1/n 🚀 Excited to share our latest work: DINO-Foresight, a new framework for predicting the future states of scenes using Vision Foundation Model features!
Links to the arXiv and Github 👇
#ECCV2026 paper: A scalar per patch from pre-trained ViTs enables fast moving navigation in the real world
966 *REAL* nav episodes by S. Janny with Dino-v3, Dino-v2, DUNE, VC1, AM-RADIO encoders show that patch features can be bottlenecked to 1 value ➡️ affordances.
1/8
🎉Re2Pix accepted at #ECCV2026!
💡Should a world model predict future dynamics and render pixels simultaneously? Re2Pix says no. Forecast in VFM semantic space first 🧠, synthesize pixels second 🎨
Updated Paper and code coming soon. Details👇
1/n 🔀 Pixel or latent world models?
Video world models fall into two camps:
• generate photorealistic frames
• predict semantic features of the future (e.g., DINOv2)
Why choose one?
We introduce Re2Pix, a hierarchical approach that combines both. 🧵👇
Academia optimizes for novelty,
which has become increasingly orthogonal to making things work. In practice it rewards benchmarking-chasing, optics-maxing, and flag-planting.
Sadly a major bitter lesson of robotics is: insights from the small-data, bad-system regime don’t transfer to the big-data, good-system one. The novelty we reward and the progress we need are pulling apart.
In the last couple of months, we have witnessed significant advances in Industry-scale World Models. Yet, for the broader community, the gap between reading about these models and deploying them remains disappointingly wide.
Today we're releasing Nano World Models: a minimalist, batteries-included repo for advancing world model science.
🧵 (1/9)
py123d: D. Dauner et al. did all the dirty work to unify the highly heterogeneous autonomous driving datasets into a single efficient data format.
nuscenes+nuplan+WOD+Physical AI AV, etc., are all there.
This is how you accelerate open-source AD research
https://t.co/tjGbc9vyvb
New blog post out! 🍌
What if you could replace your entire computer vision pipeline with a single model and a text prompt?
No more chaining separate models for segmentation, depth estimation and surface normal estimation. Just one model, one prompt.
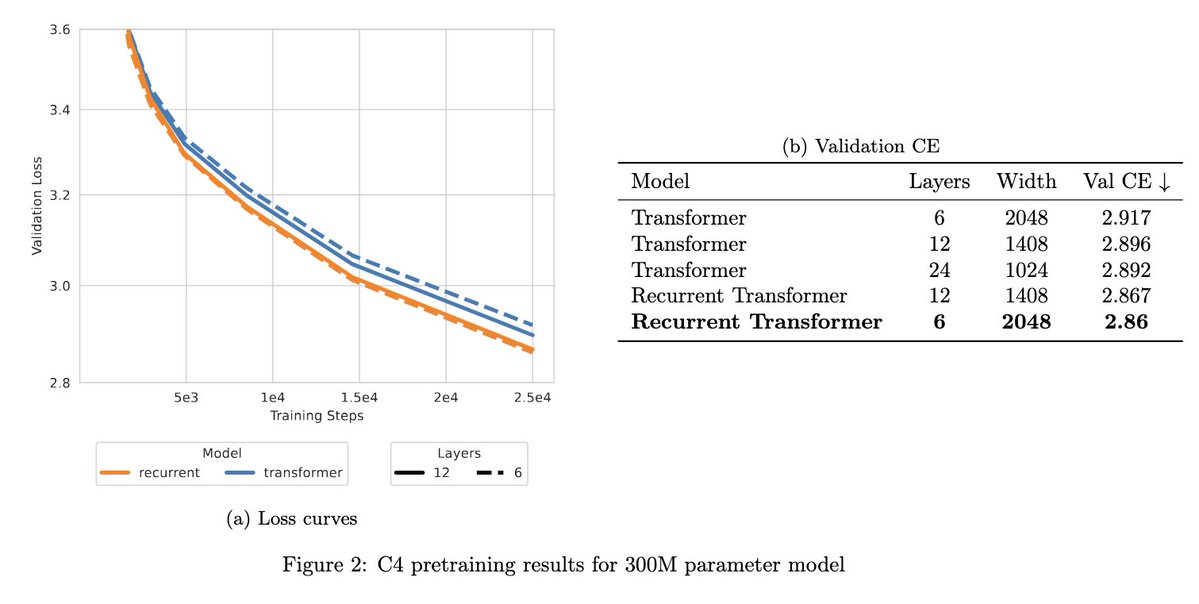
1/8 Introducing Recurrent Transformer (RT). At 300M params, RT improves validation CE over standard Transformers. The best RT model is only 6 layers, but wider at 2048 — beating deeper 12- and 24-layer Transformers by trading depth for width.
1/n
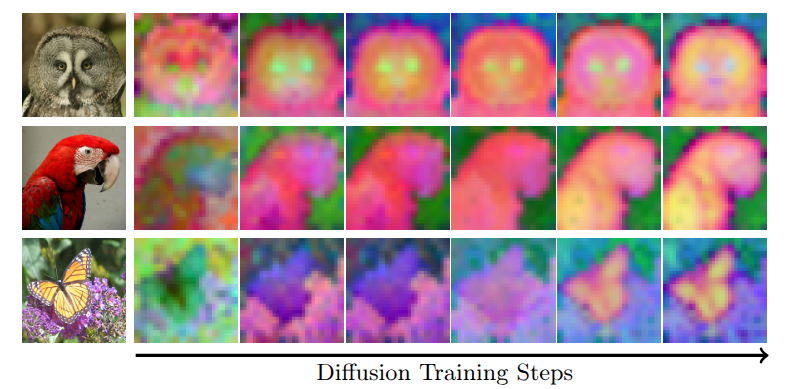
Introducing CoReDi: Coevolving Representations for Joint Image–Feature Diffusion
Joint diffusion boosts image generation by injecting semantic features.
But one assumption goes unquestioned: the feature space is fixed.
What if it was learned instead? 🧵👇
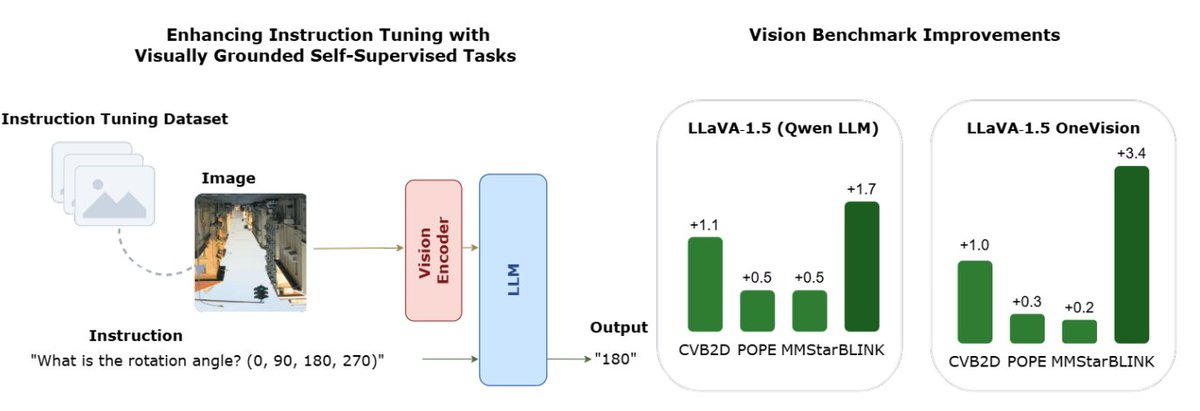
Revisiting “old-school” self-supervised tasks (rotation prediction) in a new way—using them during instruction tuning to improve visual grounding in MLLMs.
Simple idea with nice gains on vision-heavy tasks 👀
Kudos to @sophia_sirko for leading this work
https://t.co/jXdxQYLpYm
1/n New paper - V-GIFT 🎁
Self-supervised tasks like rotation prediction or colorization were big in 2018.
Do they still matter?
Yes.
We turn them into visual instruction tuning data for MLLMs.
Result: models rely more on the image and perform better on vision tasks 👀
9/n 🎯 We show that explicitly modeling hierarchical semantic structure, can build more efficient and temporally consistent video prediction systems
Paper: https://t.co/tgVtLyPUdV
Code (To be released soon!): https://t.co/6MeEpk1yKT
Joint work with @SpyrosGidaris and N. Komodakis
1/n 🔀 Pixel or latent world models?
Video world models fall into two camps:
• generate photorealistic frames
• predict semantic features of the future (e.g., DINOv2)
Why choose one?
We introduce Re2Pix, a hierarchical approach that combines both. 🧵👇
8/n 👀 Here's what it looks like in practice! Bottom left shows the predicted DINOv2 semantic features guiding the generation. Re2Pix (bottom right) preserves scene structure and object boundaries much better than the baseline!