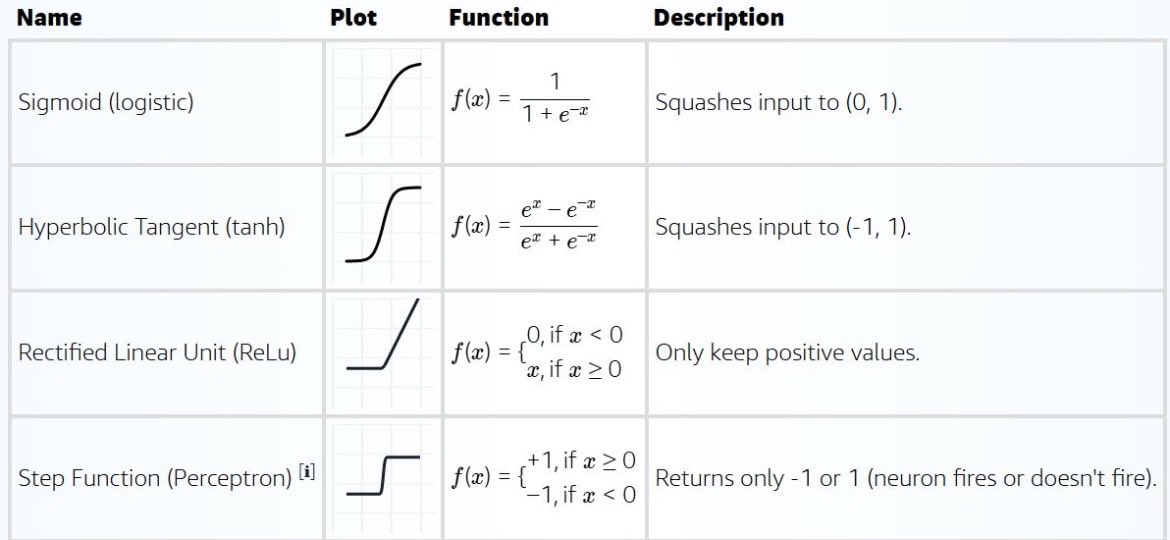
So choosing an activation function is not random.
It’s like choosing:
i) How should my model think?
ii) What signals should it care about?
Real-world quick mapping
- Hidden layers -> mostly ReLU
- Binary output -> Sigmoid
- Some deep nets -> variants like Leaky ReLU, GELU
But here’s the interesting part:
Each function is not just math, it changes how the network learns.
- Sigmoid/Tanh → can slow down learning (vanishing gradients)
- ReLU → faster, but can “die” (neurons stop activating)
Now here’s the catch:
If everything was linear.
no matter how many layers you stack,
your model would behave like a single layer.
Which means no real learning of complex patterns
So we introduce non-linearity
---> Sigmoid
- Outputs between 0 and 1
- Useful when you want probs
---> Tanh
- Outputs between -1 and 1
- Centered, slightly better flow of gradients
---> ReLU
- Keeps positive values, kills negatives
- Fast, simple, widely used
---> Step Function
- Either ON or OFF
- Early neural network idea
Think of it like this
Every neuron receives signals (numbers).
But it doesn’t pass everything forward.
It asks:
“Is this important enough?”
That decision = activation function
Here’s what we actually use in practice
→ ChatGPT / copilots → mostly autoregressive
→ Search / retrieval / ranking → mostly autoencoding
→ Translation / summarization pipelines → seq2seq
So it’s not one “Transformer” —
it’s three different ways of thinking about data.
Here’s what we actually use in practice
→ ChatGPT / copilots → mostly autoregressive
→ Search / retrieval / ranking → mostly autoencoding
→ Translation / summarization pipelines → seq2seq
So it’s not one “Transformer” —
it’s three different ways of thinking about data.
I let it evaluate meaning against labels that actually matter for the task.
That’s the power of zero-shot classification:
--> Turning labels into inputs
--> Making models adaptable without retraining