How does RL improve OOD reasoning? How can we distinguish compositional generalization from length generalization? What makes a composition more learnable?
Check out our #neurips2025 workshop poster tomorrow!
🗓️Sat, 12/6, 8am-5pm
Efficient Reasoning
📍Exhibit Hall F (Spotlight)
MATH-AI
📍Upper Level Ballroom 6A
🔗https://t.co/anfP9VPrZw
Joint work with @kaur_simran25@prfsanjeevarora
I’m at NeurIPS 12/4-7! Excited to see old friends + meet new ones — DM if you’d like to grab coffee☕️
These days, I'm excited about synthetic data, distillation, and anything post-training! I’m also looking for a Summer 2026 internship, so reach out if you think I’d be a good fit
Kids use open textbooks for homework. Can LLM training benefit from "helpful textbooks" in context with no gradients computed on these tokens?
We call this Context-Enhanced Learning – it can exponentially accelerate training while avoiding verbatim memorization of “textbooks”!
A thread 🧵1/N
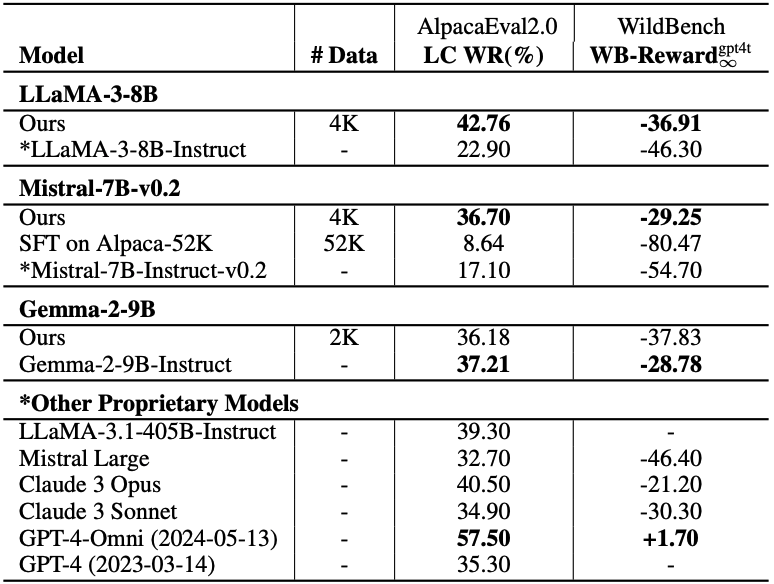
1/ New instruction-following dataset INSTRUCT-SKILLMIX! Supervised fine-tuning (SFT) with just 2K-4K (query, answer) pairs gives small “base LLMs” Mistral v0.2 7B and LLaMA3 8B performance rivalling some frontier models (AlpacaEval 2.0 score). No RL, no expensive human data. “Secret sauce”? Leveraging LLM metacognition!
Excited to share Instruct-SkillMix, a pipeline for generating high quality, diverse synthetic SFT data.
SFT on just 4K examples can boost LLaMA-3-8B-Base over LLaMA-3-8B-Instruct, yielding 42.76% LC win rate on AlpacaEval.
Paper: https://t.co/Yrd2JR2EQg
Additionally, we perform a preliminary exploration of difficulties in naive instruction-tuning. Replacing 20% of SFT data with “poor quality” data (i.e., deliberately sloppy and unhelpful) leads to super-proportional harm to the models.
[7/n]
Blog post about how to scale training runs to highly distributed settings (i.e., large batch sizes)! Empirical insights from my long-ago work on stochastic differential equations (SDEs). Written to be accessible - give it a shot!
https://t.co/KwLtlrHK0t
Excited to share our latest work: Skill-Mix, a new take on LLM evaluation that tests a model's ability to combine basic language skills!
Check out the Skill-Mix demo here: https://t.co/k0evUWZgZh
Does high rank on LLM leaderboards mean anything? Or is it just a game of "dataset contamination" and "Stochastic Parrots?"
Find answers via Skill-Mix, our evaluation of LLMs’ capacity to combine skills!
Paper: https://t.co/hy5iZWCFcY
Excited to announce that my first published paper (!!) will be a spotlight at the #NeurIPS2022 Higher-Order Optimization workshop on Dec 2nd! Huge thanks to my co-authors @kaur_simran25@__tm__157@saurabh_garg67@zacharylipton, paper thread coming soon!
https://t.co/fkPKOtYOqg
5/ We hope to inspire future efforts aimed at understanding the relationship between the max Hessian eigenvalue and generalization, and to spark conversation regarding whether this quantity should be treated as a generalization metric at all.
Is flatness indicative of generalization? Not necessarily.
Our experimental study calls the relationship between flatness (as measured by the max Hessian eigenvalue) and generalization into question.
https://t.co/ORln4ASVEq
4/ While methods motivated by flatness produce useful tools, the max Hessian eigenvalue does not provide a scientific explanation for improvements in generalization. Thus, it is evident that there is a deeper story behind why flatness seems to be fruitful intuition.
















![kaur_simran25's tweet photo. Additionally, we perform a preliminary exploration of difficulties in naive instruction-tuning. Replacing 20% of SFT data with “poor quality” data (i.e., deliberately sloppy and unhelpful) leads to super-proportional harm to the models.
[7/n] https://t.co/oWzuj0ktBf](https://pbs.twimg.com/media/GWplVHLa8AER_WQ.png)





























