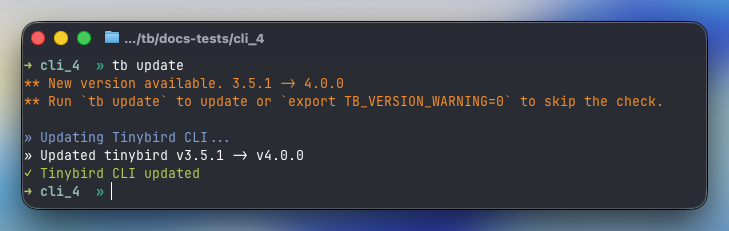
We used PostHog for parts of our product and growth analytics.
It was practical. We were already sending events there, building charts there, and using it for session recordings.
Then the useful context kept pulling us back into Tinybird 🧵
We are using @rawtreedb internally as we build it for more and more things.
We added Open Telemetry Traces to @OpenAgentsAI with @vercel sandboxes and @aisdk with a few prompts. No schema design, nothing to deploy. Just an API Key and SQL.
Love it. We have this* at @tinybird and we do see the benefits of people working together in public.
*well, you can ask private, but maybe we should block that
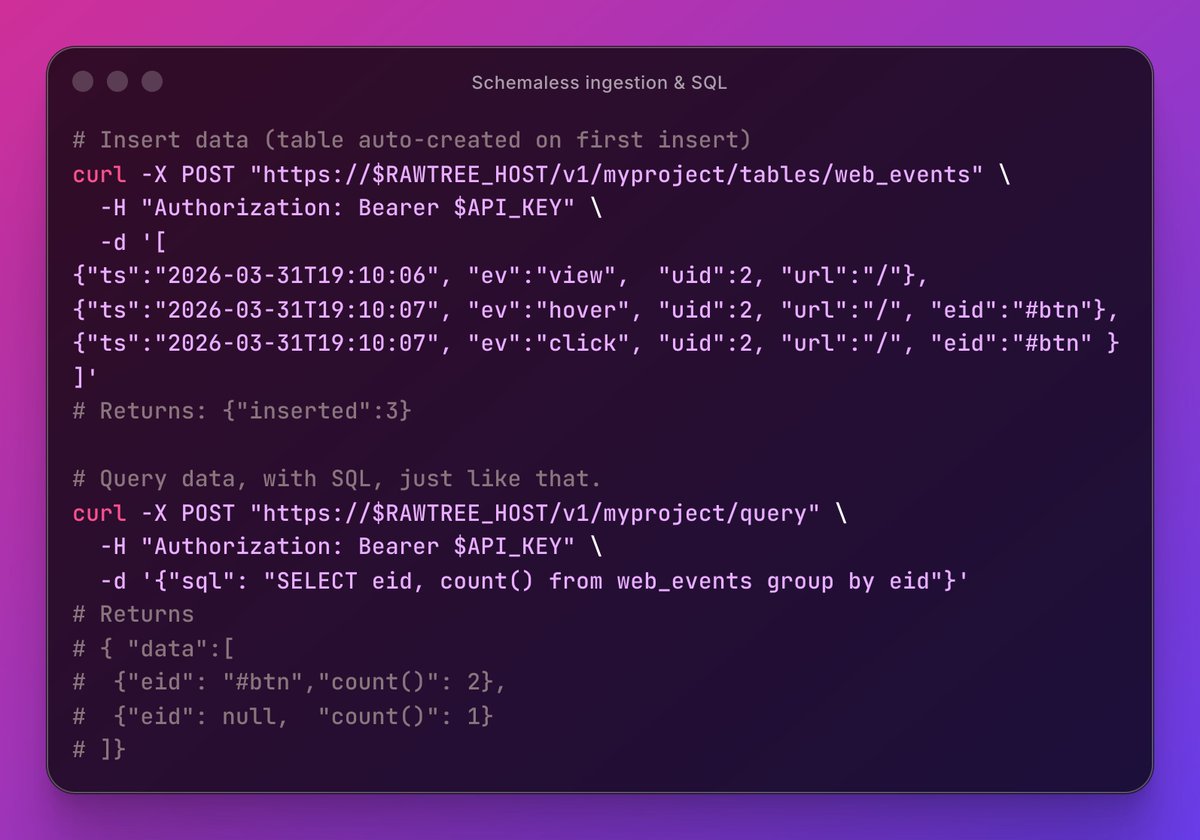
We’ve been forcing messy data into rigid schemas for 20+ years.
JSON. Events. Logs. Traces.
What if the database adapted to the data... and not the other way around?
Most analytical databases start with:
• define schema
• build ingestion pipelines
• create indexes
• materialize views
• optimize
• rinse and repeat
The larger the scale, the bigger the pain.
What if you just… didn't have to do any of this?
We are working on something new.
The 🐐@makisuo built Maple, an open-source observability platform on OpenTelemetry that queries billions of rows in milliseconds. 🔭
No cluster management, no ingestion pipeline, no API layer to build. Just pipes, endpoints, and branches.
"I don't think I would have started the project without Tinybird."
https://t.co/8cVdV2VrxX
we're seeing more and more people bringing their analytics to Tinybird from Mongo. And now it's even easier with TypeScript SDK.
Let me know if you need any help with the setup.
As coding agents take over more of the development workflow, humans need better tools to understand, observe, and operate their production data.
@juliavallina and @nmediavilla19 rebuilt the Tinybird UI for that
Supabase - Convex drama aside, the point is this: your db (convex for transactional, tinybird for analytical) should feel like part of your app, not something you constantly wire up and hope stays in sync.
That's why we built a TypeScript SDK for Tinybird. Not a wrapper of the APIs, any LLM can do that. It's about making analytics native to your codebase. Define once, use everywhere, compiler catches your mistakes so prod doesn't have to.
https://t.co/04nZaakMHp
We built Learn ClickHouse. 80+ lessons covering ingestion, querying, optimization, and distributed architectures.
Not just tutorials. Production-ready patterns from teams running ClickHouse at scale.
Free. No fluff.
👉 https://t.co/IoKL5t6vGT
Looking for some deep technical content to read over the holidays? Interested in how Tinybird works under the hood? 🤓
Here's a thread with our 12 best engineering blog posts of 2025 🧵
New in Tinybird's CLI, a much improved way to create and preview Kafka connections 🔌
- Create the connection independently or start ingesting directly with 'tb datasource create'
- CLI goes full wizard mode asks for bootstrap servers and config settings, validating along the way
- CLI stores keys and secrets as environment variables (.env.local) to use different settings in local, cloud or other environments
- Preview the data you just connected to make sure everything looks great
And when you are ready, simply run `tb --cloud deploy` to push in to production and start ingesting.
Here are 9 real-world, "Flink-shaped" use cases teams are shipping with Kafka + Tinybird.
All without a single stateful job. And a couple of CLI commands to set up 🧵🔥