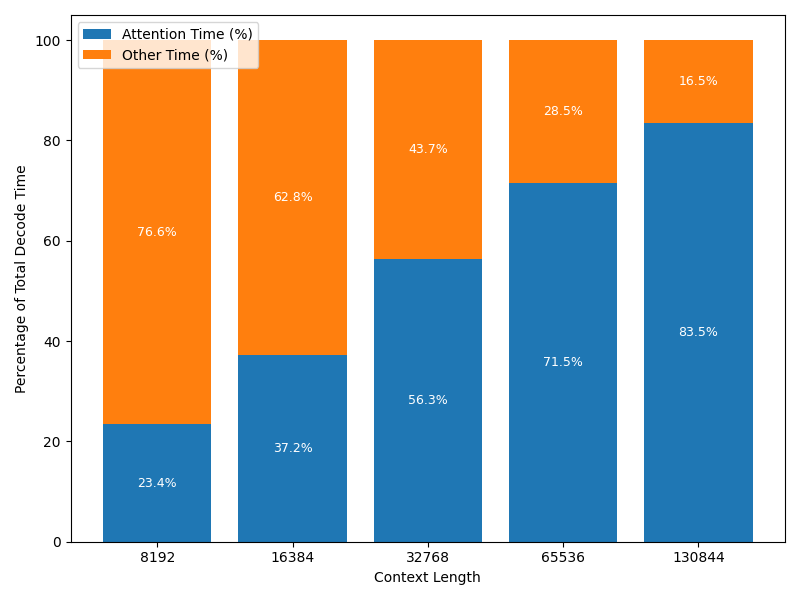
Long-context inference is hitting a wall. 🛑
As context grows, Attention becomes the villain.
Why?
• Decode: Attention scales linearly (O(N)), while the rest of the model stays constant (O(1)).
• Prefill: Attention explodes quadratically(O(N²)).
Can we do better?(1/9)
Evaluation of LLM serving systems is tricky because several factors influence performance (prefill length, decode length, parallelization) and there are multiple metrics we care about (throughput, ttft, tpot/tbt). We identify common pitfalls and a checklist to avoid them.
The bitter lesson of AI infra: The hardest part about building faster LLM inference systems is not designing the systems, but rather it is evaluating if the system is actually faster! 🤔
This graph from a recent top systems venue paper about long-context serving shows average normalized input token latency for a trace with both short and 100K+ token requests. System X looks like a clear win: lower normalized latency and higher request rates. But normalized metrics can obscure the actual user experience: at those rates, long inputs see >2hr delays to the first token!
Let’s do the math!🧮
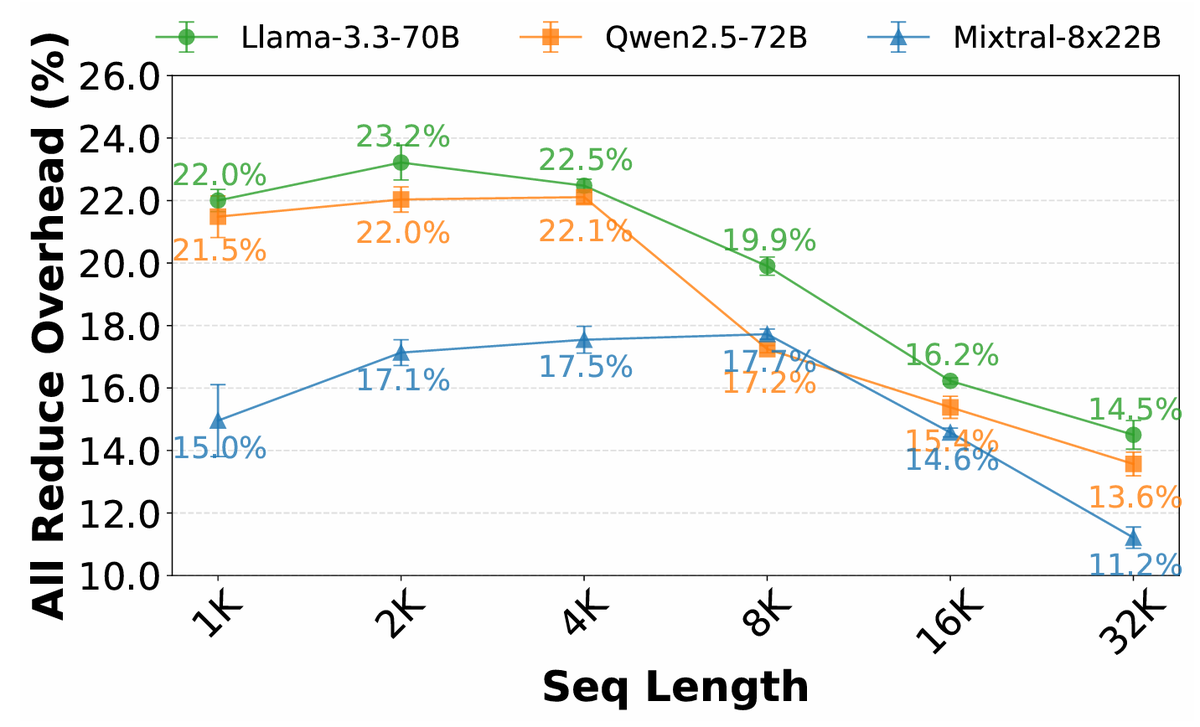
We have released the source code and benchmarks of TokenWeave. TokenWeave speeds up distributed LLM inference via compute–communication overlap and fused AllReduce, RMSNorm, and residual addition.
Code: https://t.co/jJtRirY0IC
Paper: https://t.co/n0SDVdjyQn
Try it out!
TokenWeave – Efficient Compute-Communication Overlap for Distributed LLM Inference.
Why? Even with highspeed NVLink on H100 DGX, communication overhead for distributed LLM inference can be > 20 %! Can we recover this overhead? (1/10)
🚨 Are LLM compression methods (𝘲𝘶𝘢𝘯𝘵𝘪𝘻𝘢𝘵𝘪𝘰𝘯, 𝘱𝘳𝘶𝘯𝘪𝘯𝘨, 𝘦𝘢𝘳𝘭𝘺 𝘦𝘹𝘪𝘵) too good to be true and are existing eval metrics sufficient? We've looked into it in our latest research at @MSFTResearch 🧵 (1/n)
https://t.co/aW6cGMvTPv
[MSFT] Accuracy is Not All You Need
https://t.co/2atYvOW9cc
in comparing quantized/pruned/sparsified vs 16bit models,
* observes drastic flipping in correct<->wrong answer pairs, even with otherwise good accuracy
* proposes replacing eval accuracy w/ either KL-Divergence or flips
* explains this phenomenon as a consequence of the difference in eval Top Margin for correct vs wrong answers
🚀 Introducing Metron: Redefining LLM Serving Benchmarks! 📊
Tired of misleading metrics for LLM performance? Our new paper introduces a holistic framework that captures what really matters - the user experience! 🧠💬
https://t.co/Q02Fj0IUKa
#LLM#AI#Benchmark
Did you ever feel that @chatgpt is done generating your response and then suddenly a burst of tokens show up? This happens when the serving system is prioritizing someone else’s request before generating your response. But why? well to reduce cost. 🧵
Ever wondered why @OpenAI charges 2x price for output tokens compared to input? Turns out that an output token can be up to 200x more compute time than an input token. Why? We explored this phenomenon during my internship at @MSFTResearch. 🧵







![main_horse's tweet photo. [MSFT] Accuracy is Not All You Need
https://t.co/2atYvOW9cc
in comparing quantized/pruned/sparsified vs 16bit models,
* observes drastic flipping in correct<->wrong answer pairs, even with otherwise good accuracy
* proposes replacing eval accuracy w/ either KL-Divergence or flips
* explains this phenomenon as a consequence of the difference in eval Top Margin for correct vs wrong answers](https://pbs.twimg.com/media/GSgKKE1WMAAQZYh.jpg)
![main_horse's tweet photo. [MSFT] Accuracy is Not All You Need
https://t.co/2atYvOW9cc
in comparing quantized/pruned/sparsified vs 16bit models,
* observes drastic flipping in correct<->wrong answer pairs, even with otherwise good accuracy
* proposes replacing eval accuracy w/ either KL-Divergence or flips
* explains this phenomenon as a consequence of the difference in eval Top Margin for correct vs wrong answers](https://pbs.twimg.com/media/GSgJQoyWMAA7Z5J.jpg)
![main_horse's tweet photo. [MSFT] Accuracy is Not All You Need
https://t.co/2atYvOW9cc
in comparing quantized/pruned/sparsified vs 16bit models,
* observes drastic flipping in correct<->wrong answer pairs, even with otherwise good accuracy
* proposes replacing eval accuracy w/ either KL-Divergence or flips
* explains this phenomenon as a consequence of the difference in eval Top Margin for correct vs wrong answers](https://pbs.twimg.com/media/GSgIuRdWIAAqBfj.jpg)





![main_horse's tweet photo. [MSFT] Accuracy is Not All You Need
https://t.co/2atYvOW9cc
in comparing quantized/pruned/sparsified vs 16bit models,
* observes drastic flipping in correct<->wrong answer pairs, even with otherwise good accuracy
* proposes replacing eval accuracy w/ either KL-Divergence or flips
* explains this phenomenon as a consequence of the difference in eval Top Margin for correct vs wrong answers](https://pbs.twimg.com/media/GSgLEbnWwAAzLuo.jpg)






























