📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era.
A versatile foundation for agents that actually get things done:
🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it.
🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration.
⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding.
🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere.
API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio.
Go build something wild!🏃🏃♂️
📖 Blog: https://t.co/y3AupX3Pa0
✅ Qwen Studio: https://t.co/qpTnrCBjWt
⚡️ API:https://t.co/0sys00osKn
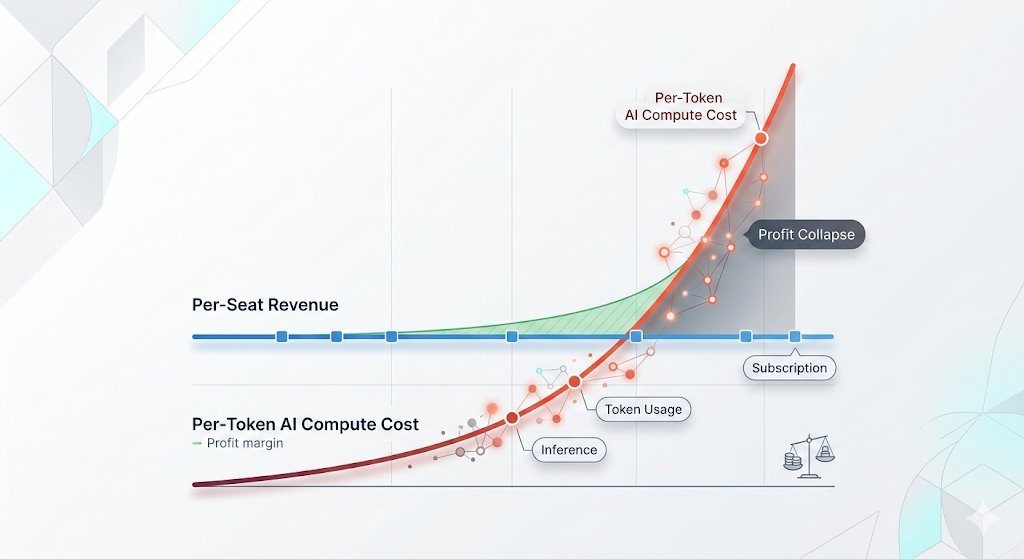
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
Introducing Director Mode in CapCut Video Studio.
Lights. Idea. Action!
Director Mode is an advanced workflow for AI drama series, films, and long-form videos, built on SOTA models like Seedance 2.0 and GPT-Image-2. You can:
→ Co-create with the agent to develop a professional script from just an idea
→ Once the script is confirmed, visualize characters, scenes, and props aligned to the story
→ Generate connected shot sequences based on the setup
→ Organize all elements and direct the agent to assembles the final edit
→ Re-prompt to refine frames at any stage, in your direction
If you can think it, you can direct it.
Now let the canvas roll.
RT+comment in 9h to get 200 credits in your DM
Note: Director Mode is available on CapCut Web globally, with US rollout coming soon
The 10 GitHub repos that turned my Claude Code from chatbot to engineering team.
Bookmark this. Repost it. Every developer will save more years than this list took to write.
1. anthropics/skills
Anthropic's official skill templates. 135K stars. The patterns Anthropic uses internally.
Repo → https://t.co/6VBUdubDG0
2. affaan-m/everything-claude-code
141K stars. The complete library of skills, agents, and commands every builder forks.
Repo → https://t.co/PaXno1QqDi
3. obra/superpowers
94K stars. Officially accepted into Anthropic's skills marketplace. Multi-agent orchestration without the boilerplate.
Repo → https://t.co/Z7i3fzf4s4
4. hesreallyhim/awesome-claude-code
The canonical curated list. 36K stars. Hand-tested. If a repo isn't on here, it probably doesn't work.
Repo → https://t.co/VhNjDoz7YM
5. Repomix
Packs your entire codebase into AI-ready context with one command. The reason Claude Code can actually understand your project.
Repo → https://t.co/znfB2pQA1n
6. claude-task-master
Multi-agent task orchestration. Turn one prompt into a coordinated team shipping a feature.
Repo → https://t.co/0xYzJpSX4z
7. ericbuess/claude-code-docs
Auto-updating mirror of Claude Code's documentation. Updates every few hours.
Repo → https://t.co/IHFcyKOQw1
8. travisvn/awesome-claude-skills
Community skill marketplace. 22K+ installs. The exact skills real builders use to ship.
Repo → https://t.co/L7DlZ982jy
9. forrestchang/andrej-karpathy-skills
109K stars. The most-starred single-file repo in GitHub history. Karpathy's coding wisdom as a Claude Code plugin.
Repo → https://t.co/unItpr073y
10. Marketing Skills Suite
23 specialized skills covering the entire marketing workflow. Install once. Ship like a team of 5.
Repo → https://t.co/VhNjDoz7YM
Here's the wildest part:
Claude Code alone is a chatbot.
Claude Code plus these 10 repos is a 10-person engineering team.
A senior engineer costs $300,000 a year.
A staff engineer costs $500,000 a year.
A full team costs millions.
You don't need to hire. You need to install.
The developers shipping the fastest in 2026 aren't smarter than you. They've just curated the right repos.
Save this. Share it with the developer in your life who deserves to ship faster.
100% free. 100% open source.
This open source killed the entire paid presentation tools industry.
It's called Presenton and it already has 5K+ stars on GitHub.
It turns prompts and documents into full presentations.
And instead of trapping you inside some shiny SaaS editor, it lets you export real PPTX and PDF files.
The wild part:
Your existing ChatGPT subscription can be used to sign in and generate decks.
No second subscription just to make slides.
Features:
• Prompt to presentation
• Document to presentation
• Editable PPTX export
• PDF export
• Custom templates
• Self-hosting
• Docker install
• API access
• BYOK
• Ollama support
What people pay for right now:
AI slide subscriptions every month.
Freelancers for simple decks.
Agencies for pitch decks.
Internal tools for repeat reports.
Presenton turns the whole thing into:
Sign in.
Generate.
Edit.
Export.
This is the kind of repo every founder, consultant, marketer, and student should bookmark.
GitHub: https://t.co/7ISsCFAcjq
Introducing Antigravity 2.0, a new standalone desktop application that delivers fully on that original glimpse of a truly agent-optimized experience.
Rebuilt from the ground up with multi-agent teams, scheduled tasks, native voice and one-click integration with other Google products.
Learn how to get started with Antigravity 2.0 👇
open sourcing Marlin-2B 🐟
a tiny VLM to extract structured information from videos
Marlin is finetuned for two questions devs want to ask in their videos: what is happening, and when?
Best open model in its weight class, competitive with Gemini-2.5-flash at only 2B params 🧵
Same here.
By way of background for those who care, I spent a lot of time last week with senior members of the Anthropic team to understand what they do to ensure Claude is good for humanity and was impressed.
Everyone I met was highly competent and cared a great deal about doing the right thing. No one set off my evil detector. So long as they engage in critical self-examination, Claude will probably be good.
After that, I was ok leasing Colossus 1 to Anthropic, as SpaceXAI had already moved training to Colossus 2.
We were a little slow on this, but we just got a technical blog post up with more details. Please take a look!
https://t.co/tPLzi0eNJR
We have a model card coming next week, and we are happy to take requests for any specific details there.
I am happy to answer any questions here!
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
𝗡𝗼𝘁𝗲𝗯𝗼𝗼𝗸𝗟𝗠 𝗷𝘂𝘀𝘁 𝗯𝗲𝗰𝗮𝗺𝗲 𝗺𝘆 𝗖𝗹𝗮𝘂𝗱𝗲 𝘀𝗸𝗶𝗹𝗹𝘀 𝗳𝗮𝗰𝘁𝗼𝗿𝘆.
I build a new AI expert in 5 minutes. Zero hallucinations.
Here's the loop:
→ Open NotebookLM and add your best sources (PDFs, articles, YouTube)
→ Ask it to write a skill.md file based only on those sources
→ Drop the file into your Claude Code skills folder
→ Claude follows the recipe every time
→ One skill per job (email, landing page, FAQ, support reply)
Stack 10 skills and Claude becomes a mini AI team.
The sources keep it grounded. No more made-up facts.
Most people are still re-prompting Claude every single chat.
Want the SOP? DM me. 💬
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights:
The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons:
1. menugen: an app that can be fully engulfed by LLMs, with no classical code needed: input an image, output an image and an LLM can natively do the thing.
2. install .md skills instead of install .sh scripts. Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say "just show this to your LLM". The LLM is an advanced interpreter of English and can intelligently target installation to your setup, debug everything inline, etc.
3. LLM knowledge bases as an example of something that was *impossible* with classical code because it's computation over unstructured data (knowledge) from arbitrary sources and in arbitrary formats, including simply text articles etc.
I pushed on these because in every new paradigm change, the obvious things are always in the realm of speeding up or somehow improving what existed, but here we have examples of functionality that either suddenly perhaps shouldn't even exist (1,2), or was fundamentally not possible before (3).
The second (ongoing) theme is trying to explain the pattern of jaggedness in LLMs. How it can be true that a single artifact will simultaneously 1) coherently refactor a 100,000-line code base *and* 2) tell you to walk to the car wash to wash your car. I previously wrote about the source of this as having to do with verifiability of a domain, here I expand on this as having to also do with economics because revenue/TAM dictates what the frontier labs choose to package into training data distributions during RL. You're either in the data distribution (on the rails of the RL circuits) and flying or you're off-roading in the jungle with a machete, in relative terms. Still not 100% satisfied with this, but it's an ongoing struggle to build an accurate model of LLM capabilities if you wish to practically take advantage of their power while avoiding their pitfalls, which brings me to...
Last theme is the agent-native economy. The decomposition of products and services into sensors, actuators and logic (split up across all of 1.0/2.0/3.0 computing paradigms), how we can make information maximally legible to LLMs, some words on the quickly emerging agentic engineering and its skill set, related hiring practices, etc., possibly even hints/dreams of fully neural computing handling the vast majority of computation with some help from (classical) CPU coprocessors.
China just open-sourced a trillion-parameter model that burns fewer tokens than your favorite "efficient" US model.
Ling-2.6-1T is now public, inspectable, and benchmarkable.
The closed-model moat just got smaller.
Did a very different format with @reinerpope – a blackboard lecture where he walks through how frontier LLMs are trained and served.
It's shocking how much you can deduce about what the labs are doing from a handful of equations, public API prices, and some chalk.
It’s a bit technical, but I encourage you to hang in there - it’s really worth it.
There are less than a handful of people who understand the full stack of AI, from chip design to model architecture, as well as Reiner. It was a real delight to learn from him.
Recommend watching this one on YouTube so you can see the chalkboard.
0:00:00 – How batch size affects token cost and speed
0:31:59 – How MoE models are laid out across GPU racks
0:47:02 – How pipeline parallelism spreads model layers across racks
1:03:27 – Why Ilya said, “As we now know, pipelining is not wise.”
1:18:49 – Because of RL, models may be 100x over-trained beyond Chinchilla-optimal
1:32:52 – Deducing long context memory costs from API pricing
2:03:52 – Convergent evolution between neural nets and cryptography