DFlash for Gemma 4: Up to 6x Faster. ⚡⚡
Great to see MTP land natively in Gemma 4 today. If you want to push it further, try DFlash — open source, same quality, more speed!!
https://t.co/wKcRoibuOB
Our newest model, π0.7, has some interesting emergent capabilities: it can control a new robot to fold shirts for which we had no shirt folding data, figure out how to use an appliance with language-based coaching, and perform a wide range of dexterous tasks all in one model!
ParoQuant just got a big upgrade 🚀
✅ Supports the new Qwen3.5 models
⚡ Now runs on MLX (fast local inference on Apple Silicon)
���� Preserves reasoning quality with 4-bit quantization
We also built an agent demo running locally on my 4-year-old M2 Max.
Can't wait to upgrade to an M5 Max and see what kind of magic we can do. ✨
Real-world loco-manipulation demands more than replaying fixed reference motions.
We argue that true autonomy requires two capabilities:
1️⃣ flexibly leveraging whatever signals are available — dense references, partial cues, state estimates, or egocentric perception
2️⃣ remaining capable when any of these signals are missing or unreliable
We introduce ULTRA — an all-in-one controller for unified humanoid loco-manipulation 🤖
It supports:
• general reference tracking
• sparse goal following
• execution with motion capture
• execution with egocentric perception
🔗 Project page:
https://t.co/Ce9RHvryPC
We’ve developed a memory system for our models that provides both short-term visual memory and long-term semantic memory.
Our approach allows us to train robots to perform long and complex tasks, like cleaning up a kitchen or preparing a grilled cheese sandwich from scratch 👇
Reasoning LLMs generate very long chains-of-thought, so even small quantization errors add up.
With AWQ, Qwen3-4B drops 71.0 → 68.2 on MMLU-Pro (~4% relative loss). 😬
ParoQuant fixes this! It keeps only the critical rotation pairs and fuses everything into a single kernel.
Recovers most of the lost reasoning accuracy with minimal overhead — so 4-bit models stay strong at reasoning. 💪💪
As context windows grow 📈, continual learning matters more!
@tianyuanzhang99 will present how to scale test-time training for effectively infinite context ♾
🗓️ Feb 19, 3pm ET
@scaleml
On RTX5090, VLASH can reduce the control latency from ~530 ms to ~30 ms, achieving up to a 17× control latency reduction compared to synchronous inference.
On RTX4090 and RTX5070, we can achieve ~15× and ~9× latency reduction, respectively.
This low-latency control is essential for highly dynamic tasks and high-frequency correction for the robot.
Even large VLAs can play ping-pong in real time! 🏓⚡️
In practice, VLAs struggle with fast, dynamic tasks:
• slow reactions, jittery actions.
• demos often shown at 5-10× speed to look “smooth”.
We introduce VLASH:
• future-state-aware asynchronous inference with >30Hz inference frequency for PI0.5
• drop-in to existing VLAs with no extra overhead
• enables PI0.5 / PI0 to play ping-pong and other highly dynamic tasks in real time
📄 Paper: https://t.co/01bKQmMCKs
🔧 Code: https://t.co/NfQ80ASZOK
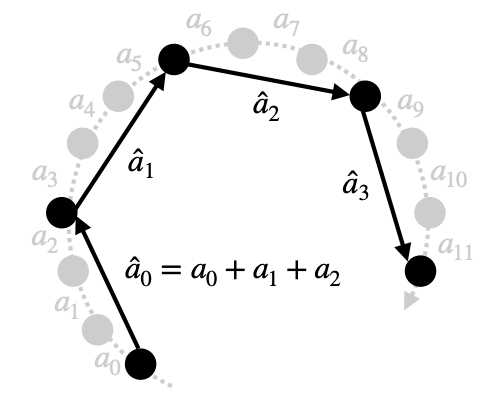
We also add a simple trick to make robots move even faster: “quantize” robot actions for speed.
VLAs are trained on very fine-grained teleop data, so they output tiny action steps that are often more precise than necessary. VLASH groups every q fine-grained actions into one coarser action, so the robot takes fewer, larger steps that follow almost the same trajectory, but much faster.
Introducing DuoAttention: Our new framework slashes both memory and latency for long-context LLMs without sacrificing performance! By applying full KV cache only to critical heads, we achieve:
⚡ 2.55x memory reduction
⚡ 2.18x decoding speedup
⚡ 3.3M tokens on a single A100 GPU
🚀Excited to introduce Quest: an efficient long-context LLM inference framework, accepted by ICML 2024!🌟
⚡️Quest leverages query-aware sparsity to achieve up to 2.23× e2e speedup for long-context LLM inference.
📄Paper: https://t.co/flH9rhwgd5
💻Code: https://t.co/HOJSzjiQX1