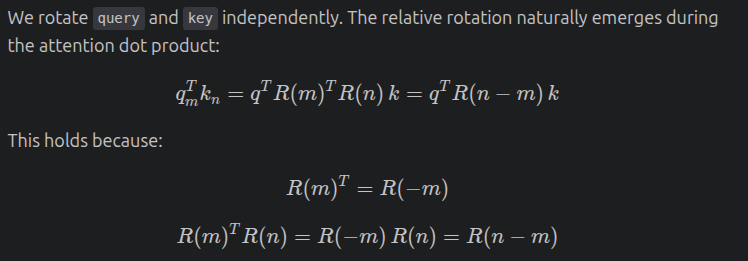RoPE is one of those things that everyone uses in LLMs but most explanations jump straight into equations.
I wanted to understand it from first principles.
So I wrote a blog explaining RoPE from scratch.
What if attention wasn't about matching tokens, but operating in function space?
Glad to share our #ICML2026 paper:
📄 Functional Attention: From Pairwise Affinities to Functional Correspondences
w/ @Jiefang_Xiao@GaoMaolin@stevenygd Daniel Cremers
📄 https://t.co/rhn9NtwrBm
Crazy model! It actually uses the old Qwen2.5-Coder-3B stack and got really great performance with their post-training stack.
Need to use it in the next days to see if vibes of VibeCoder actually check out in practice. But impressive first impression!
Based on the tech report, some of the important pieces of their post-training stack:
1. High-signal synthetic data (math problems with credible solutions, code with tests)
2. Multiple reasoning paths for each answer
3. Filtering, filtering, filtering
4. 2-stage SFT (start with broad training, then train on hard long-reasoning samples)
5. Use target (pass@k) accuracy over validation loss for checkpoint selection
6. MGPO (MaxEnt-Guided Policy Optimization) for RLVR: basically a GRPO-style RL method with an extra weighting that favors examples that are neither too easy nor too hard for the current policy
7. Single 64k long-context RL (they found that the usual progressive context expansion hurt this model because early truncation damaged long-thinking behavior)
8. Training data order: they do Math RL, then Code RL, then STEM RL in this particular oder which they found helped overall
9. After optimizing for accuracy, they add a stage that rewards shorter correct trajectories; basically making the model more efficient without accuracy degradation
Efficient AI Lecture 19: Distributed Training (Part 1)
This lecture gave me a much clearer picture of how self-attention parallelism actually flows across GPUs.
🔹 Start with the Transformer attention block: input tokens are projected into Q, K, V.
🔹 In tensor parallelism, the QKV projections can be split across GPUs, often by attention heads. Each device computes only part of the projection.
🔹 After local attention computation, the output projection needs synchronization. The partial outputs from different GPUs are combined with communication primitives such as All-Reduce.
🔹 For long sequences, sequence parallelism changes the axis: instead of only splitting heads or hidden dimensions, we split the tokens across devices.
My note:
https://t.co/hDwbHbARTl
RoPE is one of those things that everyone uses in LLMs but most explanations jump straight into equations.
I wanted to understand it from first principles.
So I wrote a blog explaining RoPE from scratch.
The interesting part is,
RoPE preserves relative position information naturally.
That's why transformers can learn relationships between tokens so effectively.
Without needing to store giant positional vectors.
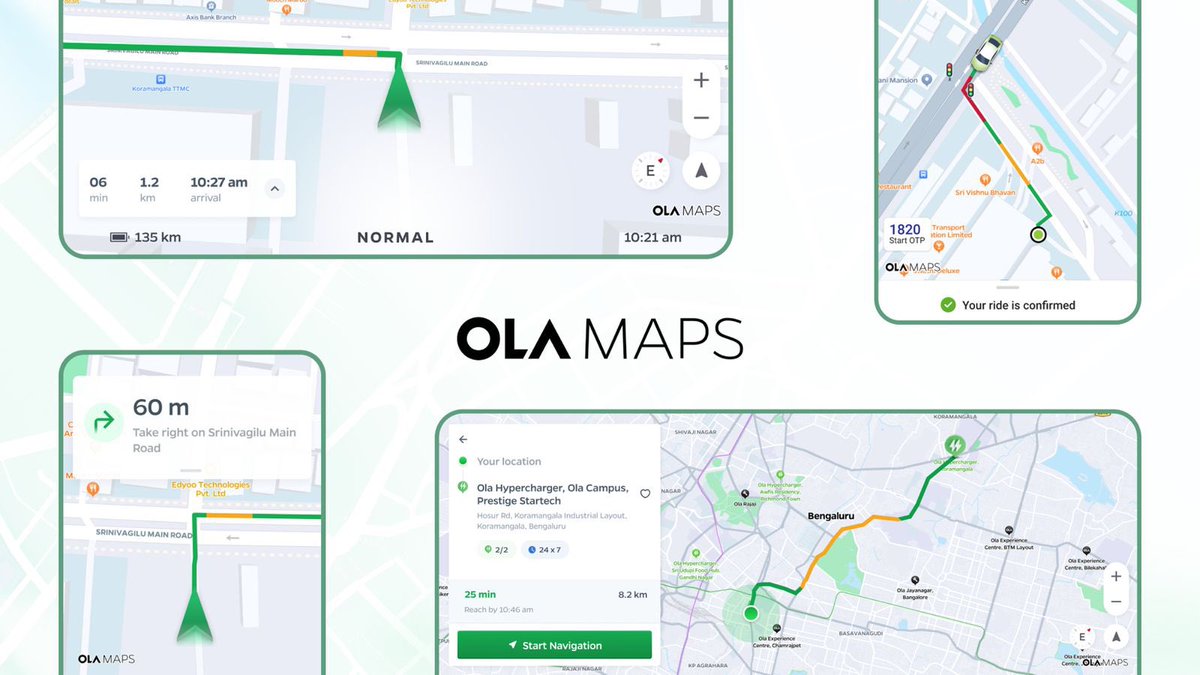
After #ExitAzure, it’s time for 🇮🇳developers to #ExitGoogleMaps! 1 YEAR FREE access to all developers to Ola Maps on @Krutrim, more than ₹100Cr in free credits! https://t.co/qAT4OTarvB
We’ve been using western apps to map India for too long and they don’t get our unique challenges: street names, urban changes, complex traffic, non-standard roads etc. Ola Maps tackles these with AI-powered India-specific algorithms, real-time data from millions of vehicles, leveraging and contributing massively to open source (5 million+ edits just last year!)
We’re outperforming competitors on
📍 Location accuracy
🔍 Search accuracy
⏱️ Search latency
🚗 ETA accuracy
Here’s more details in our tech blog: https://t.co/LtrdPBD1xa
@suvonilc will share more details too!
Google presents SpatialVLM
Endowing Vision-Language Models with Spatial Reasoning Capabilities
paper page: https://t.co/uhYtNSJ5pB
Understanding and reasoning about spatial relationships is a fundamental capability for Visual Question Answering (VQA) and robotics. While Vision Language Models (VLM) have demonstrated remarkable performance in certain VQA benchmarks, they still lack capabilities in 3D spatial reasoning, such as recognizing quantitative relationships of physical objects like distances or size differences. We hypothesize that VLMs' limited spatial reasoning capability is due to the lack of 3D spatial knowledge in training data and aim to solve this problem by training VLMs with Internet-scale spatial reasoning data. To this end, we present a system to facilitate this approach. We first develop an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images. We then investigate various factors in the training recipe, including data quality, training pipeline, and VLM architecture. Our work features the first internet-scale 3D spatial reasoning dataset in metric space. By training a VLM on such data, we significantly enhance its ability on both qualitative and quantitative spatial VQA. Finally, we demonstrate that this VLM unlocks novel downstream applications in chain-of-thought spatial reasoning and robotics due to its quantitative estimation capability.
Had an amazing time at the @makers_tribe Mega Meet-up! Met inspiring professionals, gained valuable insights, and had the privilege to speak with @kissflow CEO, @sureshsambantham. Grateful for the opportunity to connect and learn from like-minded individuals. #CFCMegaMeetup
Hi everyone, I have created a new Kaggle notebook, I explained about the CNN and the pattern recognition of each layer. Please check it out https://t.co/KUq9AWhC6H and let me know your suggestions, feedback, and insights. I'm eager to learn and improve! 🙌