Today we're launching Crucible, a coverage-guided fuzzing framework for Solana programs. Built for Anchor, with v2 support from day one.
Just one example of what Crucible can find: a years-old bug in Solana's stake program, surfaced in seconds ↓
On Solana, events are often reconstructed from transaction traces, and failed transactions still emit data.
@Dooflin5 details a bug in Across that could have allowed attackers to spoof deposit events and trick relayers into filling orders with no real deposit behind them.
Where others use AI to “create”, at TigerBeetle we’re more excited about how to use the machines to “destroy”.
Some see AI as a way to “type faster” or “increase productivity”, but at TigerBeetle I tell the team we’re already “too productive” (through TigerStyle), we want calm focused work not burnout… and we know that all the huge gains come from understanding anyway.
So “destruction” aka testing, i.e. as a foil or sparring training partner, is where we see it’s at with AI.
Not to create. That stays with the humans so we don’t atrophy our understanding, which is more valuable than “LOC”.
But to increase quality through defense in depth in testing. But even there, the gains with AI are marginal, a few percent, compared to the 90% power of our DST, which again, came from systems thinking.
So I encourage our team to “keep playing the violin yourself”, to keep practicing, keep training, keep investing in understanding.
CU optimizations come with risks.
@_fel1x discusses a critical bug we found in p-token before mainnet, subtle enough to survive in a heavily scrutinized codebase.
@IceSolst@hyprdude I think people underestimate the art of writing a good fuzzing harness. Arguably LLMs allow you to get started a lot faster and with less domain knowledge or expertise in a particular code base
@pmddomingos AI doesn’t have to be able to find bugs a human can’t, or do it for cheaper, to change the dynamics of cyber security.
1. Capable humans are supply constrained.
2. On problems AI can solve it is often dramatically faster than a human.
Using local LLMs?
Make sure to setup web search for them
Tell your favorite agent to setup SearNg for you
Give that to your local LLMs (tell an agent to set that up as well)
Watch them become way more intelligent and efficient
You're welcome
New post: Code coverage for coding agents, by @NearBeteigeuze
When an agent audits your codebase, a common question is: what did it actually read and with what intent? Current tools don't answer that. We built a prototype and open-sourced it.
With support from Solana Foundation, we're launching STRIDE, a comprehensive security program that sets clear standards for @solana ecosystem projects.
STRIDE will provide independent opsec evaluations with public findings for real transparency into protocol security posture.
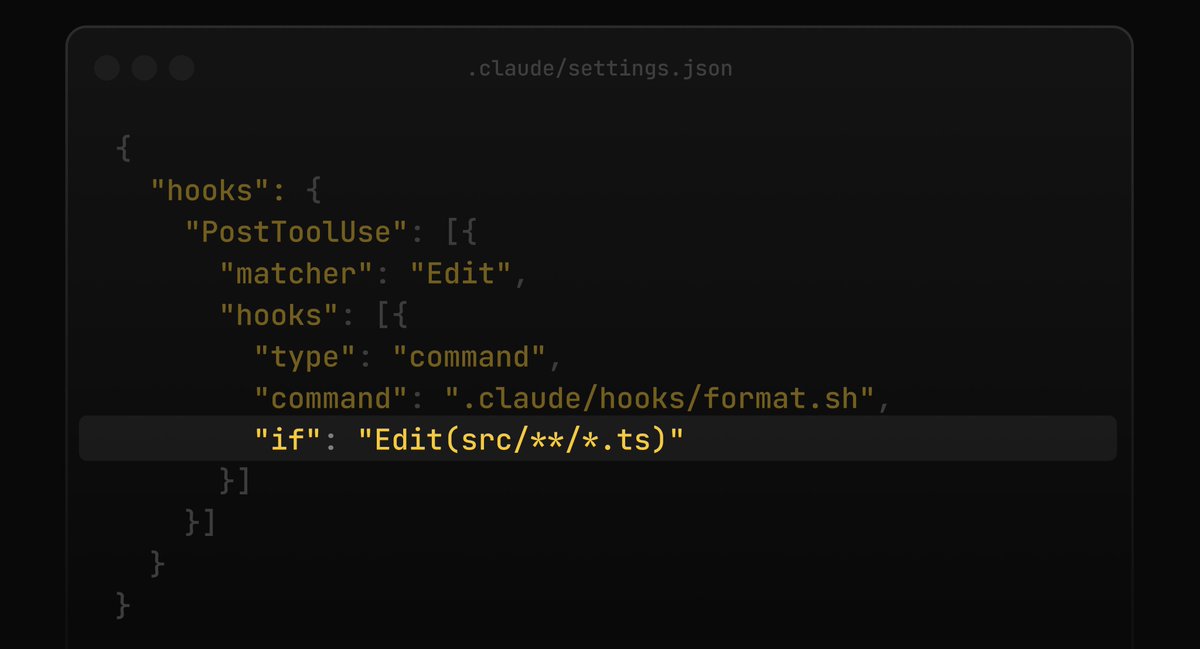
Claude Code now supports an `if` field in hooks
It uses permission rule syntax to filter when a hook runs, which is useful when you want a hook on some bash commands but not every single one!
These days, in almost all my discussions I get asked what I think about AI and the future of security, so I figured I should share it here
Short version: I try not to have a strong opinion yet. We are clearly in a transition phase, and outside of people working directly on foundation models, no one really has a solid view of where this is going
Over the past months, LLMs improved a lot. The releases at the end of 2025 were a real step change. In practice, most people I know (myself included) have barely written code in the past 2-3 months. For security, we went from "this is fun" to "this is actually useful"
Right now, the best mental model I have is that we effectively jumped from having no tooling to having an advanced static analyzer or fuzzer. A lot of bugs that used to take time to find can now be surfaced quickly
Does that mean security researchers disappear in 2 years? Based on today’s tech, I do not think so. There are a lot of bugs to be found. Some are found by humans, some by traditional techniques, and now some by LLMs. But it does not mean all bugs get found. If anything, history suggests there are always more bugs than anyone expects, and that gap does not go away easily
The real question is: do LLMs get another capability jump, or just steady iteration? There are reasonable arguments both ways. To be honest, I do not have enough understanding of how these models evolve to have a confident answer. And anyone giving a very definite answer is probably overconfident, unless they are working directly on the models
Depending on that, the role of security researchers could change a lot, including the way we work. The demand could decrease if models get very strong at finding bugs. But it could also increase if the amount of code grows faster than the models’ ability to reason about it. We could even end up with a shortage of experienced researchers in a few years if fewer juniors enter the field while seniors move elsewhere. It is hard to predict because everything depends on how model capabilities evolve
On the business side, I am skeptical about "AI audit as a service". If models keep improving, it is hard to see how these companies compete with native offerings from OpenAI or Anthropic. Especially if those providers stop exposing raw capabilities and push everyone into their own products. I tried codex security, and while it is not perfect, it is clear where this is going. Mythos / Capybara seem to be around the corner, and it will be interesting to see how far it goes
My current bet is that within a few months, tools like codex or claude security will be great at finding blockchain issues, and they will integrate directly into most dev pipelines. At that point, the marginal value of an extra "AI audit SaaS" becomes limited
So what to do as a security researcher? Be adaptive. This is a transition period, and things will likely move fast in 2026. Stay curious, and keep working on skills that give you an edge. Regularly reassess where you are strong or weak, and where AI helps you versus where it replaces you. If you like challenges, see AI as one that pushes you to improve
Also, be careful with what people call "cognitive debt" or "brain rot". I was skeptical at first, but I do see it now. The more I rely on LLMs during an audit, the more I lose part of the intuition that I normally build while going deep into code. That intuition is still critical to find complex bugs. I have not found the right balance yet, but it is something to watch
It probably makes sense to revisit your view on LLMs every 3-6 months. I have already been wrong a few times on this, and I am fine with that, as long as I don’t get locked into a fixed view
Finally, a lot of people focus on the downside for security researchers. But there are also upsides. I can explore codebases much faster, build custom tooling easily, and spend less time on boring tasks. Maybe it’s my last few years/months as a security researcher, maybe not. But at least LLMs let me have some fun before doomsday 😅
Having Claude read @TigerBeetleDB Tiger Style + best practices for a different language and then having it write a new code style doc for that language is actually unbelievable alpha I am giving to you right now for free
opencode 1.3.0 will no longer autoload the claude max plugin
we did our best to convince anthropic to support developer choice but they sent lawyers
it's your right to access services however you wish but it is also their right to block whoever they want
we can't maintain an official plugin so it's been removed from github and marked deprecated on npm
appreciate our partners at openai, github and gitlab who are going the other direction and supporting developer freedom
@lossfunk What's the interpreter output like for these languages? I wonder if the agentic runs would do better if the compiler was capable of outputting syntax suggestions similar to the Rust compiler, or if the compilers had auto-fix for whitespace problems, etc.
@0xcastle_chain Fun idea, curious how you're encoding the bugs into the program.
Do you have private integration tests with exploits that you'll release at the end of the week?
How're you confirming that the generated programs work in the first place?