLIP do not pay attention to details?
❓ Do you think your model is doing better?
👉 InpaintCOCO dataset https://t.co/GBJJgVAU9j is here for you.
Work of @phiyodr, folks from @unibw_m, and myself.
It consists of minimum pairs of images and captions derived from the MS COCO test set. Annotators used object detection and Stable Diffusion Inpanting 👨🎨👩🎨 to get images with either different objects or objects of different colors and sizes. Everything's 100% human-supervised. 💪