3 papers accepted at Interspeech 2026! 🎉 Proud to see my role slowly transitioning from a mentee to a mentor. Huge thanks to my collaborators for letting me be a part of their journey!
What if you had nano-banana for audio?
AudioChat is a multi-modal LM that performs fine-grained understanding, generation, and editing of multi-source scenes
By diffusing continuous latents, it generates 48khz stereo edits with great input adherence:
https://t.co/BV08OkjOCT
✨New paper✨
We find script (e.g. Cyrillic, Latin) to be a linear direction in the activation space of Whisper, enabling transliteration at test-time by adding such script directions to the activations — producing e.g. Cyrillic Japanese transcriptions.
4 papers submitted & accepted at ACL 2026! 🎉 So grateful to work alongside & learn from amazing minds, pushing the boundaries of speech technologies, machine learning, and computational linguistics. See you in San Diego!
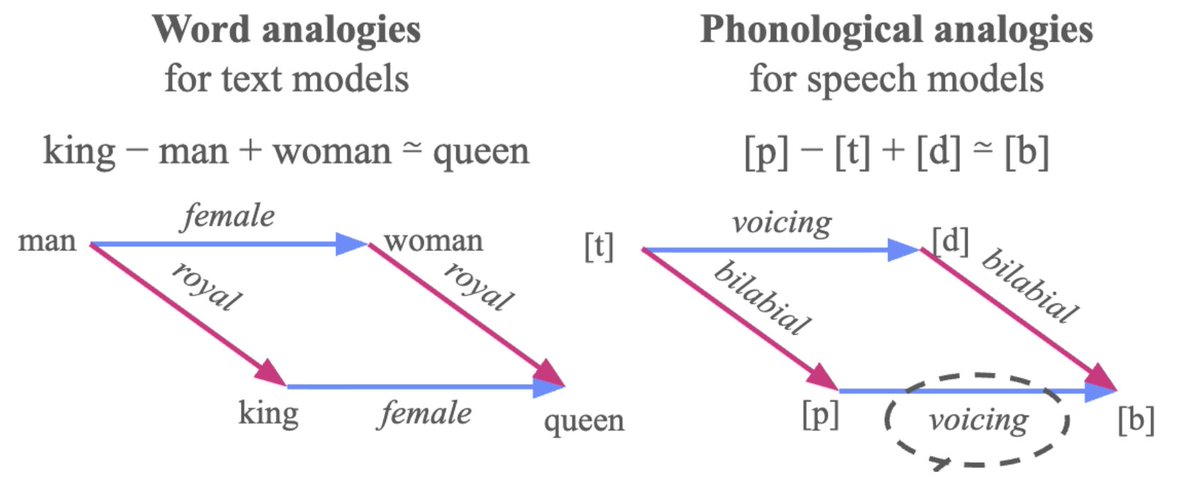
𝐒𝐞𝐥𝐟-𝐬𝐮𝐩𝐞𝐫𝐯𝐢𝐬𝐞𝐝 𝐒𝐩𝐞𝐞𝐜𝐡 𝐌𝐨𝐝𝐞𝐥𝐬 𝐚𝐫𝐞 𝐏𝐡𝐨𝐧𝐨𝐥𝐨𝐠𝐢𝐜𝐚𝐥 𝐕𝐞𝐜𝐭𝐨𝐫 𝐌𝐚𝐜𝐡𝐢𝐧𝐞𝐬!
🗣️ Excited to be giving an invited talk this Thursday (March 19th, 3pm Amsterdam time)!
Huge thanks to @mariannedhk at Univ. of Amsterdam for the invite 🙏
Huge thanks for my wonderful coauthors, Eunjung and Cheol-jun, and my two favorite Davids, Mortensen 🐑 and Harwath 🤠 — best advisors I could ask for 🙏 Can't wait to see what we cook up next! 🚀
𝐒𝐞𝐥𝐟-𝐬𝐮𝐩𝐞𝐫𝐯𝐢𝐬𝐞𝐝 𝐒𝐩𝐞𝐞𝐜𝐡 𝐌𝐨𝐝𝐞𝐥𝐬 𝐚𝐫𝐞 𝐏𝐡𝐨𝐧𝐨𝐥𝐨𝐠𝐢𝐜𝐚𝐥 𝐕𝐞𝐜𝐭𝐨𝐫 𝐌𝐚𝐜𝐡𝐢𝐧𝐞𝐬!
🗣️ Excited to be giving an invited talk this Thursday (March 19th, 3pm Amsterdam time)!
Huge thanks to @mariannedhk at Univ. of Amsterdam for the invite 🙏
🧵 Together, both papers take a step beyond the usual "what info do S3Ms encode" probing paradigm. We aim to answer how is that info actually encoded geometrically? Come see for yourself Thursday! 👀
Slides: https://t.co/N8LiKPcpid
🚀Apply to CMU LTI’s Summer 2026 “Language Technology for All” internship🎓Open to pre‑doctoral students new to language tech (non‑CS backgrounds welcome). 🔬12-14 weeks in‑person in Pittsburgh; travel + stipend paid.💸Deadline: Feb 20, 11:59pm ET. https://t.co/7SuItDHH98
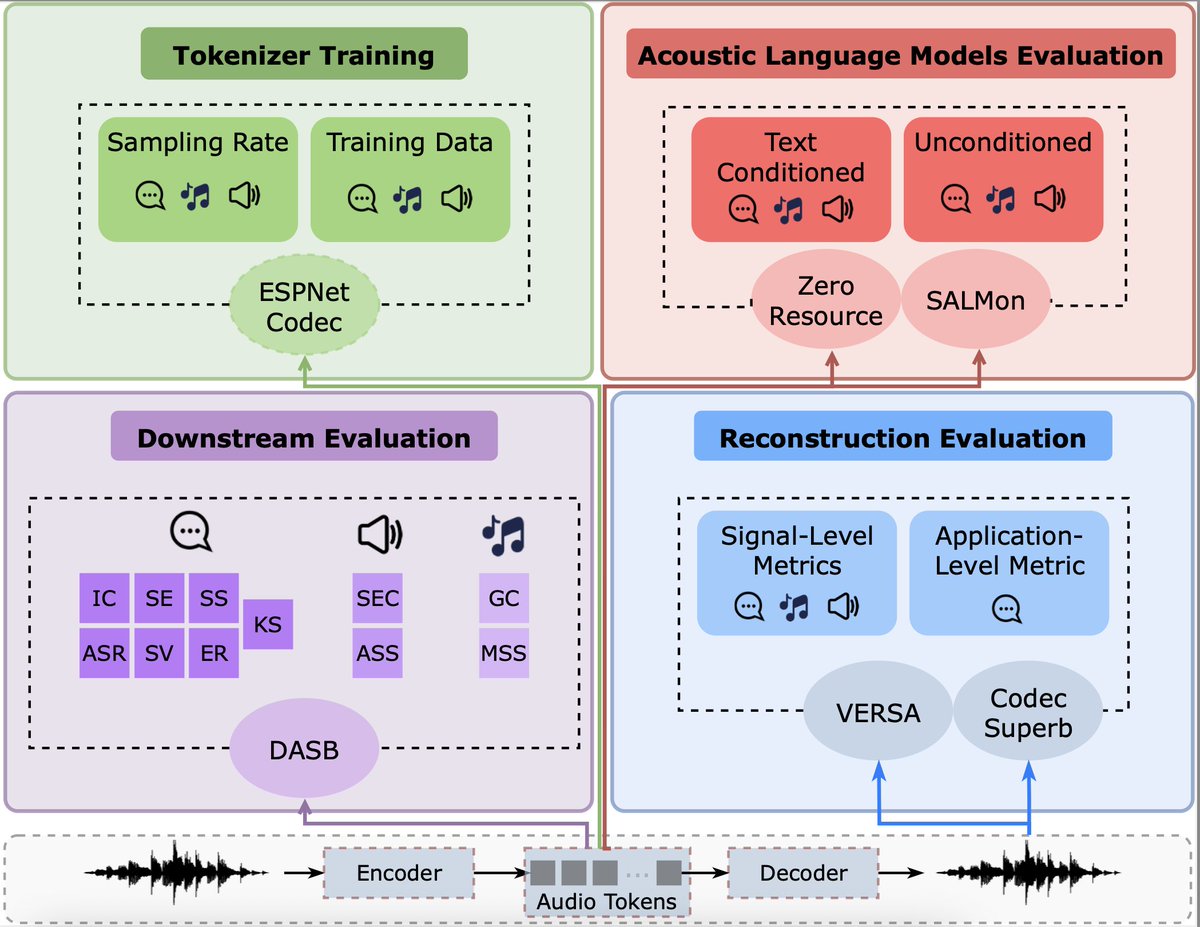
🎵💬 If you are interested in Audio Tokenisers, you should check out our new work!
We empirically analysed existing tokenisers from every way - reconstruction, downstream, LMs and more.
Grab yourself a ☕/🍺 and sit down for a read!
Excited to receive the Best Student Paper Award at #Interspeech2025 I started the OWSM project in 2023. It took me great effort to design a robust and scalable training framework using ESPnet, prepare unified data formats, and conduct large-scale training with academic resources.
Our work on OWSM v4 received the Best Student Paper Award at #Interspeech2025! 🏆🎉
Huge congratulations to the team! 🚀👏
I’m especially happy to see our open science efforts for speech foundation models recognized by the community. 🙌
🔗 https://t.co/wx7uN7PYNw
I will be presenting 3 papers from @WavLab at #Interspeech2025 🇳🇱
One is OWSMv4 (led by @pengyf21), nominated for best student paper
https://t.co/UF9JHNrP8b
It focuses a lot on data cleaning, particularly for non-English languages
It will be an oral on Tues 15:10 at dock 10B.
This wouldn't have been possible with my awesome co-first-author @mmiagshatoy and wonderful supervisors @shinjiw_at_cmu and Emma Strubell!
I'll see you at Rotterdam, Wed 17:00-17:20 Area8-Oral4 (Streaming ASR)! (10/10)
We also verified that DSUs are learnable with smaller weights (# of layers), i.e., more lightweight! This implies that we're using self-supervised models inefficiently when extracting DSUs. (8/n)
There's also bunch of engineering tricks that can improve the performance. We provide a pareto-optimal baseline after applying all the available tricks, positioning our work as a foundation for future works in this direction. https://t.co/Nbi8Mo06Qi (9/n)