1/5
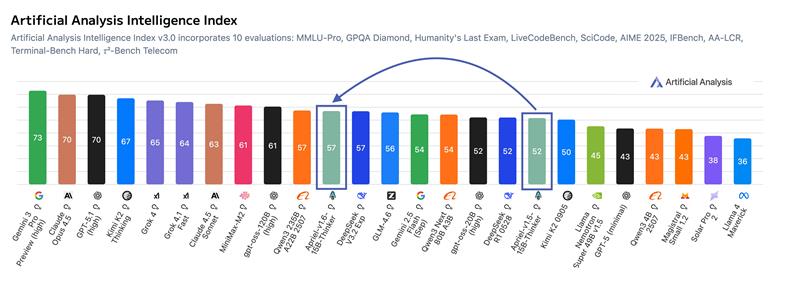
🚀Apriel-1.6-15B-Thinker: a 15B multimodal reasoner scoring 57 on the Artificial Analysis Intelligence Index - approaching the performance of ~200B-scale frontier models while remaining an order of magnitude smaller.
🧠Model weights: https://t.co/cynqpZaphz
📄Blog: https://t.co/vt2Egf712K
💬Chat demo: https://t.co/aHq62h3iXr
@SathwikTejaswi@sagardavasam@tscholak@NVIDIAAI@nvidianewsroom@togethercompute@turingcom@ArtificialAnlys
A lot of talk about AI for operations skips this architectural layer.
If we don’t get the pattern right, we’ll build systems that are hard to steer or secure.
I sketched four design patterns and their risk profiles here: https://t.co/YeGIge7acb
We’re starting to run high-stakes systems (grids, fabs, hospitals) with 3 layers at once:
- deterministic cores (simulators, rules)
- surrogate models (physics + ops)
- large reasoning models
My new essay is about the architecture between them: https://t.co/YeGIge7acb
Physics surrogates vs operational surrogates matter.
- One emulates simulators; the other mirrors messy telemetry.
- They fail differently, can be poisoned differently, need different monitoring.
- Bridging them and deciding who gets to veto whom is a governance problem.
Same ingredients, very different risk:
- Cores as hard gates around a planner
- Surrogates as drivers, cores as auditors
- Watchdogs wrapped around legacy systems
- Parallel models where disagreement is an escalation signal
Pattern choice defines the risk and attack surface.
I end with design principles for AI + agents: make dependencies observable, structure incidents for cross-org patterns, and move from single-agent tests to portfolio stress.
Full piece: https://t.co/KZR4L04P0I
Cloudflare’s outage and insurers pulling back from AI cover both point at the same thing: systemic risk built on shared models, gateways and infrastructure.
New blog post on what we can learn from finance, aviation and cyber: https://t.co/KZR4L04P0I
In my blog post I look at three sectors that already treat systemic risk as first-class: finance (macro-prudential tools and stress tests), aviation (incident reporting and fleet-wide directives), and cyber (voluntary standards and federated sensing).
New blog post on logit steering and sparse autoencoders (SAEs), how they reshape AI security + reliability, open new attack surfaces, and why cost-efficient monitoring matters.
Internal Representations as a Governance Surface for AI https://t.co/Z85cWH9i24
Automated red-teaming is moving from fixed rubrics to learning evaluation systems. AMIS co-evolves jailbreak prompts and the judge’s scoring template. Great for dense signal—but are we optimizing for benchmark ASR or threat-modelled risk? https://t.co/A9FKYd38Gm
So many AI benchmarks lack strong construct validity, and even the ones that have it are used in a way that suggests teams mis-understand the construct they map to.
We are hiring a Sr Applied / Frontier Research Scientist focused on secure, trustworthy agents for enterprise. @ServiceNowRSRCH
If you care about agent security & reliability, apply: https://t.co/87GLCfSkeG
@ServiceNowRSRCH is hiring a Sr Applied / Frontier Research Scientist focused on secure, trustworthy agents for enterprise. If you care about agent security & reliability, apply: https://t.co/87GLCfSkeG
In-flight weight updates have gone from a “weird trick” to a must to train LLMs with RL in the last few weeks. If you want to understand the on-policy and throughput benefits here’s the CoLM talk @DBahdanau and I gave: https://t.co/p3KMZLFg4l
Don't sleep on PipelineRL -- this is one of the biggest jumps in compute efficiency of RL setups that we found in the ScaleRL paper (also validated by Magistral & others before)!
What's the problem PipelineRL solves? In RL for LLMs, we need to send weight updates from trainer to generator (to generate data from our latest policy being trained).
(Conventional PPO-off-policy) A naive approach would be to "start generators on a batch, wait for all sequences to complete, update the model weights for both trainers and generators, and repeat. Unfortunately, this approach leads to idle generators and low pipeline efficiency due to heterogeneous completion times.
(Pipeline-RL) Instead, we simply let the generators continue generating tokens without discarding or finishing ongoing generations in-flight whenever we need to do a weight update -- doing an "in-flight" weight update. As such our KV caches for these generations would be stale, as they would come from LLM with earlier copy(ies) of the weights) but this is ok (see below).
ServiceNow AI Research presents PipelineRL — one of the most impactful efficiency tricks in modern RL training. An elegant solution to a noisy, expensive problem. Worth the read 👇
SLAM Labs presents Apriel-1.5-15B-Thinker 🚀
An open-weights multimodal reasoning model that hits frontier-level performance with just a fraction of the compute.