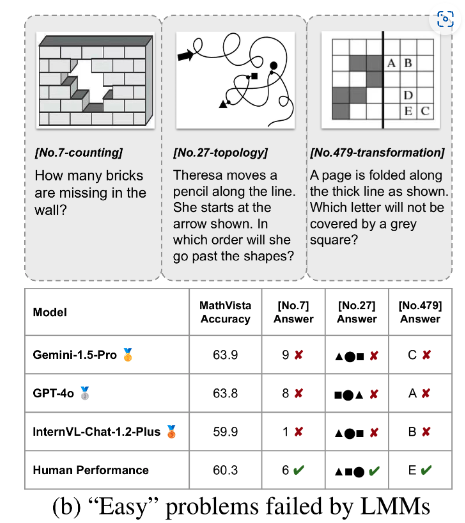
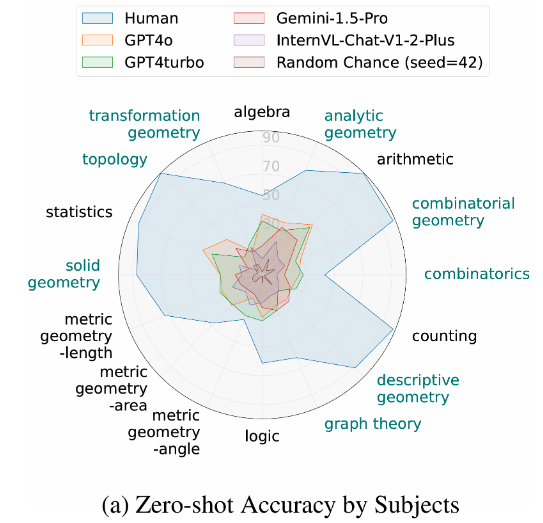
Our MathVision benchmark is accepted by NeurIPS DB Track, 2024! We show a notable performance gap between current LMMs and human performance on simple math problems with visual context.
Dataset: https://t.co/vhCqwCHwSU
Paper: https://t.co/GB2nyWxoGp
This is something I wanted to study long since I ever read the original knowledge distillation paper in 2015.
Finally we've done it - with @TaiMingLu we thoroughly study the necessity of distillation from a "stronger" teacher
Photography is deeply personal. It’s about people, relationships, and moments that matter — shaping how we remember the world and the people around us.
So excited to finally share what we’ve been working on - a personalized photo generation and editing model designed for your own photography. The idea is simple: your photos should still feel like you - preserving your identity, your expression, your story, while giving you the freedom to shape the image around it, or reimagine it.
What excites me most isn’t just the ability to generate something entirely new, but the chance to fix the small, real things — the missed moment, the person who wasn’t there, the expression that didn’t quite land — and finally arrive at the photo you had in your head all along.
Introducing Cambrian-S
it’s a position, a dataset, a benchmark, and a model
but above all, it represents our first steps toward exploring spatial supersensing in video. 🧶
The Foundation Model Team @🍎Apple AI/ML is looking for a Research Intern (flexible start date) to work on Multimodal LLMs and Vision-Language. Interested? DM me to learn more!
Last year at @Apple MLR, we published a number of interesting papers like AIM, AIMv2, and Scaling laws for: Sparsity, Native Multimodal Models, Data mixing.
Today the team has open-sourced the training codebase we used for conducting this research!
https://t.co/WNvOWMkgm3
In this report we describe the 2025 Apple Foundation Models ("AFM"). We also introduce the new Foundation Models framework, which gives app developers direct access to the on-device AFM model.
https://t.co/nEbtxuGrjD
Our computer vision textbook is now available for free online here:
https://t.co/ERy2Spc7c2
We are working on adding some interactive components like search and (beta) integration with LLMs.
Hope this is useful and feel free to submit Github issues to help us improve the text!
🌟Thrilled to share that SAM 2 was awarded a Best Paper Honourable Mention Award at #ICLR2025, one of 6 papers recognized out of 11000+ submissions!
👏This project was the result of amazing work by an exceptional team at @AIatMeta FAIR: @vgabeur ,
@YuanTingHu1,@RonghangHu, @wrong_whp, Tengyu Ma, @HaithamKhedr,@raedle, Chloe Rolland, Laura Gustafson, @junting9, @KalyanVasudev, @alcinos26,
@chaoyuaw, @inkynumbers, Piotr Dollar, @cfeichtenhofer.
🚀It was inspiring to hear from researchers at ICLR applying SAM to a diverse array of real-world challenges—from medicine and semiconductor manufacturing to robotic navigation, enterprise data annotation platforms, and video editing. If you're using SAM for an innovative application, please reach out, we'd love to hear about it!
I am looking for strong PhD interns to join Apple MLR late 2024 or early 2025! Topics will be around training large-scale diffusion/flow matching models broadly speaking and you’ll be in the bay area (Cupertino/SF). Apply here: https://t.co/5gKIBnK6oP. [1/5]
Looking for a 2025 summer research intern, in the Foundation Model Team at Apple AI/ML, with the focus of Multimodal LLM / Vision-Language. Phd preferred.
Apply through https://t.co/m243cnfXay
Also email me your resume to [email protected]! 😊
So much fun at #AdobeMAX sneak! As a researcher, this is so far the biggest stage I have ever stepped on. Turns out it’s easier to interact with 10k+ audiences than with 1 for an introvert :p Grateful for all the applause, energy, and suports!
I am presenting at #AdobeMAX next week! Get a sneak peak to our latest research on image composition and relighting on Oct15th at MAX sneak session (5.30 to 7 pm EST).
Online registration (free): https://t.co/d2VCC0rFzO