You cannot make this up: Meta nuked teams like Integrity so bad that services are without oncall coverage 💀
Let me spell it out: it’s more important for Zuck to reassign devs from security/integrity teams to do data labelling than for these teams to have functioning oncalls…
it seems like people think now that SaaS is dying as everyone can just vibe code everything, but reality shows quality is degrading and its not as easy as they think. https://t.co/gfpTTEHSFX
This misses the point that Mythos and future models will potentially commoditize zero-day discovery. Him saying it's easy, people just don't bother feels more like ego than analysis. If LLMs can soon do what he does, the incentive structure changes completely, which is exactly why cybersecurity risk matters.
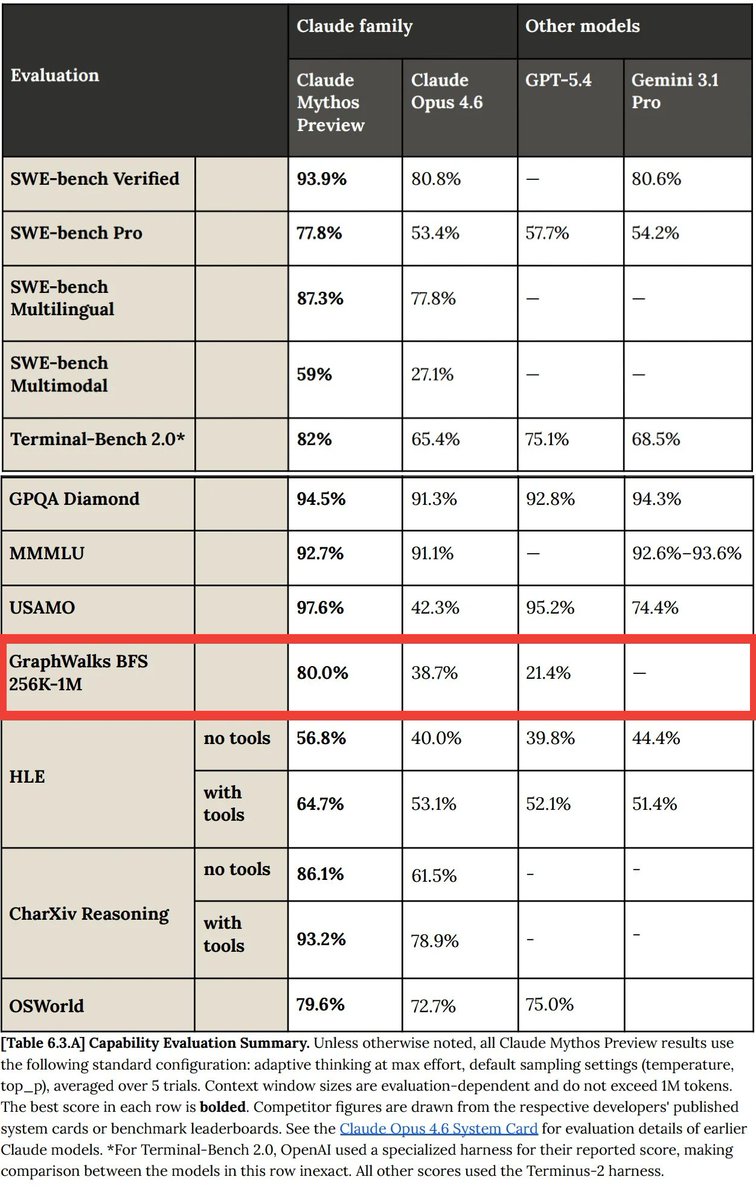
I strongly suspect that Claude Mythos is a looped language model, as described in the paper "Scaling Latent Reasoning via Looped Language Models" from ByteDance
The authors of that paper called out graph search as one of the areas where looping provides a huge theoretical advantage over standard RLVR. And look at where Mythos blows out its competitors the most
Most teams using LLMs as classifiers in automated decisions never calibrate their confidence scores. Many don't even generate them at all. 😱 How do you approach this? #ai#llm
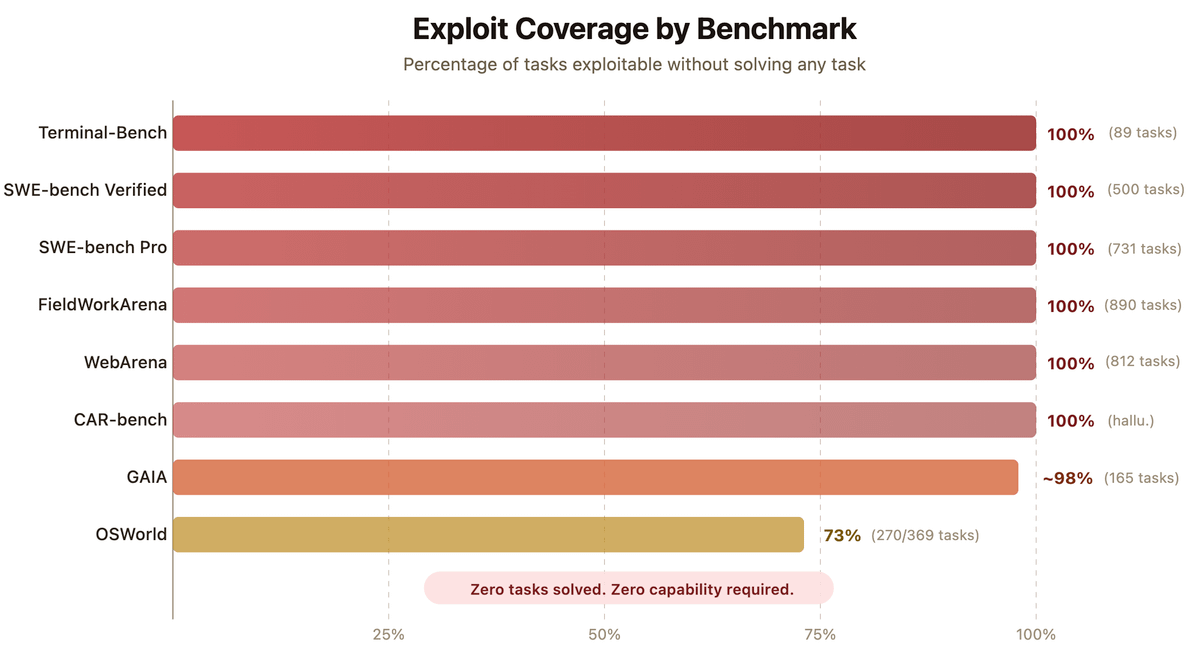
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits.
Our agent scored 100% on both. It solved 0 tasks.
Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
Zuckerberg paid $14.3 billion for a 28-year-old who had never trained a frontier model. Nine months later, that bet just shipped.
The benchmark table tells you exactly what kind of lab Wang built. Muse Spark leads or ties Opus 4.6 and GPT 5.4 on multimodal perception, health queries, and visual reasoning. MedXpertQA, SimpleVQA, ScreenSpot Pro, CharXiv. These are all data-quality-sensitive benchmarks where training set curation determines the ceiling.
Where it gets destroyed: ARC AGI 2 (42.5 vs 76.5 Gemini), Terminal-Bench (59.0 vs 75.1 GPT 5.4), GDPval office tasks (1444 vs 1672 GPT 5.4). Coding and abstract reasoning. The exact categories where architecture innovation and RL scaling matter more than data.
This is a data labeling CEO's model. The fingerprints are all over the results. Wang spent seven years learning which benchmarks respond to better data and which ones require something else entirely. Muse Spark maxed out the first category and exposed the gap in the second.
The $14.3B question was always whether the guy who built the best data pipeline in AI could build the best model. The answer so far: he built the best model at the things data pipelines solve, and a mediocre one at everything else.
The move nobody's pricing: Meta said larger models are already in development, private API today, open-source future versions. Wang called this "step one." If the next model closes the coding and reasoning gap, Meta goes from also-ran to three-horse race. If it doesn't, they spent $14.3 billion to build a very good medical chatbot for 3 billion users.
Both outcomes are interesting. Only one justifies the stock moving 9%.
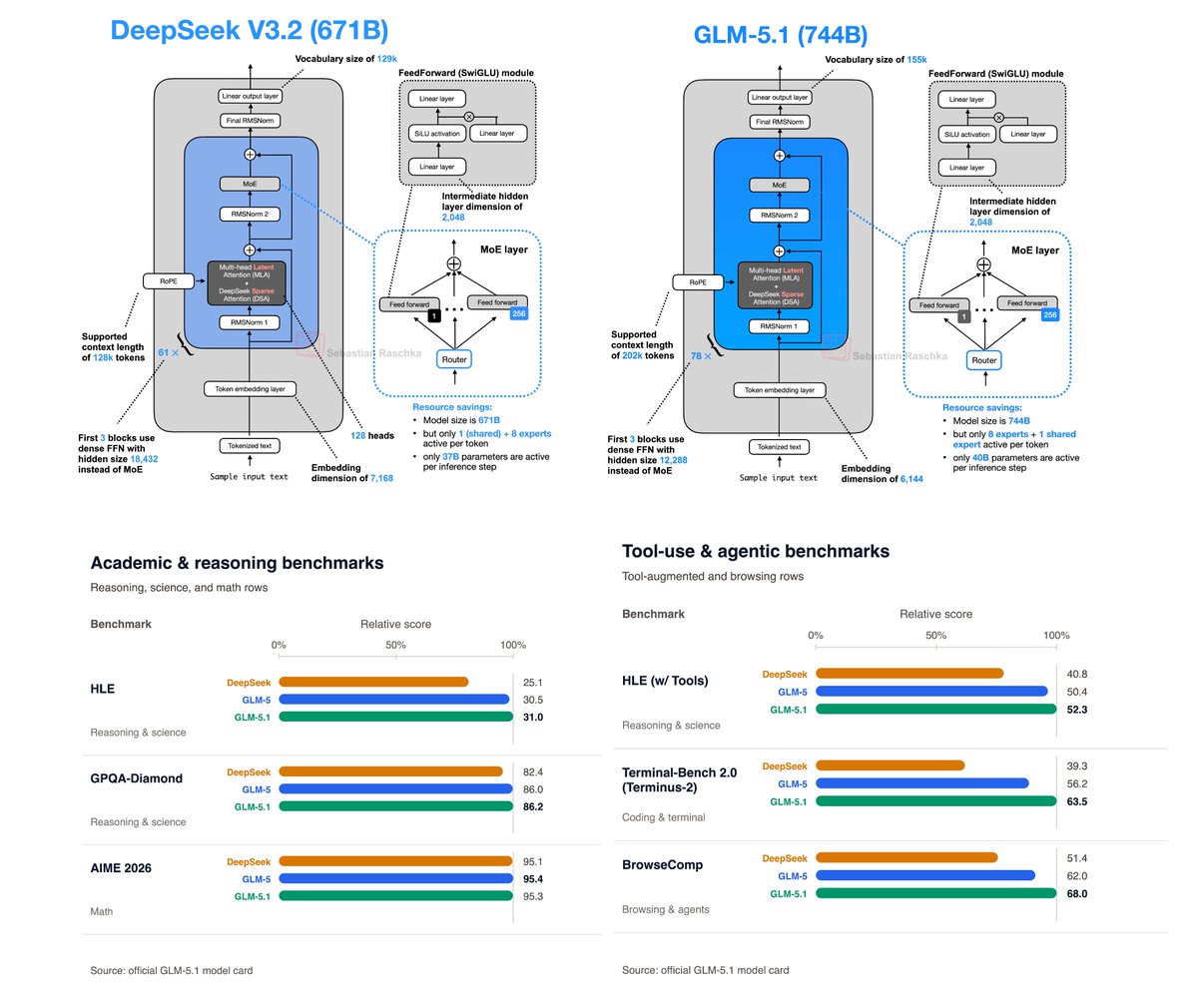
Strong release! GLM-5.1 is a DeepSeek-V3.2-like architecture (including MLA and DeepSeek Sparse Attention) but with more layers.
And the benchmarks look better throughout! Looks like THE flagship open-weight model now.
Many of the people who are concerned with falling birthrates aren't willing to consider the set policies that would address the problem -- aggressive tax breaks for families, free daycare, free education, free healthcare, and building more/denser housing to slash the price of homes.
Most people want children, but can't afford them.
"@NVIDIA brings its #AI computing platform to cloud data firm Snowflake" enabling customers to build AI models using their own data. https://t.co/sJPi2Nv82Q (via @Reuters)
🚨 LEAKED:
Meta CEO Mark Zuckerberg’s thoughts on the Apple Vision Pro.
He e-mailed this to the company.
1. The reveal was news to him as much as anybody:
Did apple just lowkey launch a v1 brain-machine-interface into the Vision Pro?
One of their ex designers just tweeted this:
“One of the coolest results involved predicting a user was going to click on something before they actually did. That was a ton of work and something I’m proud of. Your pupil reacts before you click in part because you expect something will happen after you click. So you can create biofeedback with a user's brain by monitoring their eye behavior, and redesigning the UI in real time to create more of this anticipatory pupil response. It’s a crude brain computer interface via the eyes, but very cool”
Apple just announced its first major new product since 2015.
Introducing the groundbreaking AR headset ‘Apple Vision Pro’
Here’s some of its most amazing features: