Frontier labs are investing massively in RL environments, yet most of what happens in this space stays behind closed doors.
@chrisbarber and @js_denain interviewed 18 people from RL environment startups, neolabs, and frontier labs. Here's what they found:
Conventional wisdom says that the US can’t build power but China can, so China’s going to “win the AGI race by default”.
We think this is wrong.
The US likely can build enough power to support AI scaling through 2030 — as long as they’re willing to spend a lot.
A thread:
Should AI regulations be based on training compute?
As training pipelines become more complex, they could undermine compute-based AI policies.
In a new piece with Google DeepMind’s AI Policy Perspectives team, we explain why. 🧵
xAI commissioned us to analyze Grok 4’s math capabilities. Our findings:
+ It’s good at involved computations, improving at proofs (from a low base), and useful for literature search.
- It favors low-level grinds and leans on background knowledge.
Read on for examples!
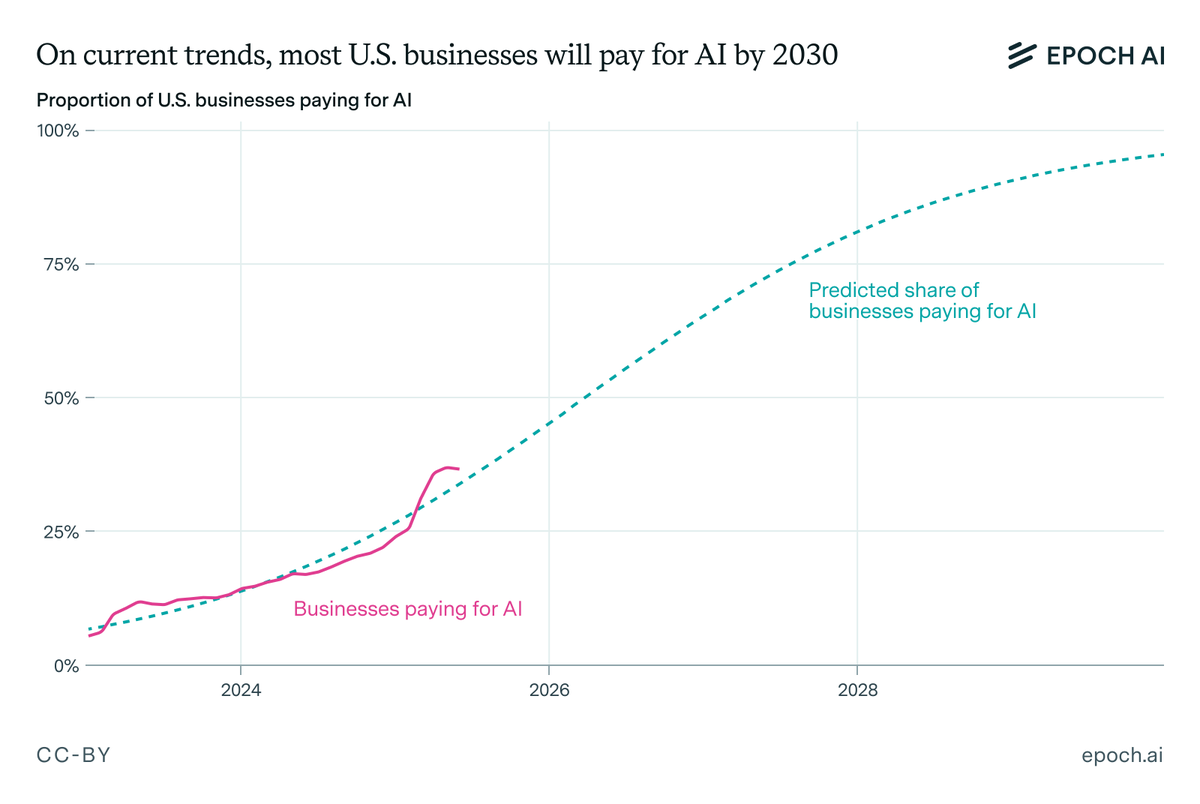
How fast has society been adopting AI?
Back in 2022, ChatGPT arguably became the fastest-growing consumer app ever, hitting 100M users in just 2 months. But the field of AI has transformed since then, and it’s time to take a new look at the numbers. 🧵
We are still hiring for an Engineering Lead on our Benchmarking team! We need a software engineer with outstanding technical expertise (no AI experience necessary) who's excited about leading evaluations on frontier AI models.
Introducing FrontierMath Tier 4: a benchmark of extremely challenging research-level math problems, designed to test the limits of AI’s reasoning capabilities.
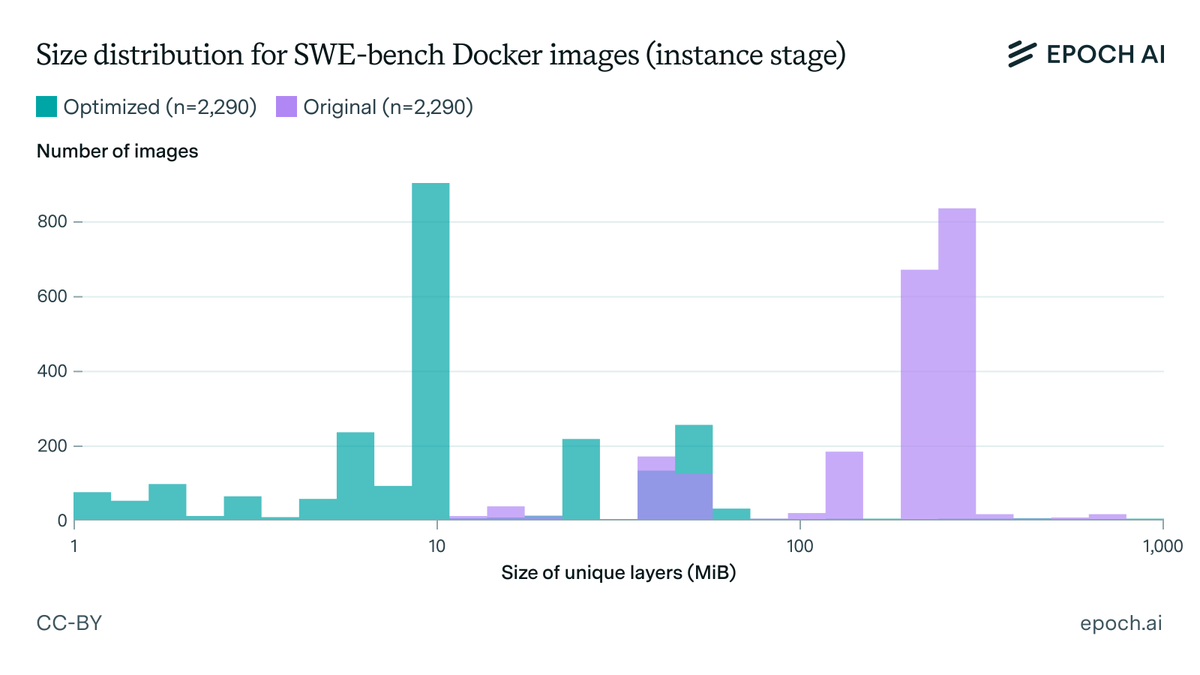
Running SWE-bench evals is very slow and difficult. To solve this, we created a registry of optimized Docker images that let us run SWE-bench Verified in just one hour on a single 32-core machine.
Today, we are open-sourcing these images— anyone can `docker pull` them.
The GitHub API doesn't seem to support changing the visibility of an image on the Container Registry.
This is a huge problem for me as I have 4,219 images I need to make public for an @EpochAIResearch project :(
Anyone at GitHub who could help with this?
SWE-bench Verified is one of the main benchmarks to assess AI coding skills. But what does it actually measure?
We found that it's one of the best tests of AI coding, but limited by its focus on simple bug fixes in familiar repositories.
Here’s a summary of our article 🧵
Three years and 100+ projects in, our mission is the same: give everyone clear, trusted insight into where AI is headed. Our new post unpacks the principles behind every research choice—why we take some ideas on and pass on others.
https://t.co/2bkq9rkN1s
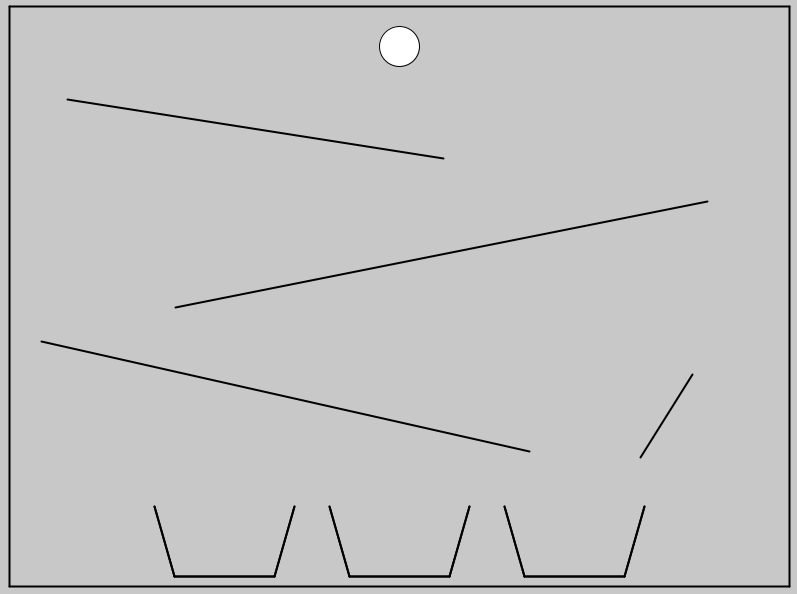
@TeksEdge Hi! The problems are all of the same form: you're given an image with ramps and buckets like this one, you have to predict which bucket the ball will fall into.
We’re hiring an Engineering Lead to help guide our Benchmarking team! Provide independent evaluations of today’s and tomorrow’s AI models, leading to better research, policy, and decision-making. The role is fully remote, and applications are rolling.
@scaling01 - OpenCompass
- HHEM
- Galileo Agent
- XLANG Computer Agent Arena
I haven't looked into them in detail yet, but will H/T you if we add some of them to the hub 🙂
@scaling01 Thanks for making your list though!
It did put on the radar some benchmarks I was not tracking:
- Thematic Generalization by LechMazur (I knew of the writing and multi-agent ones, not this one)
- Dubesor LLM
- TrackingAI - IQ Bench
- Misguided Attention
- Snake-Bench