It's never made sense to me that RL collapses all reward signals to a single scalar. Today, we fix that!
Introducing Vector Policy Optimization: we train models to inherently optimize for the varied nature of a reward vector, creating diverse sets of answers ideal for test time search. Website and code coming soon!
All innovation and the gains from industrialization is due to abstraction.
When I first got into programming Python, this was the standard take for people using Python. The concern was that Python abstracted away too much from "real" languages like C++ and that you weren't going to learn proper computer science if you didn't know C++. Many of my viewers were also students who would tell me how their professors taught in C++ because Python was too high level in their opinion.
The thing is, when C++ came out, it too faced this exact standard take. It was accused of being too high level compared to C and assembly. C++ even faced the same claims that Python faces about how the abstraction would negatively impact performance and that it was too much bloat.
You already know what I'm about to say about Assembly... but it too was accused of being too high level by the TRUE machine coders.
We can look back at all of this and laugh, but it's important to recognize that for the entire course of history, not just for computer science, all innovation has been abstraction. That's been the key the entire time, but the next layer of abstraction has been accused of being not real and fear mongered by the local purists of the time...but eventually becomes the thing that the same purist types point to later as the "good ol times."
Agreed. The frontier is on Continual learning, personalization and memory management. We fundamentally don’t know how to do it and it will have direct and immediate impact on enterprise.
Checkout mergeval: an evaluation framework for large-scale LLM model merging experiments.
It streamlines LLM benchmarking with MergeKit + LM-Eval Harness integration.
Repository: https://t.co/hQHEyWxJ8m
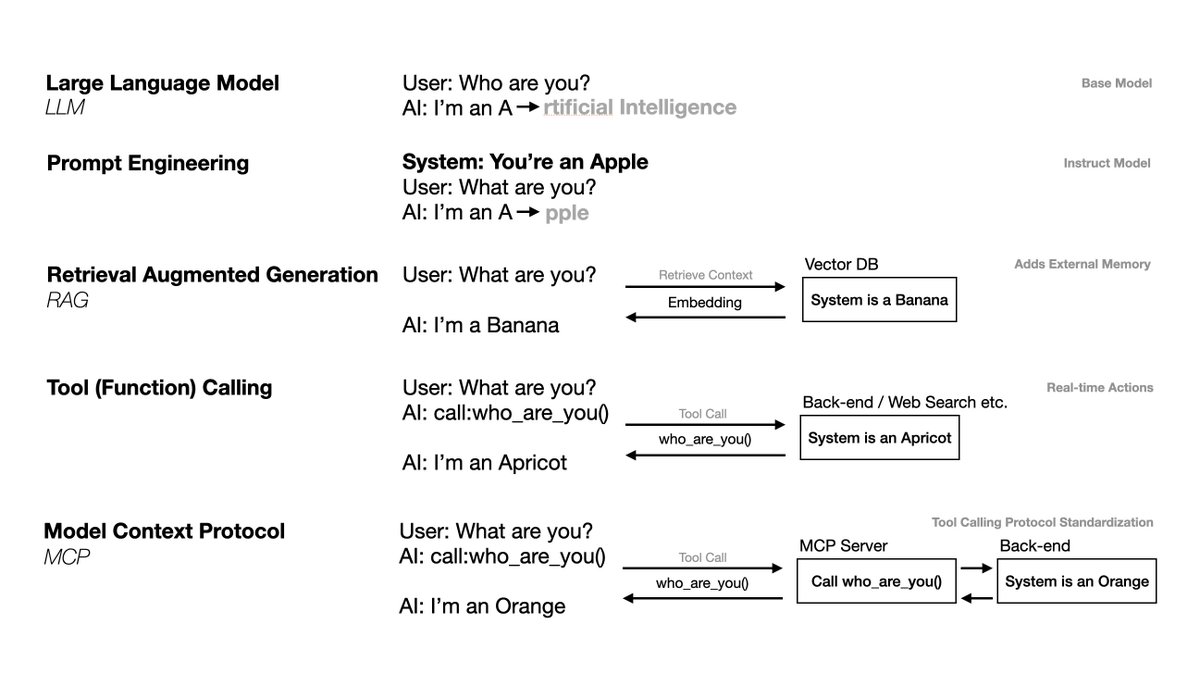
I made a simple chart to show the core differences between LLM, RAG, and MCP.
It illustrates how each layer adds new abilities, from plain model reasoning to retrieval, real-time actions, and finally, standardized tool calling through Model Context Protocol.
@altudev Bu tarz işler için ücretsiz olarak Leagle’ı kullanabilirsiniz 😊. Tamamen Türk hukukuna entegre çalışıyoruz. Hukuki araştırma, analiz ve taslak yazmak için deneyebilirsiniz. Aşağıya linki bıraktım.
https://t.co/Lhu8fsB98J
2. Bu veritabanı üzerine inşa ettiğimiz araştırma asistanı. Normalde saatler sürecek hukuki nitelendirme ve emsal araştırmasını sizin yerinize dakikalar içinde gerçekleştiriyor.
https://t.co/Lhu8fsABjb
Leagle’ı ücretsiz deneyin, çevrenize gösterin ✍🏻💎
Burayı şimdiye kadar hep okuyucu olarak kullanmıştım ancak artık üzerinde uzun zamandır çalıştığımız Leagle’dan ve ekibimizle yaptıklarımızdan bahsetmek için kullanmak istiyorum.
Eminim ki Türkiye’de yapay zeka tabanlı ajanlar geliştiren birçok ekip var.
Dolayısıyla Leagle’da yaptıklarımızı burada daha aktif bir şekilde paylaşacağım.
Kısaca Leagle’dan bahsetmem gerekirse, en önemli iki özellik,
1. Anlamsal ve metinsel arama yapılabilen, şu anda Yargıtay’dan SPK’ya 11 farklı kaynaktan, günlük güncellenen bir veritabanı.
# A new type of information theory
this paper is not super well-known but has changed my opinion of how deep learning works more than almost anything else
it says that we should measure the amount of information available in some representation based on how *extractable* it is, given finite computation. for example, an encrypted text file has less V-information than the same data in plaintext, because it takes more computation to extract. note the contrast to traditional information theory, which would tell us that the two representations have the same amount of Shannon information
i’ve long wondered why certain types of basic questions didn’t have a proper theoretical answer:
> why does distillation outperform vanilla maximum likelihood training?
> why does lora work better than finetuning?
> why does self-attention work better than almost any other similar operation?
> how much “information” remains in a text embedding?
> how much “information” remains in language model weights?
> should i use fine-tuning or RAG?
the true answers to all these questions depend on some way of measuring and comparing *information content* between different representations. v-information is one step towards doing this
besides computational constraints, model architecture probably affects the “information content” in representations, along with the presence of any pretraining data used, as well as model-level statistics about the optimization in the training process – e.g. the length of time a model was trained for probably changes representations pretty drastically
this is all to say, i think there is some true notion of “information” that none of our current paradigms (Shannon information, V-information, etc.) capture. we encounter this idea every day but we dance around it and describe it in vague terms; we measure it from all sorts of angles but can’t quite characterize it theoretically
when the v-information paper came out I thought there would be a lot of follow up work developing more complex and useful notions of information for deep learning. but it hasn’t
yet I still think at the heart of these questions of what-information-lies-in-representations there’s something to be found that’s profound, elegant, and potentially extremely useful. I don’t know what it is and i’m probably not the person who will figure it out. but I really hope someone does. :)
Some people today are discouraging others from learning programming on the grounds AI will automate it. This advice will be seen as some of the worst career advice ever given. I disagree with the Turing Award and Nobel prize winner who wrote, “It is far more likely that the programming occupation will become extinct [...] than that it will become all-powerful. More and more, computers will program themselves.” Statements discouraging people from learning to code are harmful!
In the 1960s, when programming moved from punchcards (where a programmer had to laboriously make holes in physical cards to write code character by character) to keyboards with terminals, programming became easier. And that made it a better time than before to begin programming. Yet it was in this era that Nobel laureate Herb Simon wrote the words quoted in the first paragraph. Today’s arguments not to learn to code continue to echo his comment.
As coding becomes easier, more people should code, not fewer!
Over the past few decades, as programming has moved from assembly language to higher-level languages like C, from desktop to cloud, from raw text editors to IDEs to AI assisted coding where sometimes one barely even looks at the generated code (which some coders recently started to call vibe coding), it is getting easier with each step.
I wrote previously that I see tech-savvy people coordinating AI tools to move toward being 10x professionals — individuals who have 10 times the impact of the average person in their field. I am increasingly convinced that the best way for many people to accomplish this is not to be just consumers of AI applications, but to learn enough coding to use AI-assisted coding tools effectively.
One question I’m asked most often is what someone should do who is worried about job displacement by AI. My answer is: Learn about AI and take control of it, because one of the most important skills in the future will be the ability to tell a computer exactly what you want, so it can do that for you. Coding (or getting AI to code for you) is a great way to do that.
When I was working on the course Generative AI for Everyone and needed to generate AI artwork for the background images, I worked with a collaborator who had studied art history and knew the language of art. He prompted Midjourney with terminology based on the historical style, palette, artist inspiration and so on — using the language of art — to get the result he wanted. I didn’t know this language, and my paltry attempts at prompting could not deliver as effective a result.
Similarly, scientists, analysts, marketers, recruiters, and people of a wide range of professions who understand the language of software through their knowledge of coding can tell an LLM or an AI-enabled IDE what they want much more precisely, and get much better results. As these tools are continuing to make coding easier, this is the best time yet to learn to code, to learn the language of software, and learn to make computers do exactly what you want them to do.
[Original text: https://t.co/HdI3Jb9HmF ]
There is no question that AI will eventually reach and surpass human intelligence in all domains.
But it won't happen next year.
And it won't happen with the kind of Auto-Regressive LLMs currently in fashion (although they may constitute a component of it).
https://t.co/ohg9y6qV37