Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
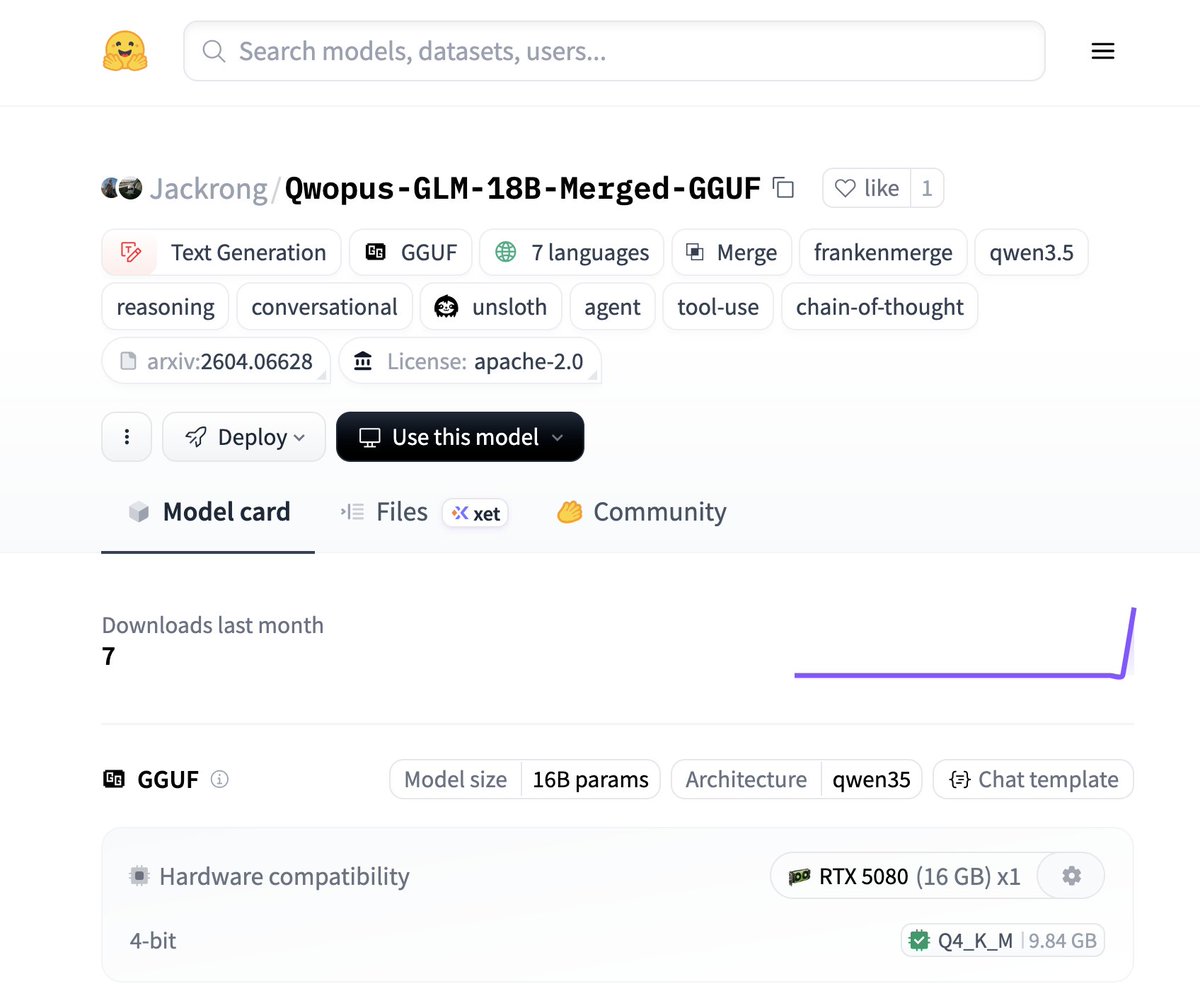
Okay this one is insane. A new 18B frankenstein model was just released on @huggingface — Beats the new Qwen3.6-35B-A3B on a 44-test suite despite requiring 12GB VRAM instead of 24GB 🤯
Runs on a SINGLE RTX 3060 (!)
🧠 Opus 4.6 & GLM-5.1 reasoning in one model
⚡️ 66+ tok/s stable on mid-range GPUs
🧪 Experimental, no additional training
🛠️ Perfect tool calling & agentic reasoning
📷 Fits on low hardware, any 12gb card
📚 GGUF size is 9.8GB (Q4_K_M)
Another gift from Jackrong, adding both qwopus and glm-distilled qwen together was not on my bingo card. Truly seems like the sweet spot between 9B and 27B models right now.
The ultimate model for 12-16GB VRAM owners?
https://t.co/kqDUizh1pf
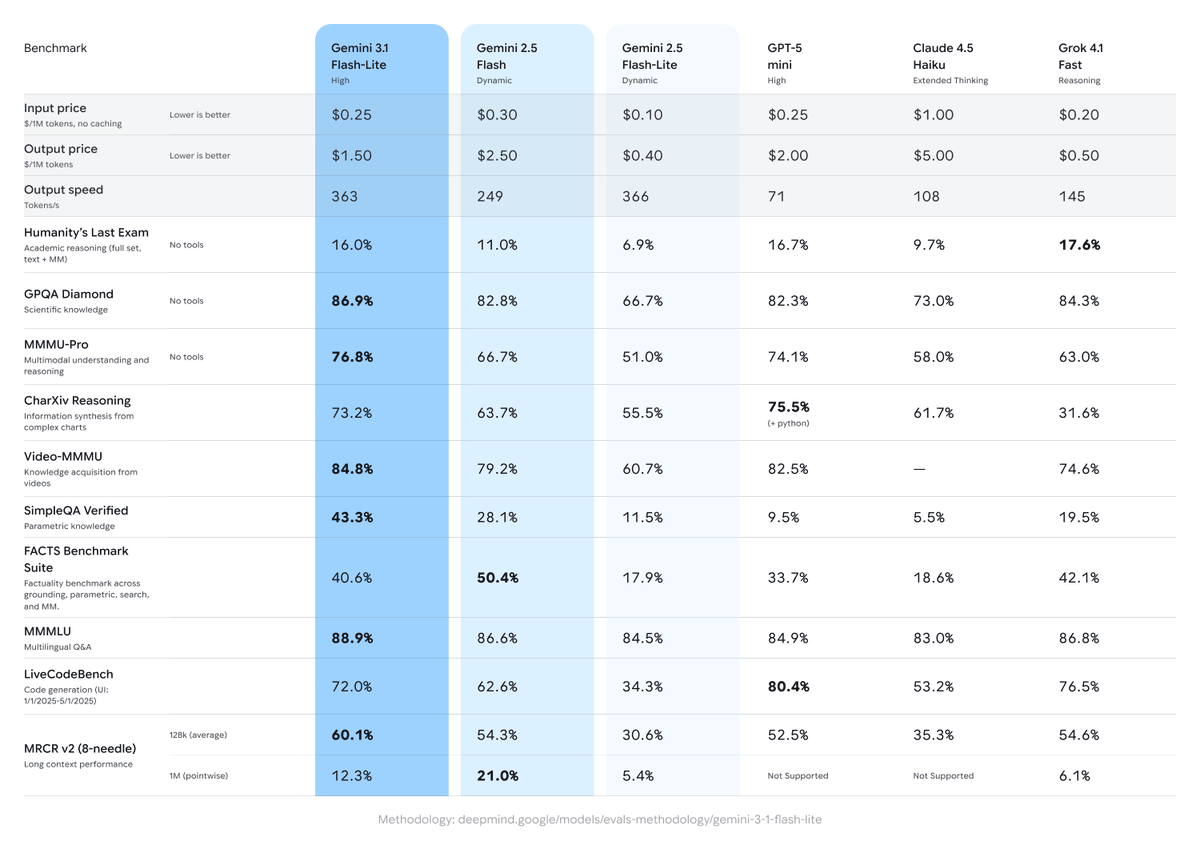
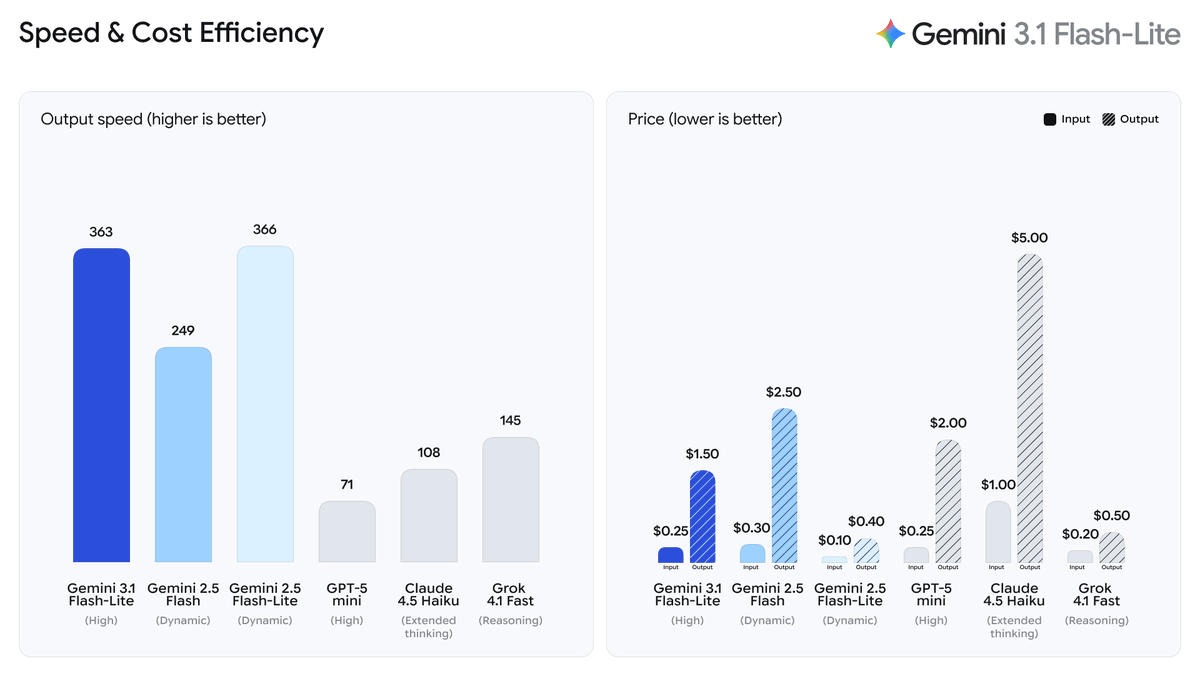
Gemini 3.1 Flash lite released and its next level price-performance-ratio
Gemini 3.1 Flash-Lite, its fastest and most cost-efficient Gemini 3 model yet, built for high-volume developer workloads.
Priced at just $0.25 per 1M input tokens and $1.50 per 1M output tokens, it delivers 2.5x faster time to first token and 45% faster output speed than 2.5 Flash, while achieving a 1432 Elo score and up to 86.9% on GPQA Diamond benchmarks.
This tweet frames Zvec as a Pinecone killer. That framing obscures what Alibaba actually built.
Zvec is an embedded, in-process library. No server. No network calls. No daemon. You import it like you import pandas. Pinecone and Weaviate will never see this in their competitive dashboards because it targets a completely different layer of the stack.
The technical lineage matters here. Proxima has been running production vector search inside Alibaba for years. Taobao product search, Alipay face payments, Youku video recommendations, Alimama advertising. Billions of queries across systems where latency failures cost real revenue. What Alibaba’s Tongyi Lab did is strip that engine down, wrap it in a Python API, and release it as a library anyone can pip install.
The benchmarks back it up. On VectorDBBench with the Cohere 10M dataset, Zvec hits 8,000+ QPS at comparable recall. That’s more than 2x ZillizCloud, the previous #1, with faster index build times. An embedded library matching or beating managed cloud services on raw throughput.
This follows the SQLite playbook. SQLite opened an entirely new category of database usage by embedding directly inside applications. Software that would never have run a client-server database suddenly had access to SQL. Zvec is making the same bet for vector search: local RAG pipelines, desktop AI assistants, CLI tools, edge devices, anywhere spinning up a Pinecone cluster would be absurd.
And that tells you where AI inference is heading. Every agent framework, every local assistant, every on-device RAG system needs vector search. The vast majority of those workloads run fine on an in-process library with 64 MB streaming writes and configurable memory limits.
Pinecone raised $138M and just repositioned as a “knowledge platform.” Weaviate raised $50M. Their customers have SLAs, compliance requirements, and enterprise procurement cycles. Zvec is going after the 90% of developers who were overprovisioning infrastructure for workloads that fit inside a single process.
The companies that should actually be nervous are Chroma and FAISS, the current defaults for lightweight local vector search, because Zvec just showed up with Alibaba-scale engineering in a pip-installable package.
If your pitch needs urgency pricing, affiliate pressure, and “just install this code” energy, that is a trust exploit.
Reposting this because it shows exactly what feels wrong here.
LarryBrain MIGHT be legit, but right now it feels scammy:
• aggressive “buy now before price jumps” messaging
• huge affiliate incentives
• FOMO-heavy marketing instead of technical proof
• second-hand skill marketplace model where users can end up installing code they never audited
From a security perspective, this is a dangerous combo:
• remote skill download
• local file writes
• easy one-command install flow
• weak user due diligence in practice
That is not empowerment. That is how people accidentally run harmful code on their own machines.
Call it growth hacking if you want. When the system is built around getting more people to buy in through affiliate incentives, people will call it pyramid-scheme behavior.
Audit first. Install second. Always.
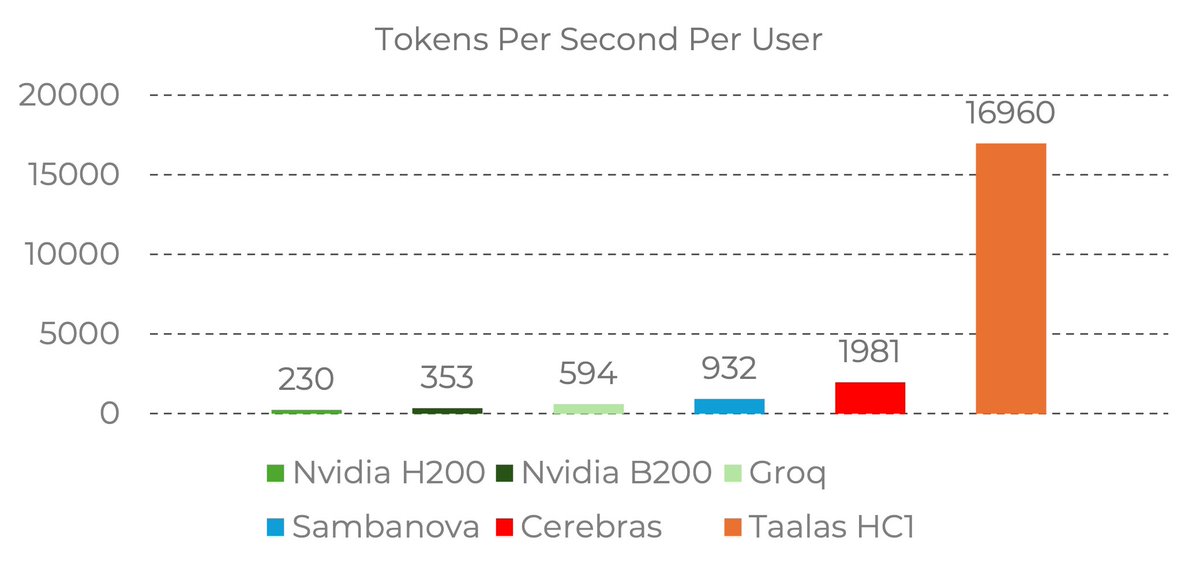
17,000 tokens per second!! Read that again!
LLM is hard-wired directly into silicon. no HBM, no liquid cooling, just raw specialized hardware. 10x faster and 20x cheaper than a B200.
the "waiting for the LLM to think" era is dead. Code generates at the speed of human thought.
Transition from brute-force GPU clusters to actual AI appliances.
https://t.co/Bf6DH7Q6Uf
Every solo founder I know, including myself, eventually hits this wall: building the thing is 20% of the battle. Distribution? That's the other 80%, and it's a jungle out there.
Following the same 'get 100 followers, engage 10 people, comment on threads' playbook everyone shares? It's the fastest way to get lost in the noise. You end up blending in, not standing out.
Your advantage isn't how hard you work; it's how different you are. I learned this going from data scientist to full-stack with AI tools, building Artera, now dartpost. What makes YOU uniquely you? That’s your distribution strategy.
Seriously, what’s your take on this? Are you just following playbooks?
AI isn't here to replace software developers; it's here to promote us.
Forget junior dev tasks. That's AI's job now. The game has changed. When I started as a data scientist, then learned backend/AWS and became full stack with AI's help, I quickly saw this shift.
The real skill premium is now on system design, architecture, and knowing *what* to build and *why*. AI can write a brilliant Next.JS module, but it can't tell you if that module solves a real business problem, or how it integrates into a complex distributed system.
My entire journey building #dartpost 🚀 on AWS and Supabase has been about me driving the architectural vision, and AI rapidly iterating on the low-level code.
Humans drive ideas. AI builds the vehicle. Are you designing the vehicle or just turning wrenches?
I always hated ORMs, they hide complexity by sacrificing functionality, hiding behind "simple" syntax.
I remember the Django ORM had issues with composite primary keys in postgres, which was beyond stupid to me at the time.
We managed to work around it though, so it can work
ORMs are an anti-pattern once you start operating at scale.
At scale, most move away from them as the abstraction that bridges the database and programming language never fully holds.
At scale, by using ORM, you almost always end up missing native database optimizations. And if you are already writing raw queries to work around ORM limitations, you are actually better off using prepared statements directly.
The ORM abstraction hides query complexity, yes, but it does make it easy to ship inefficient N+1 queries without realizing it. Debugging becomes painful at the worst possible time - during production incidents.
ORMs tend to lag behind database features. Indexing strategies, query hints, and newer capabilities are either inconvenient to use (just look at prefetch in Django ORM) or simply unavailable. This makes you opt for the lowest common capability (as offered by ORM) instead of leveraging the database properly.
At scale, explicit queries are always simpler, faster, and easier to optimize; the cognitive overhead of mapping objects to tables is often not worth it.
To be fair, ORMs make sense for prototypes and for getting to market quickly. Use them when you are starting out or in the early phases, but have a plan to migrate away from them :)
Easier said than done, though; been there!
I've worked in a team of two where I was the first guy and my coworker - the second.
Both are important, perfectly balancing each others faults.
Engineering is a coop game, not single player
The “post 3x a day” advice is everywhere.
I’m doing the opposite.
I’m running an experiment: Only posting once a week, but making it the most high-signal content I can produce.
No more filler just to feed the algorithm. I'm betting on quality over quantity.
Let's see how it goes.
3. Focus on Impact, Not Just Activity
Instead of saying "I built a new caching layer"...
Say "I reduced API response time by 300ms, improving user experience and cutting our server costs."
Always connect your technical work to a business outcome. This is how you demonstrate senior-level thinking.
Presenting is a critical skill for an engineer...
ESPECIALLY for an engineer.
Clear communication is what separates junior/mid-level engineers from the senior/staff-level ones.
Here are 3 core principles to master presenting 🧵:
2. Structure the Narrative: Why → What → How
Most engineers present in the reverse order. Flip it.
Start with the WHY: What problem are you solving and why does it matter?
Then the WHAT: What was your solution?
Finally, the HOW: Briefly explain key technical decisions.