RAG is not dead. Every AI Agent is using RAG, it's just that it's no longer just the hyped vector database (it never was).
After more than 2 years working on projects with LLMs+RAG I've seen so many scenarios that I can categorize them based on the documents the agent has to use to extract information. Here I explain all the RAG cases I've encountered across different projects and how to solve them:
1. Very few documents and they're not long: The easiest of all. Pass the complete documents in the prompt. Separate the documents section with an obvious marker and tell the model in the prompt that the documents are under that marker. Nowadays the best models handle prompts with a huge number of tokens quite well.
2. One very long document: Ideal for embeddings. Convert the document into embeddings and store them in a vector database. When you need to extract information, pull the 10 most similar chunks, run a re-ranker on those 10. Return the 3-5 most similar embeddings after re-ranking to the LLM to generate the response.
Extra: if you want a better response and the token count allows it, use the embeddings' metadata and pass the full chapter or section to the LLM.
3. The documents are not few, but they're relatively about the same topic: You can also use embeddings — convert all documents into embeddings and store them in a vector database, but it's important to add metadata indicating which document each embedding belongs to. When a question is asked, it will pull multiple embeddings that may belong to different documents, so it's important to identify which document is being referenced. You can return that as-is or do a second pass where you redo the search but only within the documents from which the first embeddings were extracted.
4. The documents are not few, and they cover very different topics: Here, mixing all the embeddings from all documents may not yield good results, so it's better to first filter which documents make the most sense to search. So with the query you do a pre-filtering step with an LLM along the lines of "I have these 100 documents, here are their descriptions, which documents make the most sense to answer this question" — the LLM returns 3-5, and you use the vector metadata to only search among the embeddings of those 3-5 documents.
5. An incredibly long and complex document (diagrams, tables, images): The most complex. Several steps are required — first you need to create an "index" to split the document into sections or chapters; it may already have one (for example, a large manual), in which case you can use that same index. Then convert everything into embeddings. If there are images/tables/diagrams, which are hard to convert into embeddings, you need to store an embedding with a description of the object. If that embedding gets selected, you need to use the metadata to know it's something other than plain text and go retrieve the actual image.
There are 2 complex things here: how to split the giant document automatically (manually it's straightforward), and how to detect when there's an image that needs a description.
I've had to wrestle with this last case twice, it's not easy, but when you pull it off it's tremendously satisfying.
A tip to avoid constantly authorizing Claude Code for everything, while still keeping things secure and not using --dangerously-skip-permissions:
After completing a task where Claude asked for permissions every 10 seconds, ask it to create a parameterizable script to do the same thing in the future, literally "now create a script so I can do the same thing we did here quickly and easily." The idea is for it to be parameterizable so you can pass arguments and avoid hardcoding things.
For example, in the image example I ask it to search production logs for an error — it always runs the same commands, but the time range and keywords change, making it perfect for a script. So in the future I just tell it to run the script with X parameters, authorize it to run that script in the permissions prompt, and that's it!
I finally found out why shipping to production code written by AI without reviewing it is worse than trusting your human colleague to ship their code to production without you reviewing it.
Because in the human's case, their reputation and job are on the line.
I think we trust that a human will do everything possible (within their capabilities) to make sure their code doesn't break anything in production, because if it does, they have to be held accountable. And if the mistake is bad enough, they could lose their job.
If an AI makes a serious mistake, the most it'll do is say "oh you're absolutely right! I shouldn't have done that, do you want me to roll back the changes?”, when production is already on fire. You can't hold Claude Code accountable or fire it, you'll keep using it.
In the end, the human who sent the prompt that caused the error might be the one held responsible, but are they really responsible? Maybe they're only responsible for "next time you need to look more carefully at what the AI writes," which is very different from "what were you thinking, truncating the customers table just to make the test stop failing?!!"
Reading about Claude Mythos raises a concern somewhat related to vibe-coding. If someday the super AI Mythos tells us "I found a vulnerability in your software's code.. in this part of the code you do A, B, C and an attacker can do D, do you want me to fix it?", will we be able to read and understand the vulnerability and the solution the AI is offering?, or are we just going to say "yeah, go for it", and fully trust that the AI is doing the right thing.
Why is this different from what happens today with AI and software development? Because if I'm building a React webapp with a Rust backend and the AI adds features, a software engineer will eventually be able to understand what it's doing — if they sit down and read the code carefully, they'll get it. If the AI is building a compiler from scratch, a human will eventually be able to understand the code.
But if we read the blogpost about Mythos, they say it found a vulnerability in FFmpeg that has existed for 16 years, because the vulnerability is extremely obscure — here's the commit: https://t.co/t4lo09qpIA
To understand it you need to know how FFmpeg works, how the H.264 codec works, know C. To discover it in the first place you need to know all of that and know where to look.
My point is that when we're talking about cybersecurity it's different from a SaaS — will there come a point where we start vibe-cybersecuring? Just accepting whatever the AI says because actually trying to understand it will take 15 hours spread over 5 days for a single commit.
What I do know for certain is that one of the fields that's going to explode is cybersecurity, and AI cybersecurity specifically — the amount of software being built is exploding, and along with it, the vulnerabilities.
blogpost: https://t.co/hIQmJaqvQS
Anthropic's research commit in FFmpeg code: https://t.co/t4lo09qpIA
@hieudinh_ If I’m not mistaken I think every registered agent will charge you a yearly fee. You also need some business address for your LLC, I think because of the IRS, but that $39 a month is too expensive, there are cheaper options. Good luck!
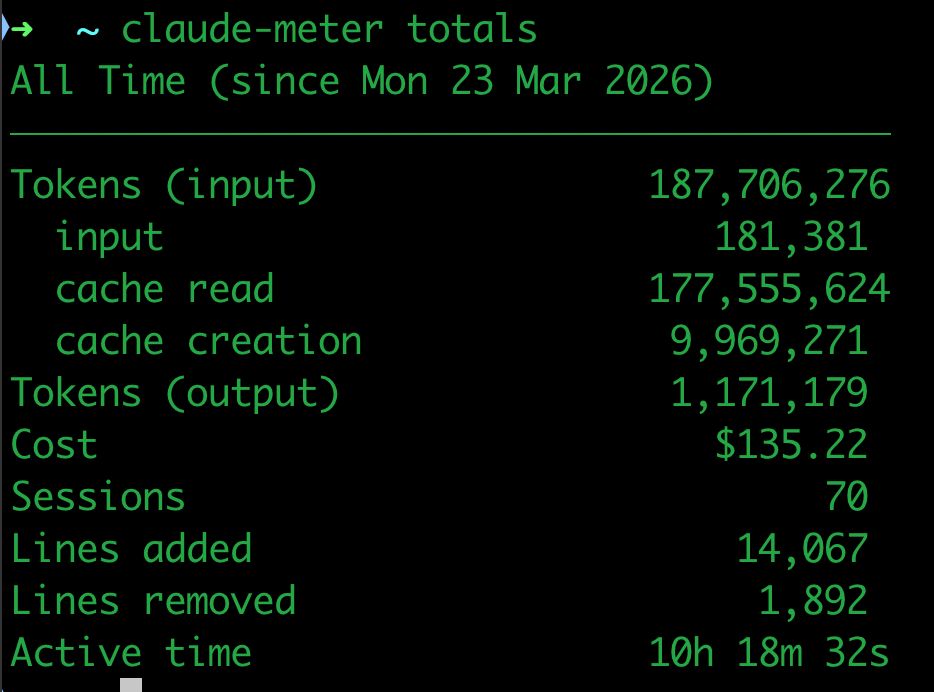
In 10 days I've used 187,706,276 input tokens and Claude Code has generated 1,171,179 tokens for me. It has cost USD$135.22.
I made a tool that uses Claude Code's OTLP monitoring system to keep track of how many tokens I use.
After the news came out that one Claude Code user was costing Anthropic around USD$5,000, I got curious to see if there was any way to know how much I was spending, and there is — Claude Code already has options for monitoring, more info here: https://t.co/zTGG2QpJyX
The tool is written in Rust and you need to run a local server that receives the monitoring data from Claude. Everything is local and memory usage is super minimal.
Download claude-meter here: https://t.co/vU3t34cVpY
What catches my attention is that the active time is 10h 18m 32s — that doesn't sound like much, considering I use Claude Code every day across different projects at the same time. But I also realize I spend a lot of time thinking about prompts, looking at the code, and deciding what I'm going to ask for. And of course there are also moments of manual testing.
This reminds me of that classic software engineering quote that goes something like "You spend much more time reading code than writing it", or also "Code is written once, but read many times."
We shouldn't send API keys or passwords to Claude Code.
I know it's super convenient to tell it "this is the API key for service X, add it".
But besides the obvious —that info goes to Anthropic's servers— Claude stores the chat history in plain text at ~/.claude/history.jsonl, yup, go check the file.
And on top of that, if Claude is adding those API keys directly to a .env file, also go take a look at ~/.claude/file-history/, which is where Claude creates backups of the files it edits, somewhere in those folders there's the session, and inside it the .env file backed up in plain text.
The Claude Code source code leaked!
And someone uploaded it to their GitHub: https://t.co/S9shkPGWyU
And someone created documentation on how it works: https://t.co/vxJQXAxweC
Internet people are fast.
12/ Use --bare to speed up SDK startup by up to 10x
By default, when you run claude -p (or the TypeScript or Python SDKs) we search for local CLAUDE.md's, settings, and MCPs.
But for non-interactive usage, most of the time you want to explicitly specify what to load via --system-prompt, --mcp-config, --settings, etc.
This was a design oversight when we first built the SDK, and in a future version, we will flip the default to --bare. For now, opt in with the flag.
Everyone building a SaaS with Claude Code and saying "Software engineers are cooked, look at this product I built in just a few hours," and "…it has auth, it's integrated with a Supabase database, with Stripe, it has analytics, it sends emails to my users."
That Supabase wasn't written in a weekend with Claude Code. The Postgres underneath it, ugh, there's no way you could vibecode it to the state it's in today. You have no idea how much code and infrastructure it's behind Stripe. The analytics libraries and the ones for sending emails? also not vibe-coded, and building them is no trivial.
And that Claude Code, yep, built by software engineers, maybe not typing every single line of code, but with a ton of engineering behind it.
You can build a SaaS or an MVP in a weekend thanks to all the existing tools that have been built over years by software engineers. Those developments are going to keep being needed and keep existing. Or try to ask Claude Code to vibe-code Postgres: https://t.co/A6UBfM7Pf5
@Barbapapapps Just give Claude Code the official documentation, and a couple of tutorials, and tell it to implement it. Then fix the UI directly in the code for improvements.
Maybe we should start putting under git the prompts we use in coding agents..
Within the code commits of the feature, add commits of the prompts we sent to Claude Code, or whatever agent, to build the software.
It would be interesting to see how an app gets built through the prompts.
Then we can analyze what the agent doesn't understand, what we explain poorly, what we always repeat. I can't think of what else, but it would be interesting.
There could even be a repository of prompt history for building apps:
"This is my SaaS for expense tracking, and this is the prompt history I used to build the SaaS"
I found a difference between using Gemini models versus GPTs.
We have an agent deployed (which we could really call a chatbot) on a Discord server for an online school. Students ask it things about the course or related to the content, and the chatbot searches the materials and responds.
We gave the bot a certain “personality”, the client spent a long time editing the prompt to get it to respond the way they wanted. The personality is very peculiar, almost like role-play. The school is about personal development, so the bot is approachable, warm, empathetic, among other traits. And it worked great, students love it and have already sent it thousands of messages. The bot uses GPT-4.1 and GPT-5.2.
Since we have a lot of infrastructure on Google, we thought about trying Gemini. Everything the same, we just swapped the model. Surprise: the bot lost a bit of its "personality." It sounds a little more robotic and follows the instructions too literally.
I find that OpenAI has done a pretty good job of giving their models “personality”, I think which is why ChatGPT can be a bit annoying sometimes: too many emojis, then fewer emojis, very agreeable, then a little cringe, etc.
Gemini, on the other hand, I think has less personality, but it's very good for workflows, for calling tools, and for figuring things out when something isn't working. It's given us great results when it has a lot of tools available. It knows which one to call, and if it's not confident in its response, it calls the tool again with different parameters, and so on. It also takes more time, though.