“We already implemented an AI tool” is becoming the new default answer inside support teams.
Classic checkbox mentality.
Most teams have something in place now.
A chatbot.
An email assistant.
A help center search layer.
So the team feels covered.
But “we have AI in support” is not the same as “support is improving where it hurts.”
Where does your AI stop helping?
Because many tools work well at the surface.
But the expensive work usually sits somewhere else:
-> Complex customer issues.
-> Broken integrations.
-> Technical edge cases.
That is where support teams should look before deciding they are “good for now.”
The next phase of AI in support is not adoption.
It is impact.
The biggest question should be:
“Is our AI solving the support problems that actually cost us the most?”
What part of support are you judging your AI on?
You can overthink a problem for days, open the same doc 10 times, and get nowhere. Or you can step away, light a grill, and have the answer hit you somewhere between flipping the chicken and burning your thumb.
The Pluno team off the clock 👇
Salesforce buying Fin makes one thing obvious:
AI support agents are becoming platform decisions.
That’s why users are anxious.
They’re not just asking whether Fin will keep improving.
They’re asking whether Fin will still feel like Fin.
Will it stay easy to use outside Salesforce?
Will non-Salesforce CRMs remain first-class?
Will pricing stay predictable as Agentforce leans further into usage-based models?
That’s the real tension.
When an AI support tool gets pulled into a bigger ecosystem, the product can start shaping your workflows.
Your CRM.
Your data paths.
Your pricing model.
Your implementation roadmap.
For some teams, that might be fine.
For most, it can get heavy fast.
Because they don’t want another platform migration.
They want an AI agent that fits the stack they already use and keeps improving without forcing the team to reorganize around it.
Pluno, on the other hand, is platform-agnostic, workflow-native, and fast to adapt through real iterations.
The Fin deal validates the category.
It also sharpens the buying question:
Are you buying an AI support agent…
or are you buying into an ecosystem you may not be able to leave?
The real AI support test is not the easy ticket.
It is the messy one your agents already dread.
The one with a screenshot.
A video.
A strange customer setup.
And enough prior context to make everyone nervous.
For highly configurable products, polished demos only prove so much.
They show whether AI can answer clean help-center questions.
But real support quality shows up when the case is complex:
Does it use the right sources?
Does it recognize outdated ticket history?
Does it avoid hallucinating?
Does it know when to escalate?
Does it help tier one hand over useful context to tier two?
Because one confident wrong answer can destroy agent trust.
That is why the best AI evaluation is not a demo.
It is a simulation.
Take 10–20 real tickets your agents struggled with.
Run every vendor through them before customers ever see an AI-generated answer.
For example, Pluno helps support teams test AI on historical complex tickets, so they can see how it handles messy cases before going live.
The goal is not just automation.
It is confidence.
How are you testing AI support quality: with polished demo scenarios, or with the messy tickets that define agent trust?
Low CSAT is a signal.
The real value is knowing what caused it.
That is where CSAT workflows get interesting.
Because the score tells you something went wrong.
The ticket tells you what happened.
But support teams still need the layer in between:
Why was the customer actually unhappy?
Slow response?
Wrong answer?
Unclear handoff?
Missing product capability?
Bug with no workaround?
Too much back-and-forth before escalation?
That layer is usually manual today.
Someone reads the comment.
Then the ticket.
Then the internal notes.
Then maybe the escalation.
Then maybe the Jira issue.
By the time the pattern is clear, the moment to act has already started slipping away.
The real opportunity for AI in support is bigger than ticket summaries.
It is feedback pattern analysis.
A single summary helps an agent understand one conversation.
Summarized patterns help a team understand what customers are repeatedly experiencing.
That changes the operating rhythm:
Review negative CSAT tickets.
Group dissatisfaction drivers.
Spot recurring product, process, and communication issues.
Feed those patterns back into support, product, and leadership.
For example, Pluno can use structured ticket summaries, field tagging, and QA context inside your helpdesk to help teams connect negative feedback to the underlying issue behind the conversation.
That is the shift.
CSAT stops being a dashboard metric.
It becomes a learning loop.
Where do you think CSAT analysis usually breaks down: collecting the feedback, finding the root cause, or getting teams to act on it?
The biggest mistake I made early on:
Thinking complex tickets are unique.
They’re not.
They just look different.
In 10k+ tickets we analyzed:
~68% of complex issues had already been solved before.
Same root cause
Different wording
Different customer
Humans see this instantly.
AI trained on documentation doesn’t.
So what happens?
Same issue
Solved again
And again
And again
That’s where most of your time goes.
Not in new problems.
In repeated ones.
Do your “complex” tickets actually repeat more than you think?
@karllorey You might've started your session with Fable?
And I guess switching skills or tool descriptions upon model switch would break cache (at least if it's loaded already)
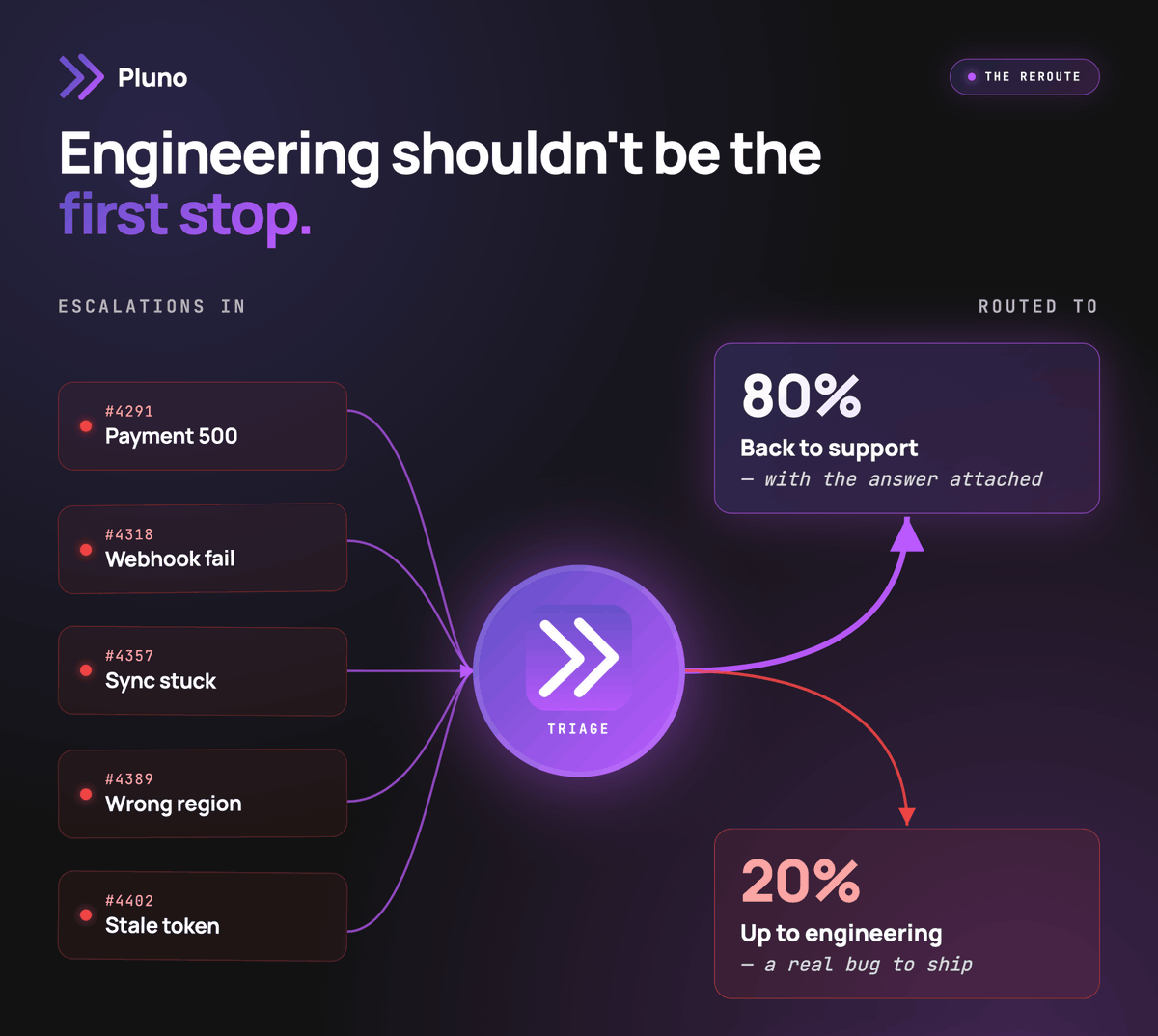
If your engineers still get pulled into support tickets
You don’t need another explanation. You need to see this.
We built Pluno Troubleshooting Agent to handle the exact tickets that currently require an engineer to investigate:
→ It checks Sentry, logs, replays, deploys, and your DB
→ It correlates everything automatically
→ It tells you what likely happened (with evidence)
→ It suggests the fix
In minutes.
Not hours.
Not “when someone gets to it.”
Teams using it are already seeing:
– fewer escalations
– faster resolution times
– engineers getting their time back
This isn’t a chatbot.
It’s not deflection.
It’s the part of support that actually costs engineering time.
Turn your Front-line staff into an advanced support team to run database scripts and resolve configuration issues without dev intervention.
A new paradigm in customer operations!
If you’re curious what it would find in your tickets
👉 Try it here: https://t.co/frMDJZxRwT
3 things I used to believe about customer support troubleshooting:
>> "It's hard to automate because every issue is different."
It isn't.
Most issues share the same investigation pattern.
Just with different inputs.
A massive majority of support tickets stem from a tiny handful of root causes.
Roughly 80% of volume is driven by 20% of issues.
Deep learning models can match many ways of saying the same thing to one intent with over 90% accuracy.
Plus, LLMs follow diagnostic steps, find causes faster, and make fewer mistakes than tired humans.
>> "More observability tools will solve it."
They won't.
More tools just give your engineers more places to look.
... more dashboards, more browser tabs, and more disconnected data streams.
Exposing engineers to overlapping data from multiple unintegrated tools = increased mean time to resolution (MTTR).
And what happens when the signal-to-noise ratio drops?
👉 Critical anomalies starts to get ignored.
Why?
... because they are buried under thousands of benign notifications.
>> "This is a support team problem."
It's an engineering problem disguised as a support problem.
Every complex ticket eventually becomes engineering's afternoon.
Forcing engineers to spend their afternoons playing detective in production logs means:
- compromising the timeline of the core product features
- consumes 4x to 10x more organizational resources
- derailing an entire 8-hour workday due to the cognitive overhead
We built Pluno Troubleshooting Agent on the opposite assumption of all three.
Which one did you believe?
Support Driven Amsterdam Summit starts tomorrow and I’m so excited to be there!
Looking forward to meeting people working on support operations, customer support leadership, and support tooling.
We’re building something in this space too, so I’d love to compare notes, hear what teams are struggling with, and chat about what better support workflows could look like.
If you’re attending, send me a DM and let’s find a time to say hi :)
Your support AI is only as good as how fast your knowledge keeps up with product change
Most support teams get this wrong.
Building a good knowledge base is a prerequisite for having a great AI agent.
They treat the knowledge base as a one-time project.
Spend months building it,
feeling like the job is done.
Then the product moves on.
New features ship.
Existing flows change.
Sometimes both happen in the same week.
Suddenly the knowledge base is outdated and support quality drops.
And in teams building AI driven products this problem gets worse.
Shipping speed is increasing, not slowing down.
But the knowledge base process does not keep up.
So your teams just always lags behind updating it.
This is not scalable.
There’s a better approach:
—> Stop treating the knowledge base as something separate.
Instead, connect it directly to product changes and real support ticket resolutions.
Let it evolve as part of the system.
Not as a cleanup task after the fact.
That way, it stays aligned with what your product actually is today, not what it was months ago.
What does your knowledge process look like today?
Support isn’t improving with AI
It’s quietly breaking.
We added:
-> Automations
-> Frequent updates for the help center
-> AI replies
But nothing changed where it matters.
Complex tickets still go to humans.
And that’s where all the cost is.
If your AI only handles easy tickets, you didn’t automate support.
You concentrated the pain.
Now your team handles:
-> harder issues
-> more context fetching
-> more pressure
That’s why support still feels overwhelming.
The next phase is not updating the static help center faster.
It’s actual resolution delivered via self-learning AI.
AI that handles messy, real-world problems.
And learns itself how to do that by leveraging:
- deep integrations
- past tickets
- visibility into live cases and data
Are you reducing workload or just redistributing it?
Every engineering leader I talk to says some version of this:
"Yeah, my engineers get pulled into support sometimes. It's fine."
Then I ask:
How many hours per week?
What does it cost in shipped roadmap?
How often is it actually a real bug vs. a configuration issue?
The answers are usually:
-> 2 to 3x more hours than they estimated.
-> One team measured 14 engineer-hours a week. Roughly one feature per sprint.
-> Maybe 20% are real bugs.
So 80% of the time, your most expensive engineers are doing investigation work that didn't need an engineer.
It needed context.
And Pluno Troubleshooting Agent provides that context.
It pulls the config, the recent changes, the logs.
Runs the standard checks.
Either resolves it, or hands engineering a ticket that starts with "here's what's broken."
Not "can you take a look?"
So engineering only gets pulled in when there's something for them to actually fix.
How much engineering time would you reclaim if 80% of escalations resolved before reaching you?
There are only 2 real types of AI support systems.
And most teams are using the wrong one.
Type 1: Documentation-driven AI
<- Help center in
-> Answers out
Works until:
Something isn’t documented
Something breaks
Something gets messy
Then it fails.
Type 2: Ticket-trained AI
<- Past tickets in
-> Solutions reused
The shift is simple:
From:
“What article matches this?”
To:
“How was this solved before?”
In one dataset we looked at:
~68% of “complex” issues had already been solved before.
Just under a different name.
Most teams are solving the same problems over and over.
They just don’t see it.
Which system are you actually running?
If your AI is trained on a help center, it will fail the moment things get real.
Most tools look great in demos.
They handle:
- simple questions
- clean queries
- perfect inputs
Then reality hits:
API breaks
Edge case appears
Customer setup is messy
And suddenly:
Your “AI agent” becomes a routing system.
So what happens?
Your engineers step in.
Again.
And they’re solving the same issue for the 12th time this month.
If your AI only handles easy tickets, you didn’t automate support.
You made it worse.
Where does your system break first?
The biggest assumption we had to unlearn:
"Complex" customer tickets are unique.
They're not.
They just look different on the surface.
Look at the underlying pattern:
A customer hits an error.
The error correlates with a recent deploy, a config edge case, or a known bug.
The work to find that correlation is almost always the same.
It just gets done by a different engineer, on a different afternoon, in a slightly different order.
The pattern is:
Symptom → scattered evidence → root cause.
Humans solve this manually, one ticket at a time.
Pluno Troubleshooting Agent solves it once, every time.
What % of your "unique" tickets actually share the same root cause?
A team plugged in Pluno Troubleshooting Agent last week.
Within 24 hours, it caught a regression..
which their support queue had been escalating for three days.
Same data.
Same visibility tools.
Same tickets.
The difference: Pluno correlated across Sentry, recent deploys, and similar past tickets, then surfaced the pattern.
A human would have caught it eventually.
But "eventually" had already cost three engineering hours and a good number of frustrated customers.
That's the real cost most teams don't track. What's an "eventually" cost you've absorbed this quarter?
There are 2 ways teams handle complex customer issues right now.
Type 1: Engineering as the troubleshooter
Support escalates.
An engineer drops what they're doing.
They jump between Sentry, logs, replays, code, deploys, and the database.
While they find the answer, the customer waits. The roadmap waits.
Type 2: AI as the troubleshooter
- Pluno Troubleshooting Agent investigates across the same tools.
- Reports back with root cause, evidence, and a recommended fix.
- Engineering only gets pulled in when there's an actual bug to ship.
- With the recommended fix, they can just review and implement.
The difference isn't the visibility tools.
It's who has to do the investigation, and how much does it take away from "needle-moving" work when done manually
Most teams are still running Type 1 and calling it normal.
Which one are you running?