What if you could turn any number of photos (3, 8, 15, or even 60) into one clean 3D surface (pts & mesh) with Flow Matching?
Check out our new work, Surflo: Consistent 3D Surface Flow Model with Global State. 🧵
1/n
🔗https://t.co/lBcJRgpfdg
We will release our code and data asap, so please stay tuned!
Many thanks to my amazing coauthors:
@nico_dufour@ShuNakamuraW@JiahuiLei1998@kyoto_vision@akanazawa
📜arXiv: https://t.co/jVka6OMXNT
🔗Project: https://t.co/lBcJRgpfdg
💻Code (soon): https://t.co/XpHQtmZHXJ
8/8
#NeurIPS2025 paper: "Generative Perception of Shape and Material from Differential Motion"!
We explore a generative framework for perceiving shape & material, showing how motion resolves visual ambiguities. Project page: https://t.co/zx1mORrD7g
Don't forget to come visit Nicole to discuss her latest work on Generative Perception!!!
NeurIPS poster session in San Diego 🎃📷Fri (12/5) 11am Exhibit Hall C,D,E #4413🎃
@kyoto_vision Emergent behavior: 1️⃣ For static images, it generates diverse, plausible hypotheses; 2️⃣ For motion videos, predictions concentrate near the true explanations.
It robustly disentangles shape & material on complex reflective objects and real-world videos. 🌍 (4/n)
Excited to share our #NeurIPS2025 paper: "Generative Perception of Shape and Material from Differential Motion"!
We explore a generative framework for perceiving shape & material, showing how motion resolves visual ambiguities.
Project page: https://t.co/BT7EhItxIe
📢 SHeaP: Self-Supervised Head Predictor Learned via 2D Gaussians 📢
Given a single input image, we predict accurate 3D head geometry, pose, and expression.
Previous works (e.g. DECA, EMOCA) use differentiable mesh rasterization to learn a self-supervised head geometry predictor via a photometric reconstruction loss. We borrow these ideas, but our key insight is to replace the mesh rendering with 2D Gaussian Splatting. This leads to much higher accuracy of the underlying predicted geometry and thus more gradient signal during training.
🌍 https://t.co/BnX67AE1GB
🎥 https://t.co/Ppv7amKldH
Great work by @liamschoneveld@_davidedavoli_@jiapeng_tang
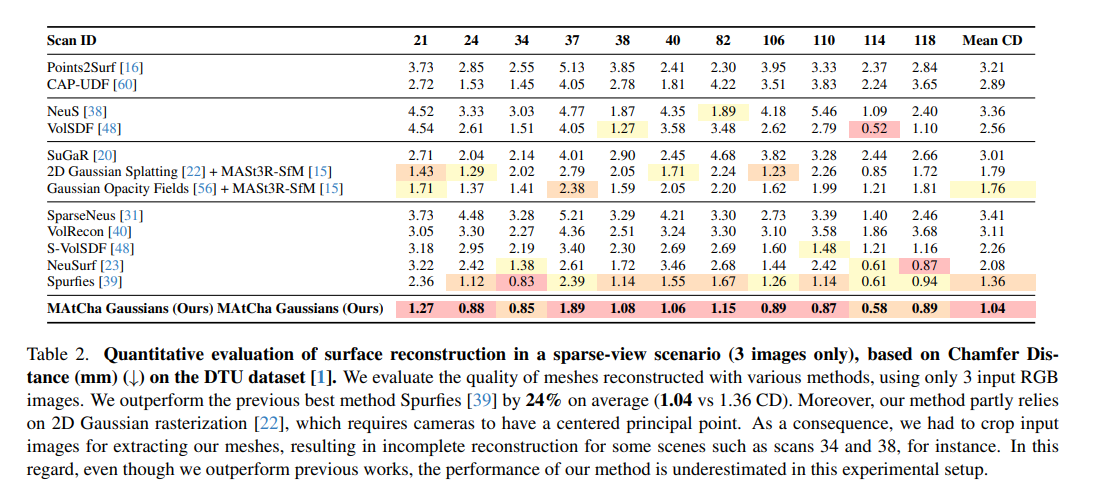
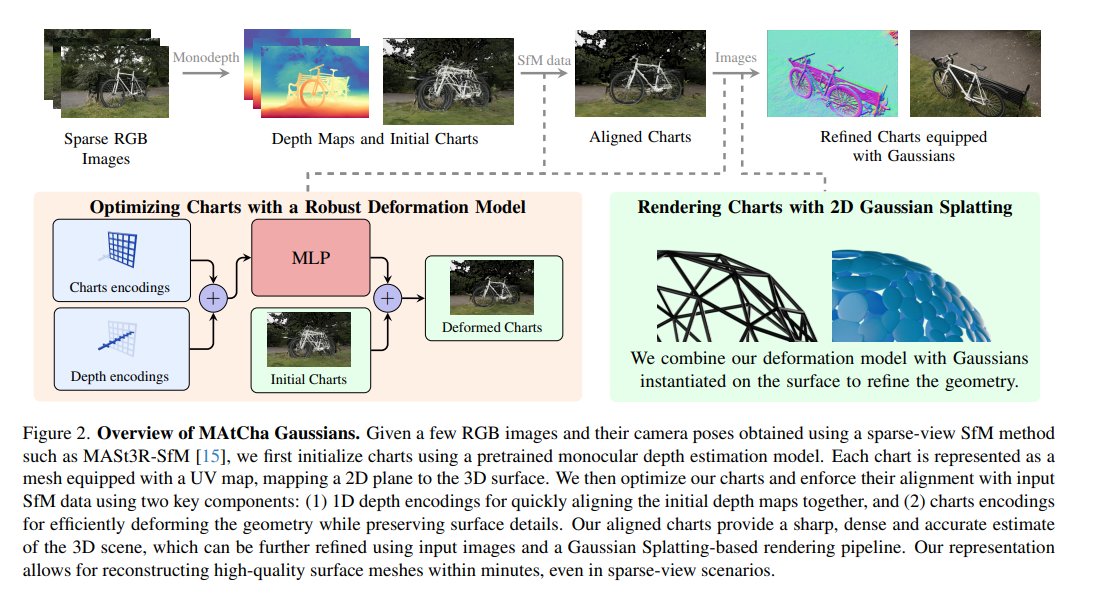
💻We've released the code for our #CVPR2025 paper MAtCha!
🍵MAtCha reconstructs sharp, accurate and scalable meshes of both foreground AND background from just a few unposed images (eg 3 to 10 images)...
...While also working with dense-view datasets (hundreds of images)!
Extrinsic Camera Calibration From a Moving Person #IROS22
Did you know that you are a calibration target? We use a moving person as a collection of oriented points for extrinsic calibration of casually installed cameras. No more large checkerboards.
https://t.co/cr7fORmTmE
⚠️Reconstructing sharp 3D meshes from a few unposed images is a hard and ambiguous problem.
☑️With MAtCha, we leverage a pretrained depth model to recover sharp meshes from sparse views including both foreground and background, within mins!🧵
🌐Webpage: https://t.co/di9e52XqFb
MAtCha Gaussians: Atlas of Charts for High-Quality Geometry and Photorealism From Sparse Views
Abstract (excerpt):
We present a novel appearance model that simultaneously achieves explicit high-quality 3D surface mesh recovery and photorealistic novel view synthesis from sparse view samples. Our key idea is to model the underlying scene geometry Mesh as an Atlas of Charts, which we render with 2D Gaussian surfels (MAtCha Gaussians).
MAtCha distills high-frequency scene surface details from an off-the-shelf monocular depth estimator and refines them through Gaussian surfel rendering. The Gaussian surfels are attached to the charts on the fly, satisfying the photorealism of neural volumetric rendering and the crisp geometry of a mesh model—two seemingly contradicting goals in a single model.
At the core of MAtCha lies a novel neural deformation model and a structure loss that preserve the fine surface details distilled from learned monocular depths while addressing their fundamental scale ambiguities. Results of extensive experimental validation demonstrate MAtCha's state-of-the-art quality in surface reconstruction and photorealism, on par with top contenders but with a dramatic reduction in the number of input views and computational time.
Multistable Shape from Shading Emerges from Patch Diffusion #NeurIPS2024 Spotlight
X. Nicole Han, T. Zickler and K. Nishino (Harvard+Kyoto)
Diffusion-based SFS lets you sample multistable shape perception!
Come see @nahelocin Th 12/12 11am East A-C 1308
https://t.co/4c8Mb0mlnB
MAtCha Gaussians: Atlas of Charts for High-Quality Geometry and Photorealism From Sparse Views
@antoine_guedon, Tomoki Ichikawa, Kohei Yamashita, Ko Nishino
tl;dr: underlying scene geometry mesh->an Atlas of Charts->render with 2D Gaussian surfels
https://t.co/fqWDue9y7r
PBDyG: Position Based Dynamic Gaussians for Motion-Aware Clothed Human Avatars
Shota Sasaki, Jane Wu, Ko Nishino
Human avatar with movement- (not pose-)dependent clothing as 3D GS simulated with PBD attached to SMPL, all recovered from multiview video.
https://t.co/2O9mcIbIcV
HeatFormer: A Neural Optimizer for Multiview Human Mesh Recovery
Yuto Matsubara and Ko Nishino (Kyoto University)
Occlusion-aware, view-flexible multiview human shape and pose recovery as learned optimization.
https://t.co/sIOhj5x7pW