Last week's Boston Systems Reading Group kicked off with containers! We read through @b0rk’s zine on the subject and @ekzhang1’s SSH hypervisor came in handy for those of us experimenting with containers on Mac.
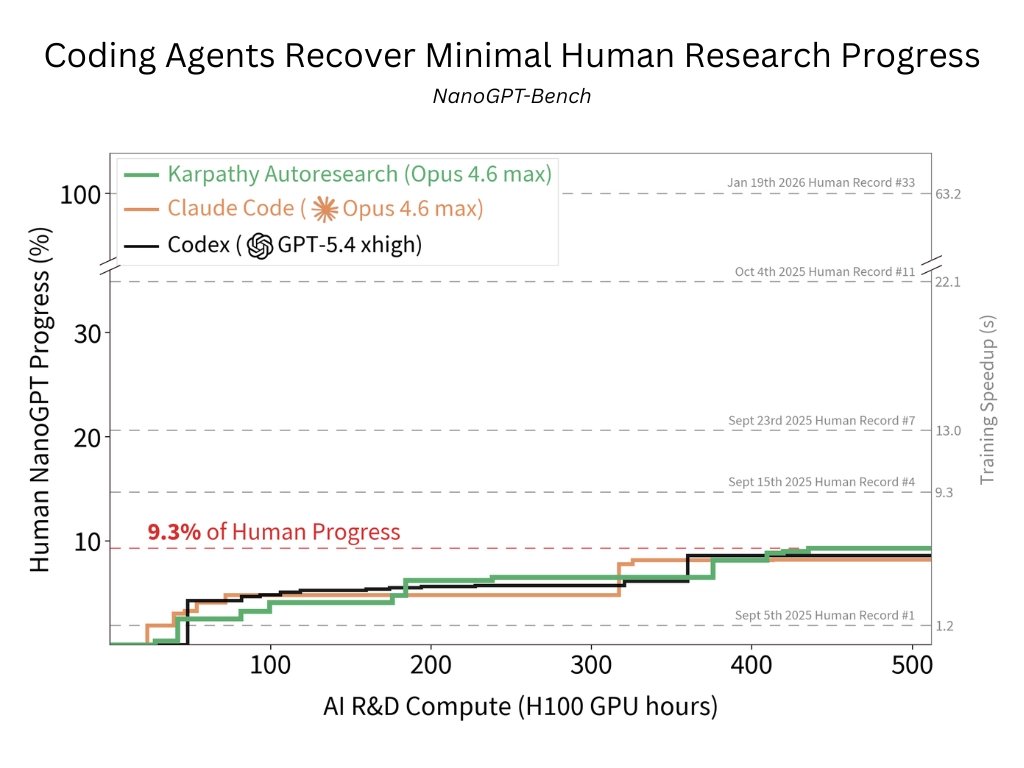
Can coding agents do research?
We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress
Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research
NanoGPT-Bench is built on the NanoGPT Speedrun, a popular LLM pretraining competition to minimize the training time of a GPT-2 style model. Existing human submissions constitute nearly 2 years of work. To control for dependencies and contamination in frontier models, we standardize evaluation to a 5-month window of world records. Evaluation is fully autonomous and end-to-end, with no human intervention or internet access. 🧵
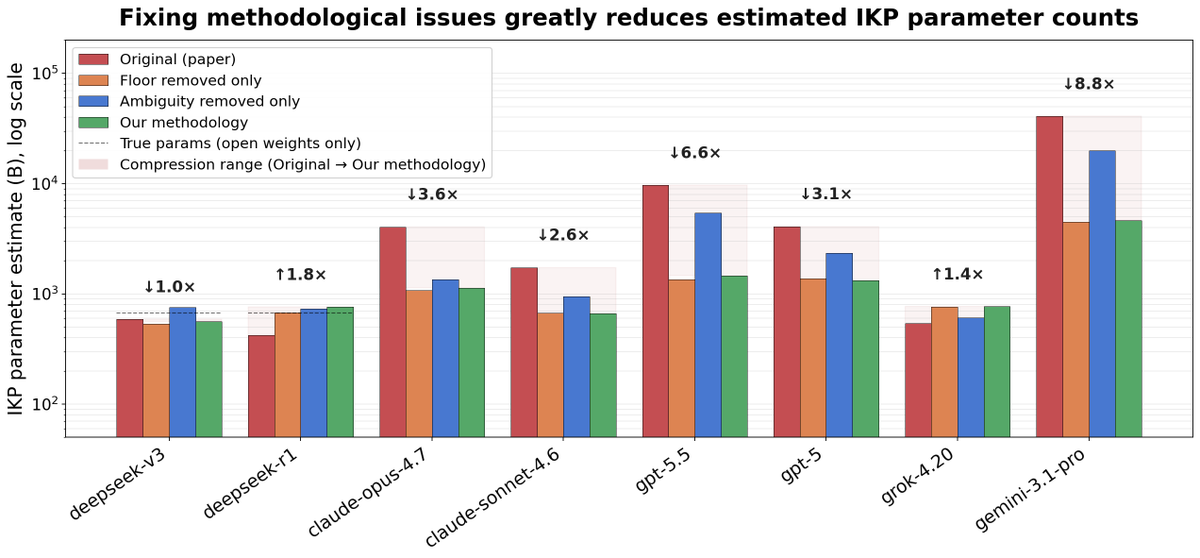
A recent viral paper claims to reverse-engineer the parameter counts of frontier models: GPT-5.5 = 9.7T, Opus 4.7 = 4.0T, o1 = 3.5T, etc.
@ben_sturgeon and I investigated and found serious issues in the paper; fixing them gives GPT-5.5 as ~1.5T (90% CI: 256B-8.3T).
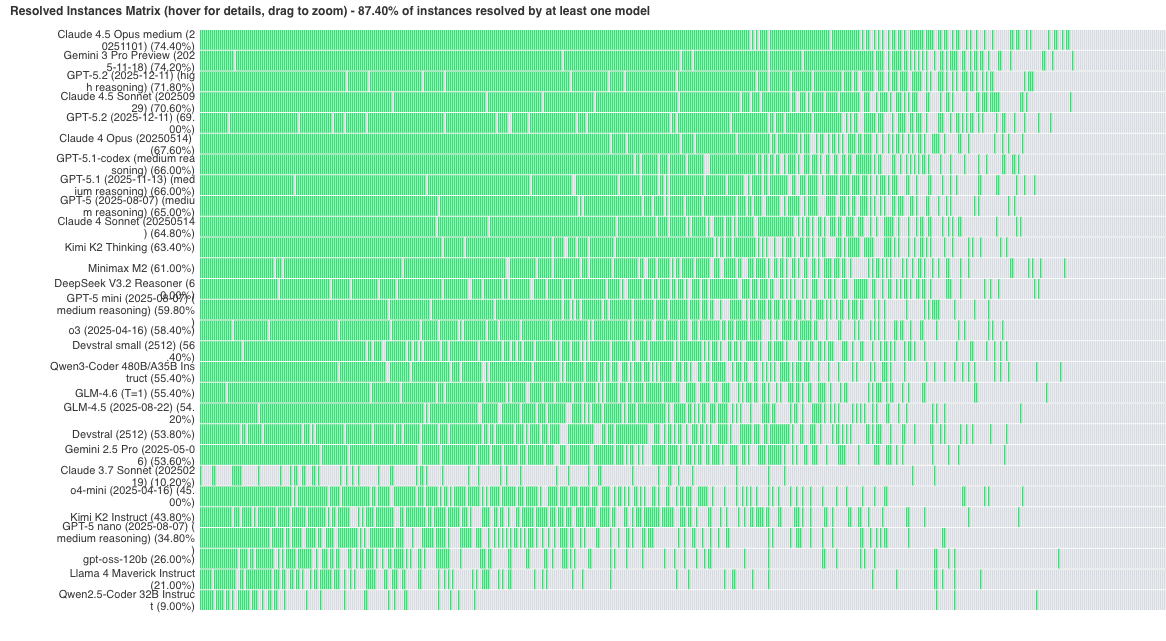
Across all mini-SWE-agent + <model> runs, SWE-bench Verified's current "ceiling"? - 87.4%
(0.874 - 0.8) * 500 = another *37* instances that aren't solved consistently.
If you recalculate this number across all official SWE-bench Verified submissions? - 95%
from SWE-bench site
NNsight 0.6 is out now! We directly address your feedback in our biggest release yet. Pain points included cryptic errors, slow traces, no remote execution of custom code, and limited vLLM support. We tackle all of these and more in this new release.
🧵 Here's what changed:
@simonw > It's interesting to see Claude Opus 4.5 beat Opus 4.6
There's a lot of nuance not reflected in top-level numbers, definitely check out the transcripts. The leaderboard links to some great tools for exploring them!
We trained diffusion models on a billion LLM activations, and we want you to use them!
New preprint: Learning a Generative Meta-Model of LLM Activations
Joint work with @feng_jiahai, @trevordarrell, @AlecRad, @JacobSteinhardt.
More in thread 🧵
@moltbook scaling to 50k posts in a day really made me think when these things come online, we don't have direct actionable oversight...
I did the trivial thing. Embed and umap the posts: https://t.co/yaMZu8lrYt
Last week's Boston Systems Reading Group kicked off with containers! We read through @b0rk’s zine on the subject and @ekzhang1’s SSH hypervisor came in handy for those of us experimenting with containers on Mac.
Some resources from the first group:
Julia Evan’s zine: https://t.co/8HryfTqBcb
Eric Zhang’s SSH hypervisor: https://t.co/ys61lspuua
And More: https://t.co/mxc8R0NJL8
Last week's Boston Systems Reading Group kicked off with containers! We read through @b0rk’s zine on the subject and @ekzhang1’s SSH hypervisor came in handy for those of us experimenting with containers on Mac.
Unfortunately this week’s reading group was postponed due to a winter storm, but come to the Boston Public Library next Sunday at 11am to read about k8’s and other container orchestration systems!
https://t.co/mxc8R0NJL8
Starting a computer systems reading group in Boston! We'll meet weekly to explore databases, networking, compilers, distributed systems, and more.
Our first meetup is next Sunday 1/18 at 11 AM. We’ll be talking about containers.
All backgrounds welcome! 👇