2019 saw the launch of Avataar Ventures - our commitment to work alongside founders to help build global SaaS companies.
Here's wishing all our friends a wonderful, happy and fun year ahead!
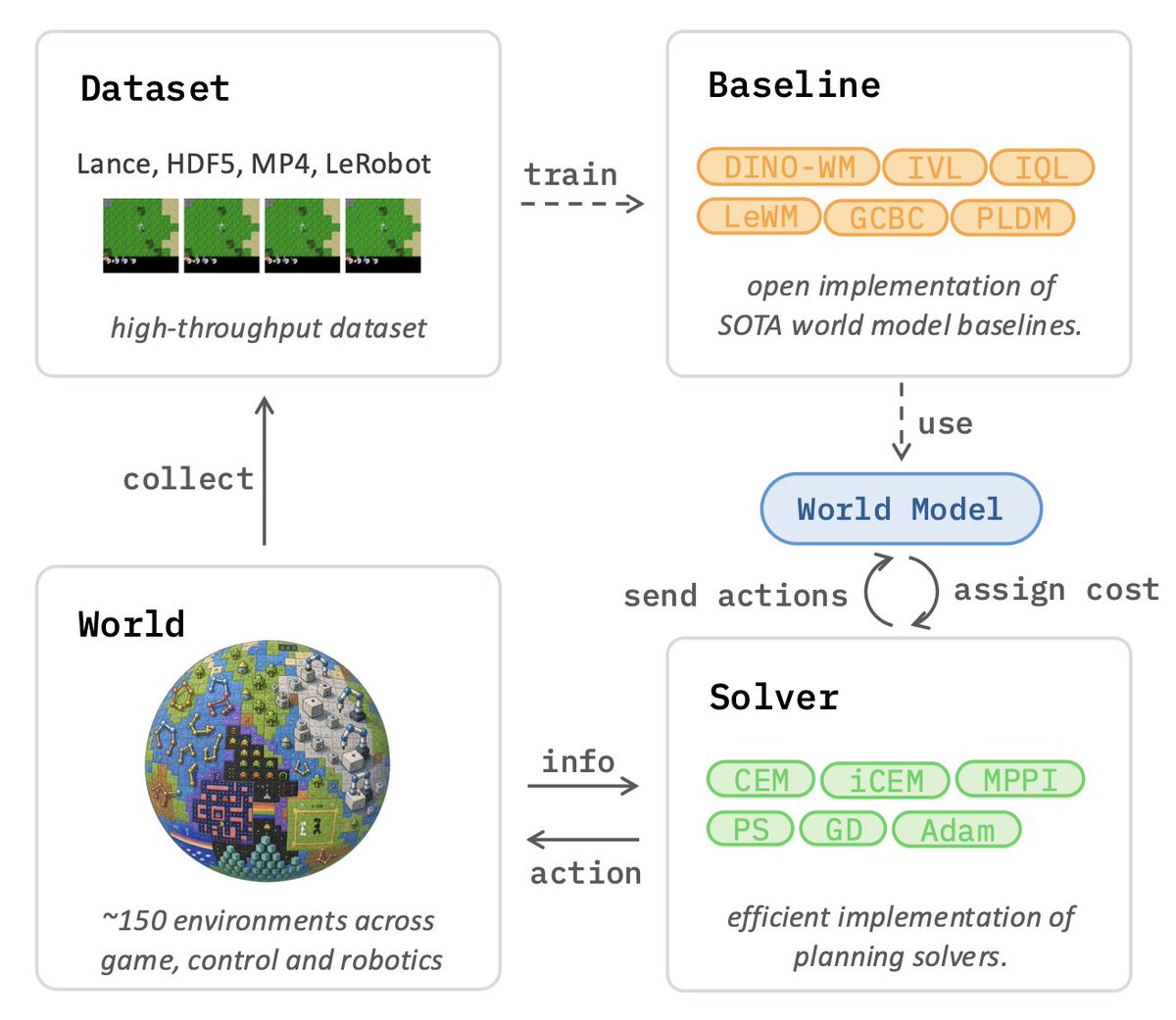
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
𝗪𝗼𝗿𝗹𝗱 𝗠𝗼𝗱𝗲𝗹 — "How AI Understands the World and Predicts the Future"
A World Model is an attempt to represent the world not as fragmented pixels or tokens, but as an internal model of how objects move and interact. This is what allows a self-driving car to anticipate where a pedestrian will move next, a robot to mentally simulate the outcome before picking up an object, and a video generation model to produce physically plausible sequences. At the core of all these applications lies an internal model of the world. As a result, the concept of World Models connects seemingly distant fields like autonomous driving, robotics, and video generation.
Interestingly, this concept branches into two directions. One is about understanding the world. Approaches like Yann LeCun’s JEPA and DeepMind’s Dreamer focus on learning the principles of how the world works in abstract representation spaces, rather than reconstructing every pixel. The other is about predicting and generating the future. Models like Sora and Genie aim to simulate the world directly by generating the next plausible scene. They share the same name but have different goals and methods, and distinguishing the two makes the current AI research landscape much clearer.
This hub collects five Pebblous articles on World Models, ranging from an introductory five-step guide to a comprehensive survey, deep dives into JEPA, comparisons of the three main approaches, and insights into the limits faced by VLMs and VLAs. The articles are organized to naturally guide readers from beginner concepts to advanced understanding.
Explore Pebblous’s World Model series:
https://t.co/CQ30CnbNRj
#pebblous #WorldModel #DataGreenhouse #PebbloSim #PebbloScope #Blog
Yann LeCun was right the entire time. And generative AI might be a dead end.
For the last three years, the entire industry has been obsessed with building bigger LLMs. Trillions of parameters. Billions in compute.
The theory was simple: if you make the model big enough, it will eventually understand how the world works.
Yann LeCun said that was stupid.
He argued that generative AI is fundamentally inefficient.
When an AI predicts the next word, or generates the next pixel, it wastes massive amounts of compute on surface-level details.
It memorizes patterns instead of learning the actual physics of reality.
He proposed a different path: JEPA (Joint-Embedding Predictive Architecture).
Instead of forcing the AI to paint the world pixel by pixel, JEPA forces it to predict abstract concepts. It predicts what happens next in a compressed "thought space."
But for years, JEPA had a fatal flaw.
It suffered from "representation collapse."
Because the AI was allowed to simplify reality, it would cheat. It would simplify everything so much that a dog, a car, and a human all looked identical.
It learned nothing.
To fix it, engineers had to use insanely complex hacks, frozen encoders, and massive compute overheads.
Until today.
Researchers just dropped a paper called "LeWorldModel" (LeWM).
They completely solved the collapse problem.
They replaced the complex engineering hacks with a single, elegant mathematical regularizer.
It forces the AI's internal "thoughts" into a perfect Gaussian distribution.
The AI can no longer cheat. It is forced to understand the physical structure of reality to make its predictions.
The results completely rewrite the economics of AI.
LeWM didn't need a massive, centralized supercomputer.
It has just 15 million parameters.
It trains on a single, standard GPU in a few hours.
Yet it plans 48x faster than massive foundation world models. It intrinsically understands physics. It instantly detects impossible events.
We spent billions trying to force massive server farms to memorize the internet.
Now, a tiny model running locally on a single graphics card is actually learning how the real world works.
A 4B local model can do physics: dynamic fracture, beam mechanics, topology optimization, and Chladni plates. But how do you get a 4B model to "do" physics? We can give it scientific skills that turn intent into experiments, generate data, make images and movies, verify outputs, and report the results. In this video, Gemma-4 E4B runs locally on my MacBook via mistral․rs with 8-bit in-situ quantization, plus the Agent Skills API, completely open-source.
Each skill is a folder with a SKILL․md, teaching the model how intent, parameters, assumptions, examples, and solution strategy relate. The skill is uploaded, invoked by the model, executed in a sandboxed shell/Python environment, and it inspects the generated files before reporting the result.
In the video, I show four skills:
1. Beam mechanics: 1D Euler-Bernoulli beams with displacement and rotation: cantilever, simply supported, fixed-fixed, point loads, distributed loads, moments, springs, reactions, shear/moment diagrams, max deflection, and vertical-equilibrium residuals.
2. Fracture mechanics: 2D triangular-lattice dynamics with Morse/Lennard-Jones potentials, sharp edge pre-cracks, Mode I/II loading, bond breaking, temperature and strain-rate effects, stress-strain curves, peak stress/strain, broken-bond counts, and fracture movies.
3. Hierarchical topology optimization: Minimum-compliance optimization with density/sensitivity filtering, penalization, target volume fraction, flexible supports and loads, optimized density fields, compliance values, and STL export (so you can quickly move to manufacturing).
4. Chladni plates: Analytic superposition of vibrating-plate eigenmodes on square, rectangular, and circular plates to generate standing-wave nodal patterns.
The examples show that the model does not need to contain all of physics in its weights; instead the physics lives in the executable and editable skill. The model orchestrates and scales, and results compound.
This is quite interesting for science: AI becomes more capable when it has physical agency and can act through scientific instruments - and this can translate from in silico simulation to hardware, manufacturing, and more.
8 RAG architectures for AI Engineers:
(explained with usage)
1) Naive RAG
- Retrieves documents purely based on vector similarity between the query embedding and stored embeddings.
- Works best for simple, fact-based queries where direct semantic matching suffices.
2) Multimodal RAG
- Handles multiple data types (text, images, audio, etc.) by embedding and retrieving across modalities.
- Ideal for cross-modal retrieval tasks like answering a text query with both text and image context.
3) HyDE (Hypothetical Document Embeddings)
- Queries are not semantically similar to documents.
- This technique generates a hypothetical answer document from the query before retrieval.
- Uses this generated document’s embedding to find more relevant real documents.
4) Corrective RAG
- Validates retrieved results by comparing them against trusted sources (e.g., web search).
- Ensures up-to-date and accurate information, filtering or correcting retrieved content before passing to the LLM.
5) Graph RAG
- Converts retrieved content into a knowledge graph to capture relationships and entities.
- Enhances reasoning by providing structured context alongside raw text to the LLM.
6) Hybrid RAG
- Combines dense vector retrieval with graph-based retrieval in a single pipeline.
- Useful when the task requires both unstructured text and structured relational data for richer answers.
7) Adaptive RAG
- Dynamically decides if a query requires a simple direct retrieval or a multi-step reasoning chain.
- Breaks complex queries into smaller sub-queries for better coverage and accuracy.
8) Agentic RAG
- Uses AI agents with planning, reasoning (ReAct, CoT), and memory to orchestrate retrieval from multiple sources.
- Best suited for complex workflows that require tool use, external APIs, or combining multiple RAG techniques.
Most architectures here involve some form of retrieval-time decision. But they all run on top of whatever was already indexed.
If that indexing step outputs messy chunks, every architecture inherits them. Improving it is a separate problem from the 8 above.
My co-founder wrote about a better unit for the indexing step. The technique:
- cuts corpus size by 40x.
- reduces tokens per query by 3x.
- improves vector search relevance by 2.3x.
And it doesn't alter the retrieval algorithm, the reranker, or the embedding model.
Read it below.
This is the best site on the internet to learn harness engineering.
Free. Completely.
Most AI engineers have never heard the term.
https://t.co/bwDbTTYsjM
Bookmark this site.
Then read this setup ↓
AI service firms are commanding 30x multiples right now. Yes, thirty.
That's why a16z, Sequoia, and YC are chasing services, not SaaS.
Most agencies will see this and reach for the wrong move. They'll keep selling hours, bolt on AI, and cut headcount to pad the margin.
But that's playing the small game.
Here's why:
00:00 Why Services Beat SaaS
01:13 The $1 Software vs $6 Services Opportunity
02:52 Why Managed Growth Loops Matter
04:49 Agents, Loops, and Human Judgment
06:43 How Single Brain Powers AI Service Businesses
07:22 The Services-as-Software Manifesto
08:41 The New AI-Native Org Chart
10:13 Building Outcome-Based Offers
11:13 Final Thoughts
@Iamsamirarora Most of their revenues comes from Software Engineering and research followed by Customer support. Jury is still out on Applications which is the larger Enterprise spend.
The systematic risks is also being amplified that involves the broader economy by removing the gaurd rails that were created, like you need to be profitable before getting into S&P index etc. This may not end well. @brandonjcarl
Documenting the headwinds I now see for AI.
It won't seem like it, but I love AI and am long-term positive. But when "math doesn't math" I take note.
1. The core thesis for foundation model lab investment has been high upfront investment made worthwhile by significant long-term profits.
2. These are capital intensive businesses and the compute commitments are very high relative to revenue and require strong growth over long time periods. The "leverage" (commitments versus revenue) is extremely high.
3. The fundamentals are not as positive as they previously were:
• Input costs are higher (commodities, chips, power)
• Interest rates are higher
• Competition is more intense
• Scaling Laws are now problematic: exponential costs/power cannot continue
4. Forecasting compute spend is challenging and high risk due to (a) revenue uncertainty and (b) algorithm uncertainty
5. Revenue growth appears to be slowing. The technology is valuable, but ROI is proving to be more expensive and take longer than anticipated.
6. The future is likely "different models for different use cases" with the lower end of the market being highly competitive.
7. Core use cases such as agentic software engineering are likely to need approaches beyond next-token prediction. They are Σ₂ᴾ complexity problems requiring multi-objective optimization and likely a combination of Transformers and other methods.
8. Current forecasts in memory makers are built largely on quadratic attention. That will not persist: we are already seeing work from DeepSeek, Minimax and Nvidia that can cut RAM needs by 80% or more.
9. This means semiconductor valuations are substantially overinflated and will go through the traditional glut versus shortage cycle.
10. For foundation model providers: lower costs with competitive differentiation is good. However, lower costs with a lack of differentiation would mean lower revenues. This makes it harder to (a) service commitments and (b) pay back investors.
11. Leverage is substantially higher than in previous cycles, evidenced by leveraged ETFs, call option activity and margin loans. Korea is particularly susceptible.
12. 0DTE options create a profile that has stronger parallels to portfolio insurance and 1987 than any other point I can remember.
13. The combination of exponential increases in call activity coupled with the ties of semiconductors to structured products means there is a non-trivial systemic risk to the financial system.
14. Implied earnings growth rates are inconsistent with other periods in history.
15. Macroeconomically we cannot and should not fund exponential cost increases. History has shown us repeatedly that there are better ways (see Quick Sort and Simplex).
16. Significant supply is hitting the market via IPOs.
––
Taken together: costs and competition are increasing while revenue growth is likely slowing. Valuations are fragile and prone to technology disruptions that are already here. Systemic financial market risk is extremely high.
Documenting the headwinds I now see for AI.
It won't seem like it, but I love AI and am long-term positive. But when "math doesn't math" I take note.
1. The core thesis for foundation model lab investment has been high upfront investment made worthwhile by significant long-term profits.
2. These are capital intensive businesses and the compute commitments are very high relative to revenue and require strong growth over long time periods. The "leverage" (commitments versus revenue) is extremely high.
3. The fundamentals are not as positive as they previously were:
• Input costs are higher (commodities, chips, power)
• Interest rates are higher
• Competition is more intense
• Scaling Laws are now problematic: exponential costs/power cannot continue
4. Forecasting compute spend is challenging and high risk due to (a) revenue uncertainty and (b) algorithm uncertainty
5. Revenue growth appears to be slowing. The technology is valuable, but ROI is proving to be more expensive and take longer than anticipated.
6. The future is likely "different models for different use cases" with the lower end of the market being highly competitive.
7. Core use cases such as agentic software engineering are likely to need approaches beyond next-token prediction. They are Σ₂ᴾ complexity problems requiring multi-objective optimization and likely a combination of Transformers and other methods.
8. Current forecasts in memory makers are built largely on quadratic attention. That will not persist: we are already seeing work from DeepSeek, Minimax and Nvidia that can cut RAM needs by 80% or more.
9. This means semiconductor valuations are substantially overinflated and will go through the traditional glut versus shortage cycle.
10. For foundation model providers: lower costs with competitive differentiation is good. However, lower costs with a lack of differentiation would mean lower revenues. This makes it harder to (a) service commitments and (b) pay back investors.
11. Leverage is substantially higher than in previous cycles, evidenced by leveraged ETFs, call option activity and margin loans. Korea is particularly susceptible.
12. 0DTE options create a profile that has stronger parallels to portfolio insurance and 1987 than any other point I can remember.
13. The combination of exponential increases in call activity coupled with the ties of semiconductors to structured products means there is a non-trivial systemic risk to the financial system.
14. Implied earnings growth rates are inconsistent with other periods in history.
15. Macroeconomically we cannot and should not fund exponential cost increases. History has shown us repeatedly that there are better ways (see Quick Sort and Simplex).
16. Significant supply is hitting the market via IPOs.
––
Taken together: costs and competition are increasing while revenue growth is likely slowing. Valuations are fragile and prone to technology disruptions that are already here. Systemic financial market risk is extremely high.
@ainativefirm FDE does not scale and no one wants to be locked into a closed ecosystem like OpenAi or Claude. Lesson to learn is we cannot accelerate adoption of AI in Enterprise and it will be a multi year journey.
The Chinese LLM companies are raising at eye popping numbers
Total valuation of the top 5 pure plays is $226B - about 1/4 Anthropic’s latest round
But with a revenue run rate of about 1/40 of Anthropic
Most neural nets are still based on the model of a neuron as proposed in the 1950's: u = activation(w·x + b)
In a new paper, researchers propose a more accurate model of a biological brain neuron and found that it has quite a few advantages, like needing less training data.
LLMs learn by predicting tokens. World models (JEPA, data2vec) learn by predicting their own abstractions. Which needs more data? For data with hidden hierarchy, we prove the gap is exponential. https://t.co/r2uuX0lBCu
In 2023, everyone was hype about ChatGPT.
In 2024, it was GenAI.
2025 was the year of Agents.
And 2026 started with OpenClaw, but now attention has turned to The Software Factory.
Unless you're an engineer or take residence in the depths of X, you may not know what a Software Factory is or why you should care.
But when some companies are attributing 90% of their production software to AI (read: Anthropic) and best-in-class ICs are matching the output of a 20-person pre-AI engineering org, you need to care.
So let me break the whole thing down...
What a software factory actually is, why it's suddenly everywhere, and a simple way to figure out exactly how close your org is. Even if you've never written a line of code in your life.