Today at @MLSysConf, @MichaelKuchnik will present Plumber, our tool for diagnosing and removing performance bottlenecks in ML input data pipelines.
Joint work with @jsimsa, @GeorgeAmvrosia2 and Virginia Smith.
Paper: https://t.co/CkXKLcWiwo
If you are interested in advancing infrastructure that provides large scale data analysis and processing for ML workloads across Google, my team is hiring:
https://t.co/G6cXp7qRJN
Our VLDB’21 talk about https://t.co/uGweaPNtSE, a ML data processing framework, is now online: https://t.co/t79rzH8c4M
More details in our paper: https://t.co/1M5hJRmnEh
It has been great to collaborate on this work with @mrry@jsimsa & Ihor Indyk!
Five years ago, we open sourced @TensorFlow, our machine learning framework that's now the most popular machine learning library in the world. 🌎 To celebrate, we’re sharing few interactive demos and tutorials you can try, no experience required → https://t.co/JxKOSC5R69
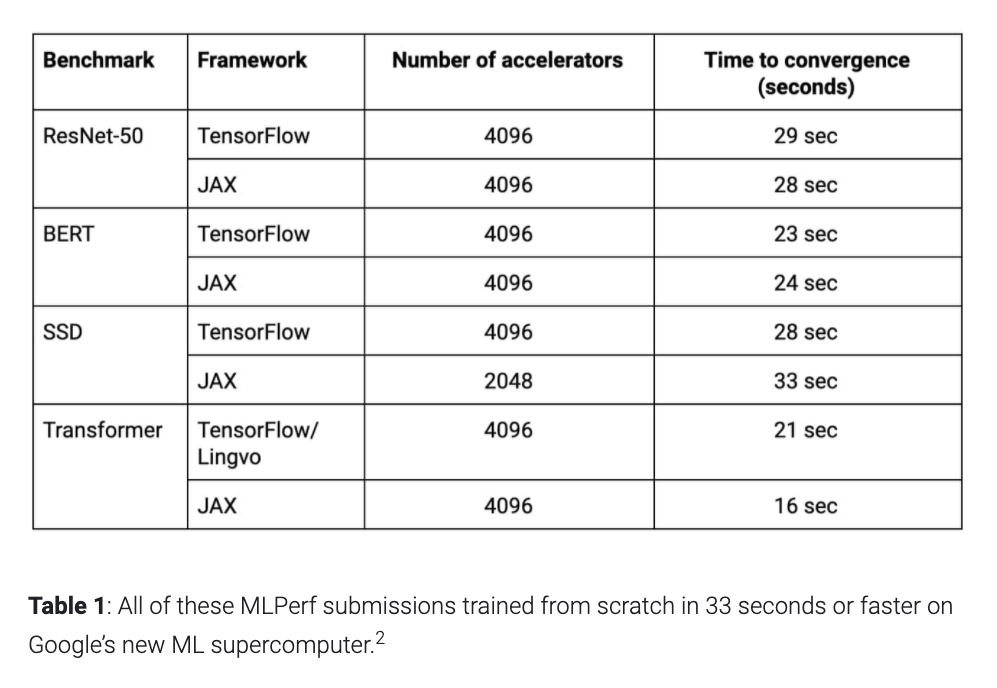
Awesome to see the success of TensorFlow and JAX, both using https://t.co/u0l4xlIzUJ to ingest data fast enough to train to convergence in under 30 seconds!
Very excited to see the MLPerf 0.7 results released today, where Google TPUs set records in six of the eight benchmarks!
We need bigger benchmarks, because we can now train the ResNet-50, BERT, Transformer, & SSD benchmarks each in under 30 seconds.
https://t.co/J6vbZ8srs1
In 2016, when I was working on machine translation, it took me more than a week on a multi-GPU machine to train a competitive system on WMT English-German.
Today, JAX on a TPU v3 supercomputer can train a better model on the same data in 16 seconds! https://t.co/fRK6vwZHDP
👉 https://t.co/Fv77gxVyzu supports *any* machine learning framework (JAX, @TensorFlow, PyTorch, more!), and is a great way to speed up your data input pipelines.
Be sure to try out our new features for https://t.co/Fv77gxVyzu, available in TF 2.3: https://t.co/reGFHiLImI
🔍Inside TensorFlow: https://t.co/EPERzWIIN0 + tf.distribute
In this presentation, Jiri Simsa showcases best practices. You’ll learn about the input pipeline, parallel extraction, distributed training, and more.
Watch here → https://t.co/3CLRx3yAE6
If your dataset is small, use an in-memory cache:
ds = ds.cache()
If large, create an on-disk cache:
ds = ds.cache("my_file")
Afterwards, you can call ds.batch() and ds.shuffle() as always.
Complete example: https://t.co/gz6aBT3SLQ
Speaker spotlight - @jsimsa, tech lead of the https://t.co/q8kr2WIIgg project & software engineer at Google, to present on https://t.co/q8kr2WIIgg the recommended API for creating #TensorFlow input pipelines @ #DataOrchestrationSummit. RSVP: https://t.co/70IJHb9ApG
#opensource
Loving the "Inside Tensorflow" series. The latest release on the TF data API highlights just how much effort the @TensorFlow team has invested in making highly performant pipelines accessible to the end user. Major kudos. 👏👏👏 @mrry@jsimsa et al
https://t.co/XPGwMhluLw
Not only are TPUs fast for doing machine learning, but they are also more energy efficient than alternative platforms, so you can feel great as you train that language model on scientific articles about climate change. https://t.co/eDuEDRYJVz
Today in #CloudTPU announcements: (1) @TensorFlow 1.8 now available with a slew of perf improvements (2.7k to 3.2k images/sec on ResNet-50, aka 12.5 hours is now 9 hours to fully train), and (2) we have opened up a new zone (us-central1-b) for HA & load balancing.
Our latest DAWNBench results are live: 8h52m for @TensorFlow to train ResNet-50 on ImageNet on a single @GCPcloud TPU (<$60), and just 30 minutes on half a TPU pod!
https://t.co/cgJPXMVjhQ
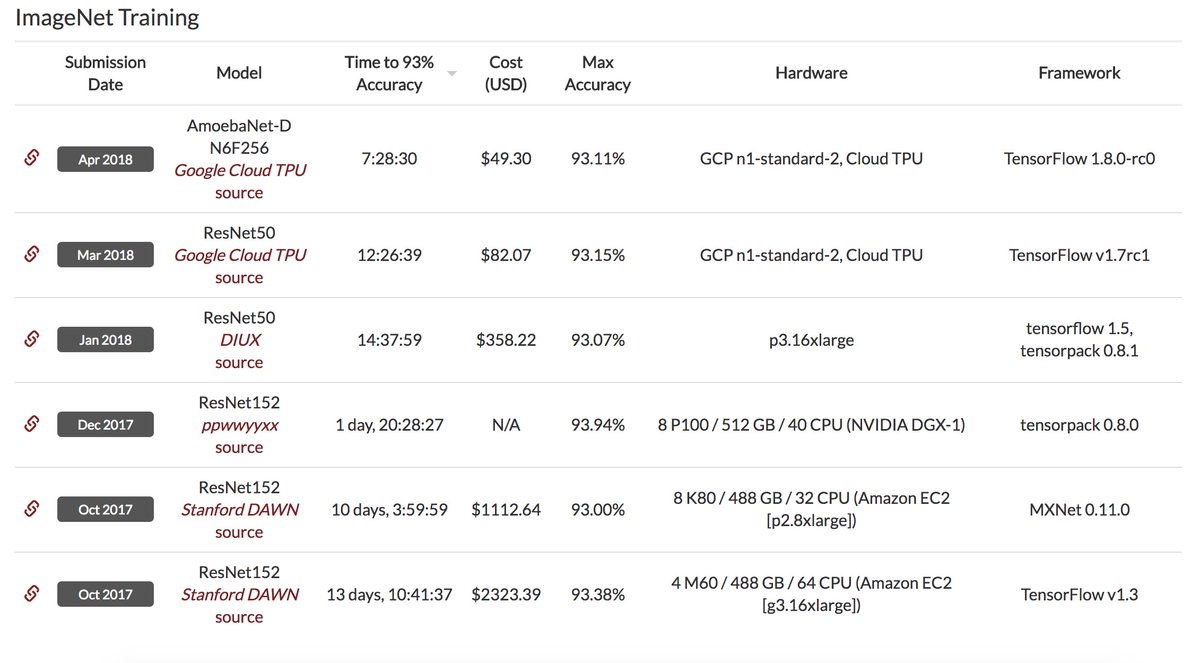
We just posted new DAWNBench results for ImageNet classification training time and cost using Google Cloud TPUs+AmoebaNet (architecture learned via evolutionary search). You can train a model to 93% top-5 accuracy in <7.5 hours for <$50.
Results: https://t.co/CS53YcHtKC
Cloud TPUs (now in !!open!! beta) are a leap forward in price & performance for Machine Learning. (See https://t.co/mo0XorlWk2 for end-to-end benchmarks.) Spin one up at https://t.co/N9d5o5ZEeV today!
If you want to find out more about https://t.co/Jc0yFJ2dFt performance after my talk at #TFDevSummit, check out this awesome guide by @jsimsa and @bsaeta! https://t.co/hYwki5a6cL