@Bhavyaztwt codex is the best choice for 20$ plan at the moment. GPT 5.5 is top notch for most tasks, 5.3-codex is cheap, almost like unlimited, and can be used for most lightweight tasks.
Deepseek v4 pro is on par with 5.3-codex, but nowhere close to GPT 5.5.
Tried deepseek v4 pro yesterday. I'm impressed by the quality/price ratio.
Definitely nowhere close to frontier models as most people hype on x.
I would still use GPT 5.5 for majority of the tasks, and delegate some sonnet level tasks to deepseek v4 pro.
(1/4)
A few weeks ago, I shared my honest thoughts after running Paperclip AI for 2 weeks.
Then I ran it for 2 more weeks on a real project: k8s-ai-sre
https://t.co/9SZ8kqRBTD
(3/4)
Based on what worked, I created an agents template that can be reused with any project.
It captures the setup and patterns that were useful in practice, so you do not have to start from scratch each time.
@builtwithjon@Teknium@aronprins@dotta@adam_x_mentis Love the idea! This is the same direction i was planning, you are way ahead of me :D
What worked for me is to use a frontier model for CEO, and let it do staff management + project management.
important: It needs a self-feedback loop to keep improving the agent instructions
@builtwithjon workflow and config management is a pain point with papeclip. the native way of using AGENT_HOME is too unreliable.
I ended up managing the agent configs myself, and using paperclip purely as orchestration layer. Here is my reference structure
https://t.co/6EWHDRukTR
I ran Paperclip AI for 2 weeks to manage open-source projects.
It’s not an “autonomous AI company,” but it is an interesting control plane for multiple agents.
My honest thoughts:
https://t.co/3zkSnwlA1s
#paperclipai#homelab
Have been playing with #paperclip from @dotta .
Really love the concept. It definitely took some time to get it to a productive state (ngl, there are some bugs at the moment). But going well so far.
Detailed post coming soon. Stay tuned :D
4/ AI is increasing output across teams.
More code. Faster iteration. More experimentation.
That creates pressure:
• Stronger pipelines
• More stable infra
• Better security
• Scalable platforms
Faster dev cycles increase the need for mature DevOps.
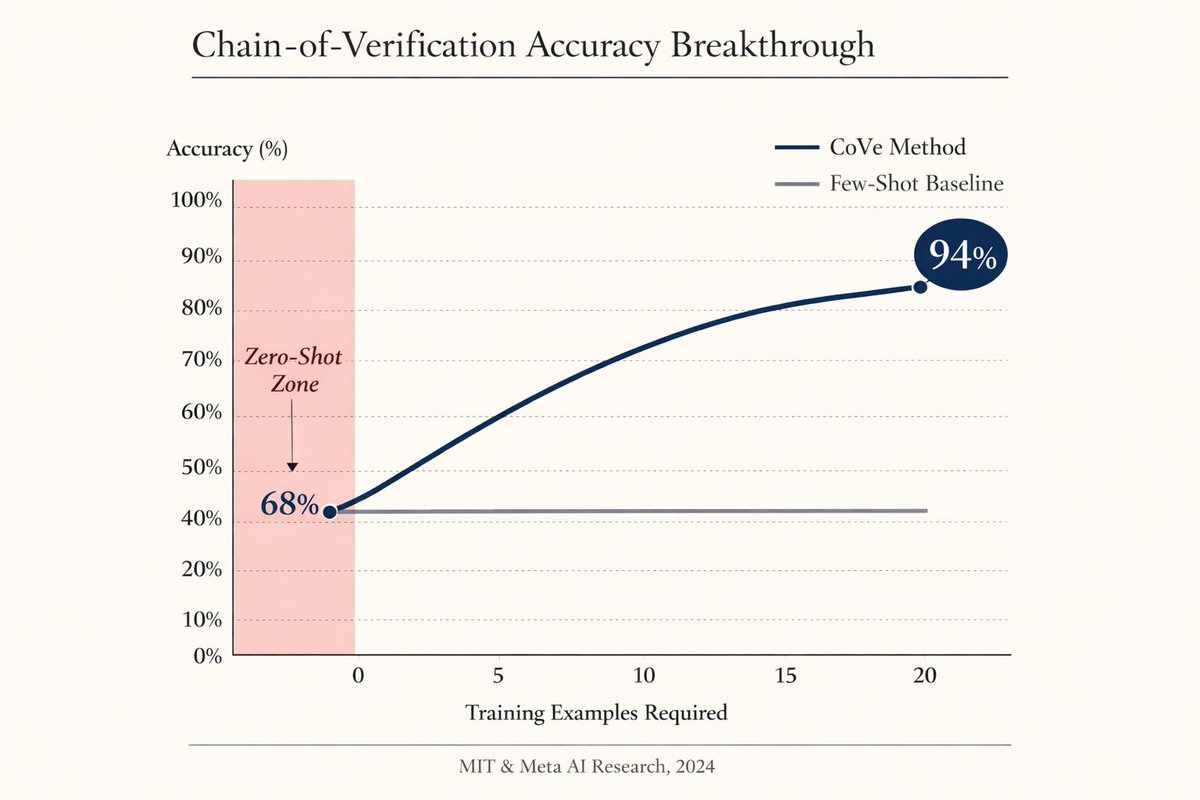
R.I.P few-shot prompting.
Meta AI researchers discovered a technique that makes LLMs 94% more accurate without any examples.
It's called "Chain-of-Verification" (CoVe) and it completely destroys everything we thought we knew about prompting.
Here's the breakthrough (and why this changes everything): 👇
Is there anyone who likes #opencode more than #ClaudeCode ? I really want to use it more often. But somehow claude code seems far ahead (except the stupid scrolling bug). Am I missing something?