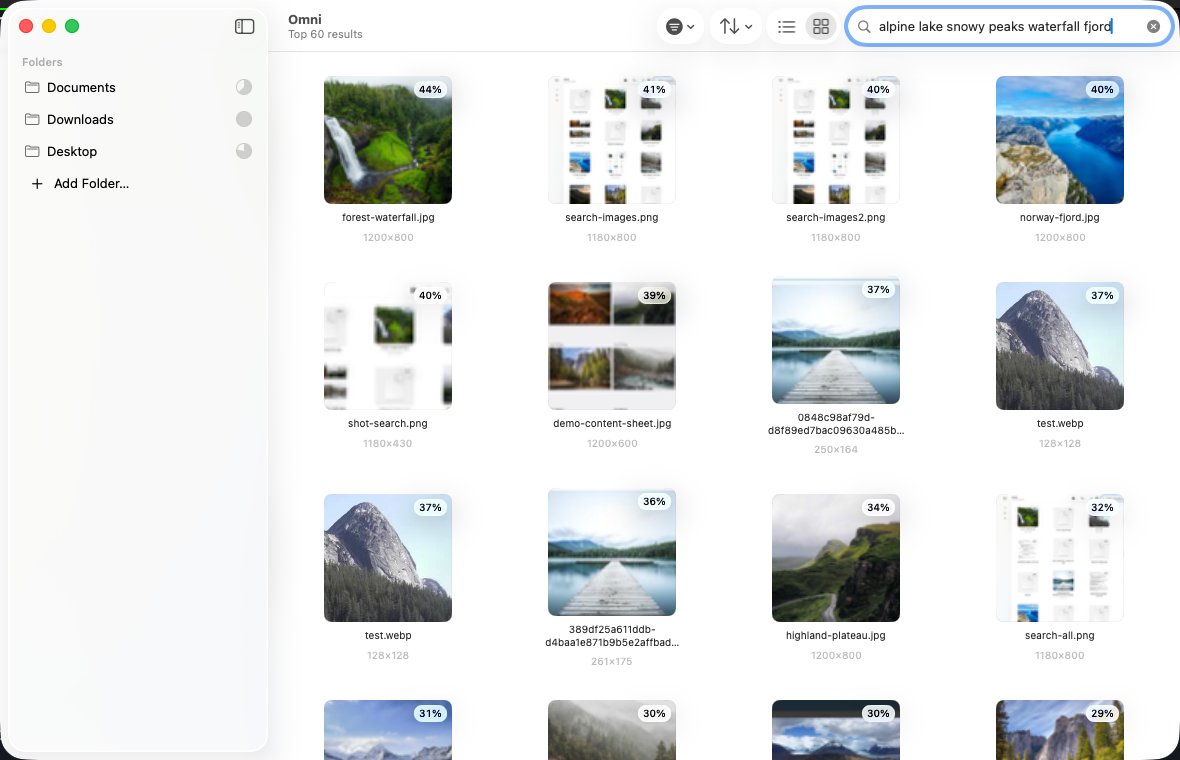
在 Apple Silicon Mac 上对本地文件进行全模态语义搜索,无需联网、不上传数据。
https://t.co/2F6OElA3CP
支持对文本、代码、PDF、图片、音频和视频进行统一语义检索。所有文件通过一个共享向量空间嵌入,模型在 Mac GPU 上通过 MLX-Swift 原生运行,无需 Python、服务器或云端依赖。
alguien acaba de construir la App Store de Claude Code.
una librería gratuita con más de 1.000 agentes, habilidades, comandos y herramientas listas para usar.
un solo comando para instalarlo todo.
100% gratis👇🏼
420.2 tok/s on a 550B model. ⚡️
Nemotron-3-Ultra-550B-A55B reaches 420.2 tok/s powered by BLACKBOX AI Inference Engine.
Blackbox now delivers the fastest inference in the industry, outperforming every other provider, including on smaller-parameter models.
Check our blog in the comments.
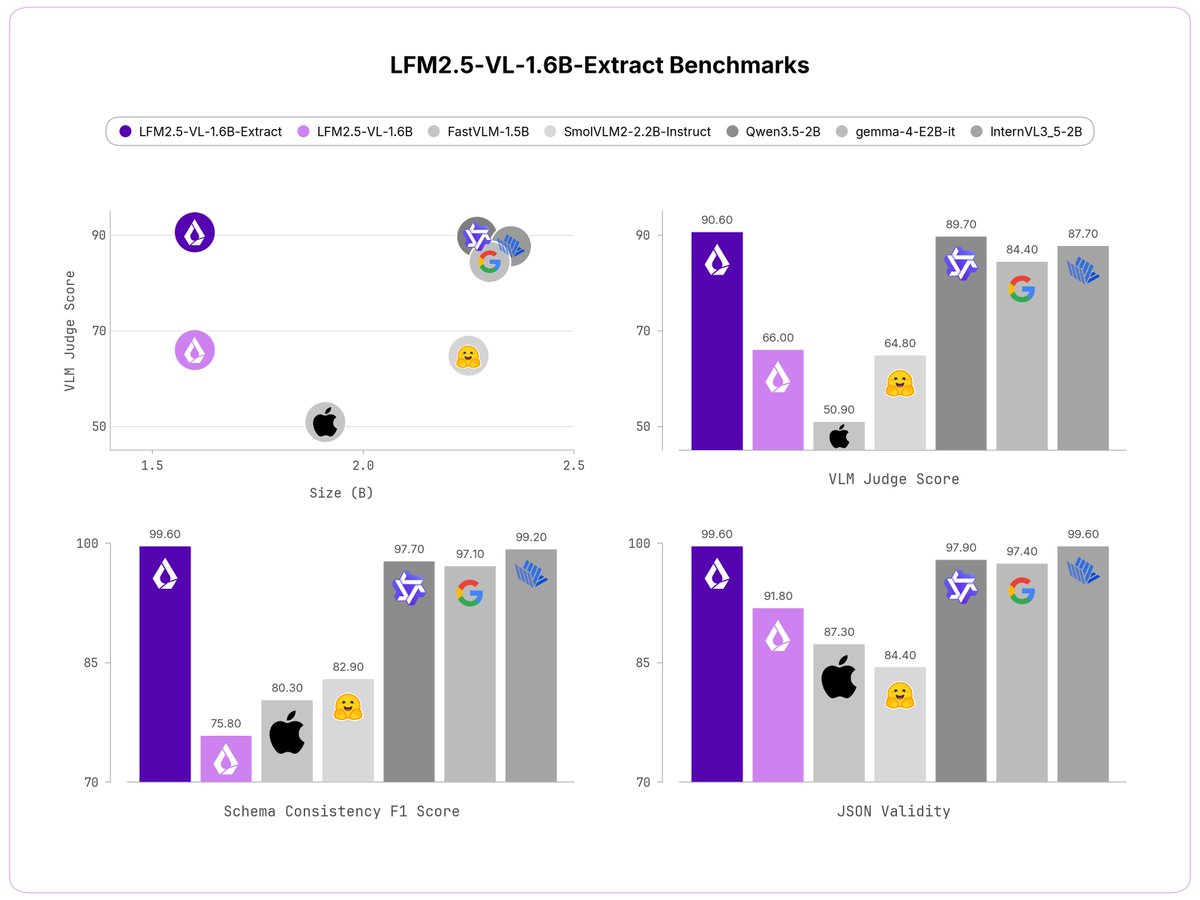
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
🎉 The vLLM community just got a free course, built by @RedHat_AI with @DeepLearningAI. It walks through the full optimize → deploy → benchmark lifecycle for serving open models.
Three labs, each on a live vLLM server:
- Compress: quantize a Qwen model with LLM Compressor, then measure the size vs. accuracy tradeoff
- Serve: deploy with vLLM's OpenAI-compatible API and watch continuous batching, PagedAttention, and prefix caching in the live metrics
- Benchmark: simulate traffic with GuideLLM and check quality with lm-eval
A lot of the work went into visualizing what actually happens under inference, thanks to @cedricclyburn: how tokens flow through the model, how the KV cache grows in GPU memory, and what changes when you move from FP16 to INT8/INT4.
~1.5 hours, 9 lessons, 3 labs. Free on https://t.co/pGAwqbmMdc.
📝 Read more: https://t.co/r8ITc2prI2