What are the benefits of Clean architecture?
- Modularity
- Separation of concerns
- Testability of business logic
- Improved team productivity
- Loose coupling of components
There's no "right" way to build software.
You should decide what works for you.
Clean architecture works well for me.
I've used it to build excellent products.
If you want to get started quickly, I've created a free Clean Architecture template.
You can download it here: https://t.co/SrPHVO3qw1
Tomamos un proyecto .NET que no tenía una sola verificación automática. Ni analyzers, ni formato forzado, ni hooks.
Le configuramos una primera capa de verificación determinista.
Hace poco compartí la pirámide de madurez para adoptar IA. La Fase 1 es justo esto: instrumentación que valida el código sin que un humano lea cada cambio.
Esto fue lo que configuramos, todas viven en el repo:
1. global.json. Fija la versión del SDK con la que compila el equipo. Así el build se comporta igual en cualquier máquina y en CI, sin sorpresas por versiones distintas.
2. https://t.co/5tmQk5H9l9.props. Enciende los analyzers de .NET y activamos warnings = errors. Esto hace que el build deje de tolerar avisos: nada pendiente en el código se acepta.
3. .editorconfig. El formato deja de ser opinión. dotnet format lo arregla solo y un check lo verifica en cada cambio.
4. NuGet Audit. Revisa si tus dependencias tienen CVEs conocidos en cada restore. Un sensor de seguridad dentro del build.
5. Tests conectados a la señal de confianza. Un test que no corre en cada cambio no valida nada.
6. Makefile. El catálogo de comandos del proyecto, el mismo para el equipo y para el agente. Ahí vive make check, que corre lint + build + test de una sola vez: la señal única de que el código está sano.
7. lefthook. Corre los checks antes del commit y del push. Atrapas el problema en tu máquina, antes del review.
Lo primero que pasó al encender todo esto: el build se puso rojo. El culpable, un CVE en una dependencia transitiva que llevaba ahí sin que nadie lo viera. El código estaba muy bien; la vulnerabilidad venía heredada en una librería que el proyecto arrastraba.
La próxima fase: que la arquitectura se valide sola.
¿Tienes algunos de estos configurados en tu proyecto .NET?
A lot of .NET developers think CQRS means using MediatR.
It does not.
CQRS is much simpler than that:
→ Commands change data
→ Queries read data
→ Handlers run one use case
That is the pattern.
A mediator library can help wire things together.
But you do not need one to keep your app clear and easy to change.
A small CQRS setup can give you:
→ Clear command and query handlers
→ Direct calls from your endpoints
→ Validation around commands
→ Logging around requests
→ Simple testing and debugging
This does not mean libraries are bad.
It means your architecture should not depend on a tool when a few simple building blocks are enough.
CQRS can be boring.
That is a good thing.
I built a minimal CQRS pipeline in .NET with custom handlers, decorators, and clean DI setup.
See the full approach here: https://t.co/g2db0ee54w
𝟳+ 𝘆𝗲𝗮𝗿𝘀 𝗯𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗺𝗶𝗰𝗿𝗼𝘀𝗲𝗿𝘃𝗶𝗰𝗲𝘀
Here is what I will ask during interviews 👇
The key areas I explore when interviewing senior .NET devs:
• Communication patterns between microservices
• Resilience strategies
• Event-driven architecture
• Orchestration and coordination
• Infrastructure patterns
• Architecture decisions
Each area reveals how deeply someone understands distributed systems.
Most candidates focus just on tools: Docker, Kubernetes, and messaging libraries.
They miss the bigger concepts that separate middle and senior engineers.
Microservices are not only about technology stacks.
They're about boundaries, scalability, resilience, and trade-offs.
Check what you can answer with confidence.
The gaps show your growth opportunities.
📌 Save this post for future reference!
——
♻️ Repost to help others master microservices in .NET
➕ Follow me ( @AntonMartyniuk ) to improve your .NET and Architecture Skills
La gente dice "la IA programa por vos".
No. La IA ejecuta. Vos diseñás, decidís el stack, definís el scope, validás cada fase y deployás.
Acabo de hacer un producto entero de punta a punta y el agente nunca tomó una sola decisión importante solo.
El que dirige seguís siendo vos.
🚀 New Course Launched: Angular Forms In Depth (Signals Edition)
🎉 I've just launched a brand new course — Angular Forms In Depth ( Signals Edition) — that teaches you to build any form you'll ever need using the new Angular Signal Forms API.
The course is fully complete, and I've used a new way of recording. Instead of typing, the code is progressively unveiled bit by bit.
✨ This makes the course signal-to-noise ratio much better. 😉
Go and check out the free lessons, and see for yourself:👇
𝗔𝗻𝗴𝘂𝗹𝗮𝗿 𝗙𝗼𝗿𝗺𝘀 𝗜𝗻 𝗗𝗲𝗽𝘁𝗵 (𝗦𝗶𝗴𝗻𝗮𝗹𝘀 𝗘𝗱𝗶𝘁𝗶𝗼𝗻)
🔗 https://t.co/FpmsxJaf2g
📖 𝗔𝗯𝗼𝘂𝘁 𝘁𝗵𝗶𝘀 𝗰𝗼𝘂𝗿𝘀𝗲
If you've ever wrestled with reactive forms, FormControl, nested form groups, or async validators, you'll want to see this.
⚡ Signal Forms is a complete redesign of Angular forms built around signals: model-driven, fully typed, and with a fraction of the boilerplate of reactive or template-driven forms.
🎯 By the end of the course you'll be able to:
✅ Build any form from scratch with Signal Forms
✅ Apply built-in, custom, and async server-side validators
✅ Create reusable custom controls that plug straight into the form system
✅ Handle conditional fields, cross-field validation, and dynamic arrays
✅ Integrate Zod via Standard Schema
✅ Ship production patterns: unsaved-changes guards, multi-step wizards, file upload with progress, and draft pre-saving
💻 We build it all through a single real-world sample app, with a running GitHub repo you can clone and follow along.
💙 Happy coding,
Angular University
🌐 https://t.co/gl9IiyaGqL
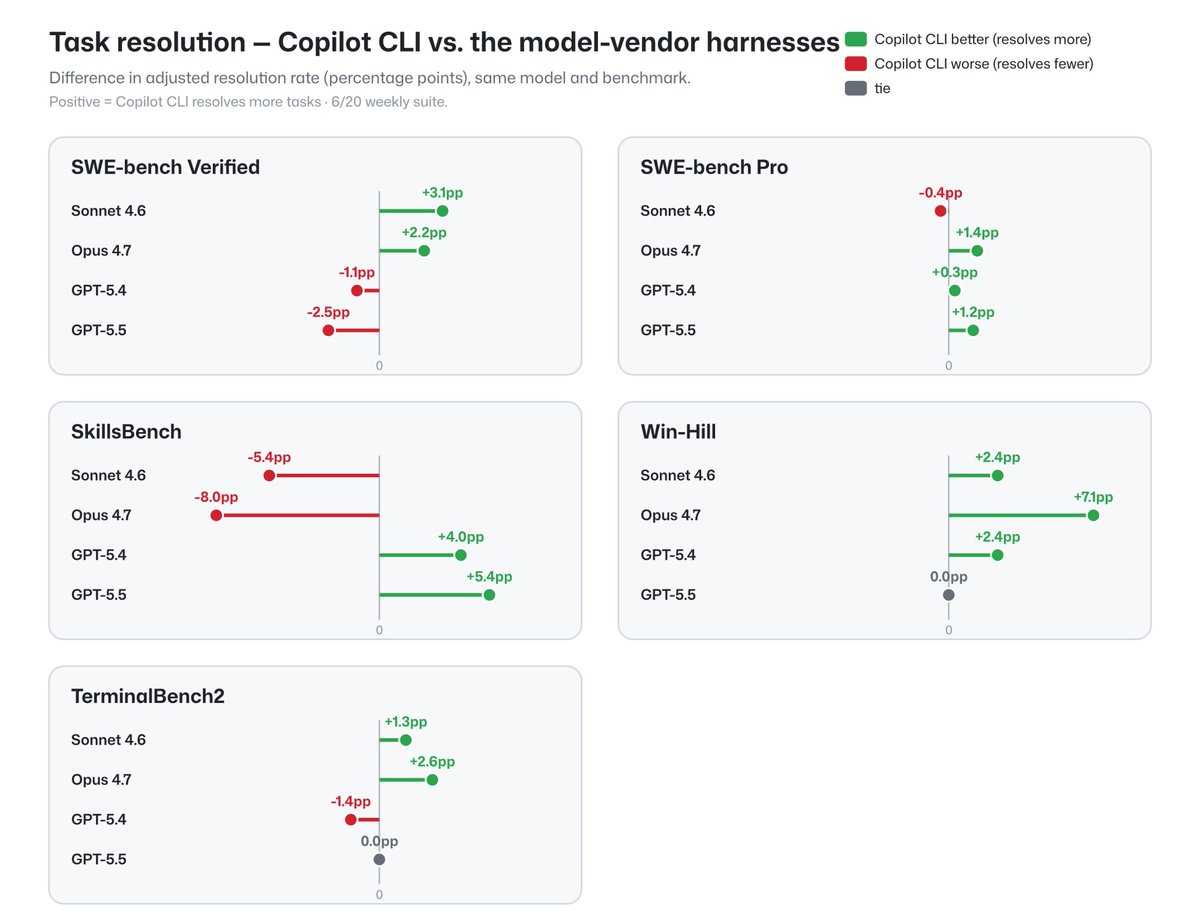
We often get asked how GitHub Copilot compares to other coding agent harnesses on the market.
Today, we're publishing some data on Copilot's performance across popular benchmarks on resolution rate and token efficiency.
https://t.co/6qOPrhBM3D
spartan/ui is 1.0 🎉
55+ accessible Angular components. Signals, zoneless-ready, SSR out of the box.
Built by an incredible group of maintainers and over 100+ spartans that contributed.
Made possible by @zerops.
This is madness! This is spartan!
https://t.co/5GbbQtY30r
Anthropic acusa a Alibaba de la mayor "destilación ilícita" de Claude que vieron hasta hoy. 28.8 millones de interacciones, 25.000 cuentas falsas.
Y la mayoría de la gente no entiende qué significa eso realmente.
Destilación no es hackeo. Nadie robó código ni pesos del modelo. Lo que se hace es más sutil y más inteligente: le preguntás millones de veces al modelo fuerte, juntás sus respuestas, su forma de razonar, su manera de resolver, y entrenás un modelo más chico con eso. Copiás el comportamiento sin copiar el motor.
Pensalo así. No le robás el cerebro a Tony Stark. Le grabás cada decisión que toma durante meses hasta que tu modelo aprende a imitarlo. Más barato que investigar desde cero.
Literalmente miles de millones más barato.
Y acá está lo jugoso. Anthropic pide al Congreso que frene estas prácticas mientras EE.UU. le acaba de cortar a la propia Anthropic el acceso global a sus modelos top por control de exportación.
El que pide protección está siendo apretado por el mismo Estado. Esa es la pelea real del 2026: no es modelo contra modelo, es geopolítica contra ingeniería.
Ojo, es una acusación. Alibaba todavía no respondió. Pero el patrón ya lo vimos antes con DeepSeek, Moonshot y MiniMax. No es un caso aislado.
La pregunta que importa para vos que programás: ¿entendés qué te están vendiendo cuando usás un modelo barato? Porque a veces lo barato es una copia sin los guardrails del original. Y eso no se ve en el benchmark.
Conceptos antes que código. Siempre.
Es así.
Link en comentarios.
He trabajado con mucha gente demasiado junior, incluso trainee en cargos de CTO, jefe de proyecto o Principal Engineer. Esto se da en Start-ups muchísimo.
El problema es que son idiotas con el ego muy desproporcionado a la realidad y no aprenden. Así que ya no me desgasto con ellos.
Lo mejor que se puede hacer es huir de ahí cuanto antes. No entienden de procesos, de desarrollo, términos técnicos, y lo peor es que el éxito no está dado por el conocimiento, si no por la cantidad de capital que es capaz de levantar con inversionistas.
El mundo está lleno de trabajos para desarrolladores, muy buenos, bien pagados y con excelente ambiente. No te quedes en un ambiente de mierda solo por stock options.
Homelab IA Nivel: dios 🔥
Este hombre subió los specs completos de su cluster que tiene en su casa para IA:
- 32× RTX 3090 (4 servidores × 8 GPUs)
- Placa: ROMED8-2T + CPU EPYC 7302
- 256 GB RAM DDR4-3200
- Red: ConnectX-6 + Switch SB7800 InfiniBand
- PSU: 2× Super Flower Leadex 2000W
- Enfriamiento: 8 fans de 120mm exhaust + fan dedicado para la NIC
Todo con energía solar + banco de baterías + generador
Costo aproximado: ~$30k solo en compute + $4k red + ~$10k en solar/generador.
¿Esto ya cuenta como datacenter oficial o seguimos en homelab?
This is the best way to version APIs.
But nobody is using it.
Have you heard of media type versioning?
It's the cleanest approach to API versioning.
1. You specify the API version in the Accept header.
2. The server routes those requests to the appropriate API endpoint.
You don't pollute the URL with versions. You can also extend this with content negotiation.
But API versioning is only a means to an end. The best API doesn't do versioning.
Instead, what you need is change management.
Change management means evolving an API without surprising or breaking existing clients. Instead of immediately creating v2, you first ask whether the change can be additive, whether old and new behavior can coexist, whether a new operation is safer than changing an existing one, and whether deprecation can be handled with docs, runtime signals, migration guidance, and telemetry.
Love the idea of Polygraph!
It provides agents with understanding of your entire codebase spread across repositories.
It's satisfying when a tool is built to be at the right level of abstraction.
𝗦𝘁𝗼𝗽 𝘂𝘀𝗶𝗻𝗴 𝗼𝘂𝘁𝗱𝗮𝘁𝗲𝗱 𝗱𝗲𝘃 𝘁𝗼𝗼𝗹𝘀
Here are the 10 tools I (actually) use in 2026:
The developer toolkit looks nothing like it did two years ago.
AI is no longer a side feature. It now sits at the center of how you write code, design systems, run meetings, and learn.
Here's my full stack:
𝗔𝗜 𝗰𝗼𝗱𝗶𝗻𝗴 𝗮𝗴𝗲𝗻𝘁𝘀
1. Claude Code → reads your whole PC (CoWork), follows your CLAUDE[.]md rules, writes production-grade backend and frontend code. My top pick.
2. OpenAI Codex → strong second agent. Great if you live in the ChatGPT ecosystem.
𝗜𝗗𝗘𝘀
3. JetBrains Rider → the best refactoring engine in .NET, plus the Junie AI agent. Cross-platform.
4. Cursor → VS Code with AI injected into every part of the editor. Best for polyglot teams.
𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗮𝗻𝗱 𝗱𝗼𝗰𝘀
5. NotebookLM → turn your RFCs and PDFs into an assistant you can talk to, with citations to your sources.
𝗗𝗶𝗮𝗴𝗿𝗮𝗺𝘀
6. Eraser[.]io → diagram-as-code. Your architecture diagrams live in Git and update when your text changes.
𝗪𝗿𝗶𝘁𝗶𝗻𝗴 𝗮𝗻𝗱 𝘀𝗽𝗲𝗲𝗱
7. Wispr Flow → voice-to-text system-wide. You type at 50-80 wpm. You talk at 150+. Do the math.
8. Grammarly → fixes your writing everywhere you type. A game-changer if English isn't your first language.
𝗠𝗲𝗲𝘁𝗶𝗻𝗴𝘀 𝗮𝗻𝗱 𝘀𝗹𝗶𝗱𝗲𝘀
9. Granola → captures meetings without joining as a bot. Clean notes, not a 4,000-word transcript.
10. Gamma → describe a topic, get a full slide deck in under a minute.
You don't need all 10. The right stack depends on your budget and how much you lean on AI every day.
In the article, I break down 4 ready-to-use stacks by budget:
✅ Free ($0) → a surprisingly strong starting point
✅ $50 → the smart starter stack
✅ $100 → the productive professional stack
✅ $500 → heavy lifting for serious work
I also share which single upgrade gives the biggest jump in output, my honest take on Claude Code vs Codex, and the exact order I'd buy these in.
👉 Read the full breakdown here (with pricing for every tool):
↳ https://t.co/BoGTkShkWF
𝗕𝗲𝘀𝘁 𝘁𝗼𝗼𝗹𝘀 𝗼𝗳 𝘁𝗵𝗲 𝘄𝗲𝗲𝗸:
AI needs context. Your database architecture matters, and split data won't cut it. TigerData puts everything in one PostgreSQL + TimescaleDB instance for you, and lets the schema do the work: https://t.co/uM9xm3mDrZ
Tiger Data open-sourced an MCP server for Postgres: https://t.co/Zwxp4PBTWB
Explore the open-source repo on GitHub and try Tiger Cloud today! New users get $1,000 in free 30-day credit, no credit card required: https://t.co/hsJimmWNOf
Which of these 10 is already in your stack?
——
♻️ Repost to help other .NET developers upgrade their stack
➕ Follow me ( @AntonMartyniuk ) to improve your .NET and Architecture skills
Most LINQ code uses five methods on repeat. The other useful ones quietly replace your loops.
Eight are in the image. Here are the four I reach for the most once people know they exist.
DistinctBy. Plain Distinct compares whole objects, which rarely does what you want. DistinctBy lets you remove duplicates by one property, like one row per user id. No grouping, no manual dictionary. Just say which key makes an item unique.
MaxBy and MinBy. To find the order with the highest total, people often sort the whole list and take the first item. That's wasteful. MaxBy gives you the single item with the largest value of a key in one pass, and returns the object itself, not just the number. MinBy does the same for the smallest.
Chunk. When you need to process items in batches (say, 100 records per database call), Chunk splits a sequence into smaller groups of a fixed size for you. No index math, no counter. You get a clean sequence of arrays to loop over.
GroupBy. This one isn't rare, but most people underuse it. It buckets items by a key, so you can count orders per customer or group logs by day in a couple of lines instead of building a dictionary by hand.
The rest in the image (Zip, Aggregate, SelectMany, and ToLookup) are just as handy once they're in your toolkit.
Learn the method that already exists before you write the loop.
I put together 30 EF Core interview questions. The senior kind, not the "what is an ORM" kind.
Writing them, one pattern kept showing up: the question or it's complexity was never the problem. The way you answer, that is the real differentiator.
Everyone can write a ToListAsync call. Far fewer can explain it when the interviewer pushes back.
The question is never "what does this query do." It's "why did you write it that way, and when would you not?"
And the answer that quietly sinks people is "it depends," left hanging there.
On its own, "it depends" sounds like a guess. The version that gets you hired finishes the sentence: here's my default, and here's when I'd deviate.
Try it on a plain read query - load the published posts and hand them back.
The follow-up: would you put AsNoTracking on it?
Weak answer: "It depends on the situation." Then silence.
Strong answer: "Yes. This is read-only, so AsNoTracking is my default here. EF Core skips the change-tracking snapshots, which saves memory and CPU on a query I'm never saving back."
Then the line that proves you've actually shipped it.
"I'd drop AsNoTracking the moment I plan to edit and save these entities. With nothing tracked, SaveChanges sees no changes and quietly does nothing."
Same shape works on almost every EF Core question. Explain what EF Core is really doing under the hood, then commit to a default and the exact case where you'd break from it.
"It depends" is a fine place to start. Just don't stop there. The people who get hired always say the next sentence.
These 30 are all on EF Core 10, each with the answer that lands the offer and the one that gets you rejected. Link's in the comments if you're prepping.
Error común en APIs NET:
Confiar solo en la extensión del archivo
Por ejemplo:
factura.png puede ser un PDF, un Excel o file corrupto
Primero valida los primeros bytes (magic numbers):
PNG → 89 50 4E 47
PDF → 25 50 44 46
ReadOnlySpan<byte> en NET lo resuelve sin allocations


























![AntonMartyniuk's tweet photo. 𝗦𝘁𝗼𝗽 𝘂𝘀𝗶𝗻𝗴 𝗼𝘂𝘁𝗱𝗮𝘁𝗲𝗱 𝗱𝗲𝘃 𝘁𝗼𝗼𝗹𝘀
Here are the 10 tools I (actually) use in 2026:
The developer toolkit looks nothing like it did two years ago.
AI is no longer a side feature. It now sits at the center of how you write code, design systems, run meetings, and learn.
Here's my full stack:
𝗔𝗜 𝗰𝗼𝗱𝗶𝗻𝗴 𝗮𝗴𝗲𝗻𝘁𝘀
1. Claude Code → reads your whole PC (CoWork), follows your CLAUDE[.]md rules, writes production-grade backend and frontend code. My top pick.
2. OpenAI Codex → strong second agent. Great if you live in the ChatGPT ecosystem.
𝗜𝗗𝗘𝘀
3. JetBrains Rider → the best refactoring engine in .NET, plus the Junie AI agent. Cross-platform.
4. Cursor → VS Code with AI injected into every part of the editor. Best for polyglot teams.
𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗮𝗻𝗱 𝗱𝗼𝗰𝘀
5. NotebookLM → turn your RFCs and PDFs into an assistant you can talk to, with citations to your sources.
𝗗𝗶𝗮𝗴𝗿𝗮𝗺𝘀
6. Eraser[.]io → diagram-as-code. Your architecture diagrams live in Git and update when your text changes.
𝗪𝗿𝗶𝘁𝗶𝗻𝗴 𝗮𝗻𝗱 𝘀𝗽𝗲𝗲𝗱
7. Wispr Flow → voice-to-text system-wide. You type at 50-80 wpm. You talk at 150+. Do the math.
8. Grammarly → fixes your writing everywhere you type. A game-changer if English isn't your first language.
𝗠𝗲𝗲𝘁𝗶𝗻𝗴𝘀 𝗮𝗻𝗱 𝘀𝗹𝗶𝗱𝗲𝘀
9. Granola → captures meetings without joining as a bot. Clean notes, not a 4,000-word transcript.
10. Gamma → describe a topic, get a full slide deck in under a minute.
You don't need all 10. The right stack depends on your budget and how much you lean on AI every day.
In the article, I break down 4 ready-to-use stacks by budget:
✅ Free ($0) → a surprisingly strong starting point
✅ $50 → the smart starter stack
✅ $100 → the productive professional stack
✅ $500 → heavy lifting for serious work
I also share which single upgrade gives the biggest jump in output, my honest take on Claude Code vs Codex, and the exact order I'd buy these in.
👉 Read the full breakdown here (with pricing for every tool):
↳ https://t.co/BoGTkShkWF
𝗕𝗲𝘀𝘁 𝘁𝗼𝗼𝗹𝘀 𝗼𝗳 𝘁𝗵𝗲 𝘄𝗲𝗲𝗸:
AI needs context. Your database architecture matters, and split data won't cut it. TigerData puts everything in one PostgreSQL + TimescaleDB instance for you, and lets the schema do the work: https://t.co/uM9xm3mDrZ
Tiger Data open-sourced an MCP server for Postgres: https://t.co/Zwxp4PBTWB
Explore the open-source repo on GitHub and try Tiger Cloud today! New users get $1,000 in free 30-day credit, no credit card required: https://t.co/hsJimmWNOf
Which of these 10 is already in your stack?
——
♻️ Repost to help other .NET developers upgrade their stack
➕ Follow me ( @AntonMartyniuk ) to improve your .NET and Architecture skills](https://pbs.twimg.com/media/HLo6vi-W0AAJAYb.jpg)
































