Learn Kubernetes Today!
In this course you learn about the core concepts including demos of CNI, kube proxy & CoreDNS.
A project based learning where you deploy multi microservices app with db.
Go learn today & do not forget to subscribe to Kubesimplify.
https://t.co/POf8FWA4H9
Helm chart anti-pattern :
Templating your model name + version into values.yaml.
Why it's bad:
Every model promotion becomes a git commit → PR review → deploy pipeline.
That's minutes or hours when you need seconds.
Model metadata should live in a model registry or be injected as an annotation at deploy time.
Your serving layer pulls the artifact.
Helm never needs to know.
Use Helm for infrastructure. Don't use it for model registry.
If your platform team is constantly fighting fires, you don't have a platform.
You have a service desk that runs Kubernetes.
A real platform offers self-service, golden paths and paved roads. It makes the right thing easy.
If your team spends more time on tickets than on developer experience, that's not platform engineering.
That's operations with extra steps.
Firefighting is a symptom, not a strategy.
Confidential computing on H100 is no longer a research demo.
NVIDIA Confidential Compute Mode is GA.
Encrypted GPU memory.
Attestation.
Works on Kubernetes with the right operator.
Use cases that need it:
→ Healthcare AI inference
→ Financial models with regulated data
→ Multi-party ML training
If your customers ask "but where does the data go?" this is the answer.
KubeCon + CloudNativeCon India is just over two weeks away. Join @SaiyamPathak and Saloni in Mumbai this June 18-19 to talk real-world cloud native, production setups, and connect with the community building the future of open source.
Following Saiyam to get a special 25% discount and register here: https://t.co/QHujZZUYaF
Day 9 Node Affinity vs NodeSelector vs Taints.
They are NOT interchangeable.
NodeSelector = exact match, zero fallback
Node Affinity = hard constraints OR soft preferences
Taints = node says "keep out" unless you have the key
Pick wrong → outage.
Pick right → peace
quick explainer breaking down the exact decision tree ↓
#kubernetes #devops #cloudnative #k8s #engineering
Quick one:
Image pull throttling on AI worker nodes is the silent killer of cluster reliability.
Mirror your registry.
Set ImagePullPolicy: IfNotPresent.
Pin by digest.
Or pay the egress bill and explain to finance later.
Why your DRA setup is slower than vanilla https://t.co/QvDtzFfAjX
→ Driver plugin not co-located → cold start on every claim
→ DeviceClass selectors too broad → scans everything → ResourceClaim lifetime too short → constant recreate churn
→ Webhook timeouts during structured param validation
DRA isn't slow.
Misconfigured DRA is slow.
The fix list 👇
This is the best Local LLM using @NVIDIAAI DGX spark I am writing - 2 parts are already out and we will just be getting better with every post - this is 7 part series! You should definitely read this if you want to master Local LLM game.
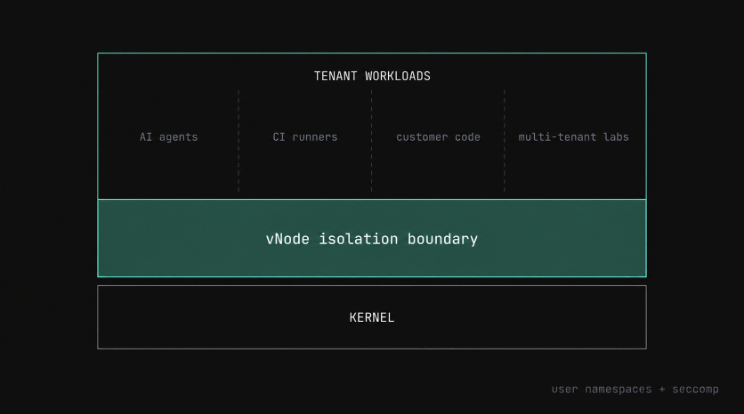
vNode is quietly becoming the default for tenant isolation in 2026.
Linux user namespaces + seccomp. No VM overhead. Real isolation.
Use cases that demand it:
→ Adversarial AI agents executing tools
→ CI runners on shared clusters
→ Customer code in your platform
→ Multi-tenant labs with shared credentials
Namespaces alone are not enough.
Bengaluru, see you tomorrow! 🚀
Saiyam will be at the AI Infrastructure Meetup hosted by vCluster, connecting with the community and talking all things AI infrastructure, Kubernetes and platform engineering.
Come say hi if you’re attending
#AIInfrastructure#Kubernetes #vCluster
Hot take:
Most "AI inference platforms" should just be KServe + a thin internal API.
Stop buying $200K/yr SaaS.
KServe handles 90% of what your ML team needs. The other 10% is a 50-line wrapper.
The hard part isn't serving.
It's everything around it.
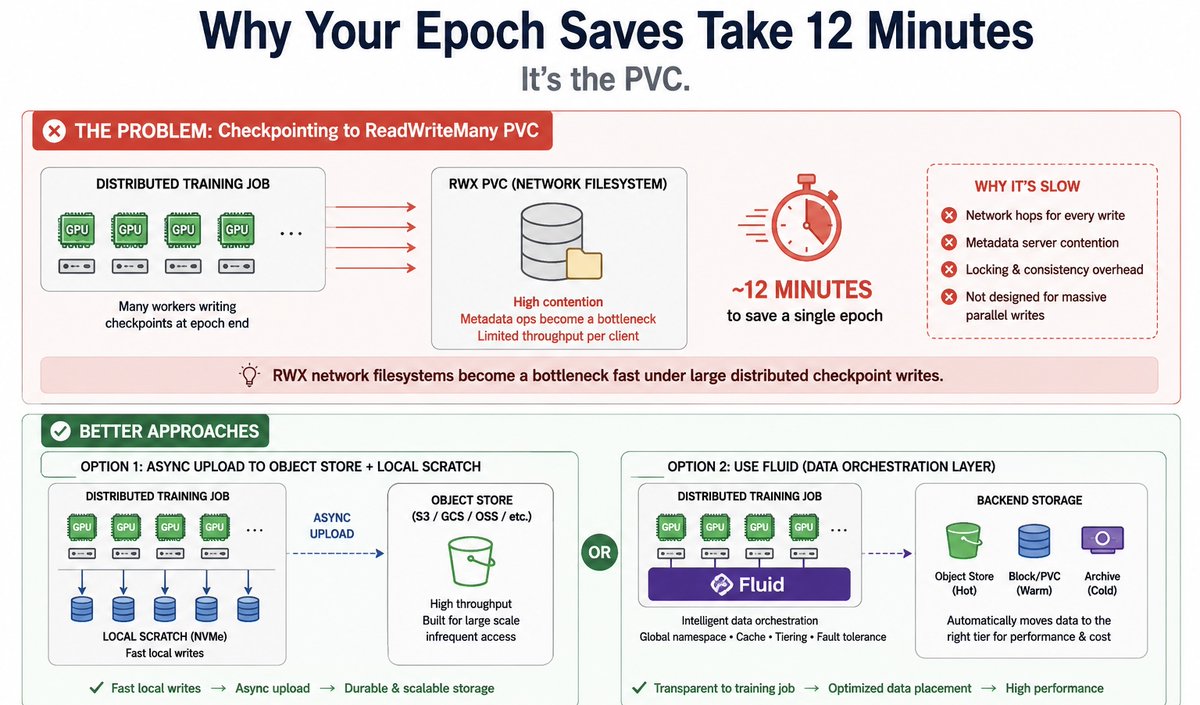
If you're checkpointing distributed training to a ReadWriteMany PVC and wondering why epoch saves take 12 minutes:
It’s the PVC.
RWX network filesystems become a bottleneck fast under large distributed checkpoint writes.
Use:
• async uploads to object storage + local scratch disks
• or a data orchestration layer like Fluid
Don’t force network filesystems to behave like high-throughput local storage for massive AI workloads.