Next-Edit is live in Kilo, powered by Mercury Edit 2 from @_inception_ai.
Autocomplete predicts the next few tokens ahead of your cursor. Next-Edit predicts your next actual edit anywhere in the file. Hit Tab to accept.
And it's free for everyone for 30 days!
Welcome to the diffusion era.
We bet on parallel generation years ago, when it was a contrarian idea. It's great to see the industry arrive.
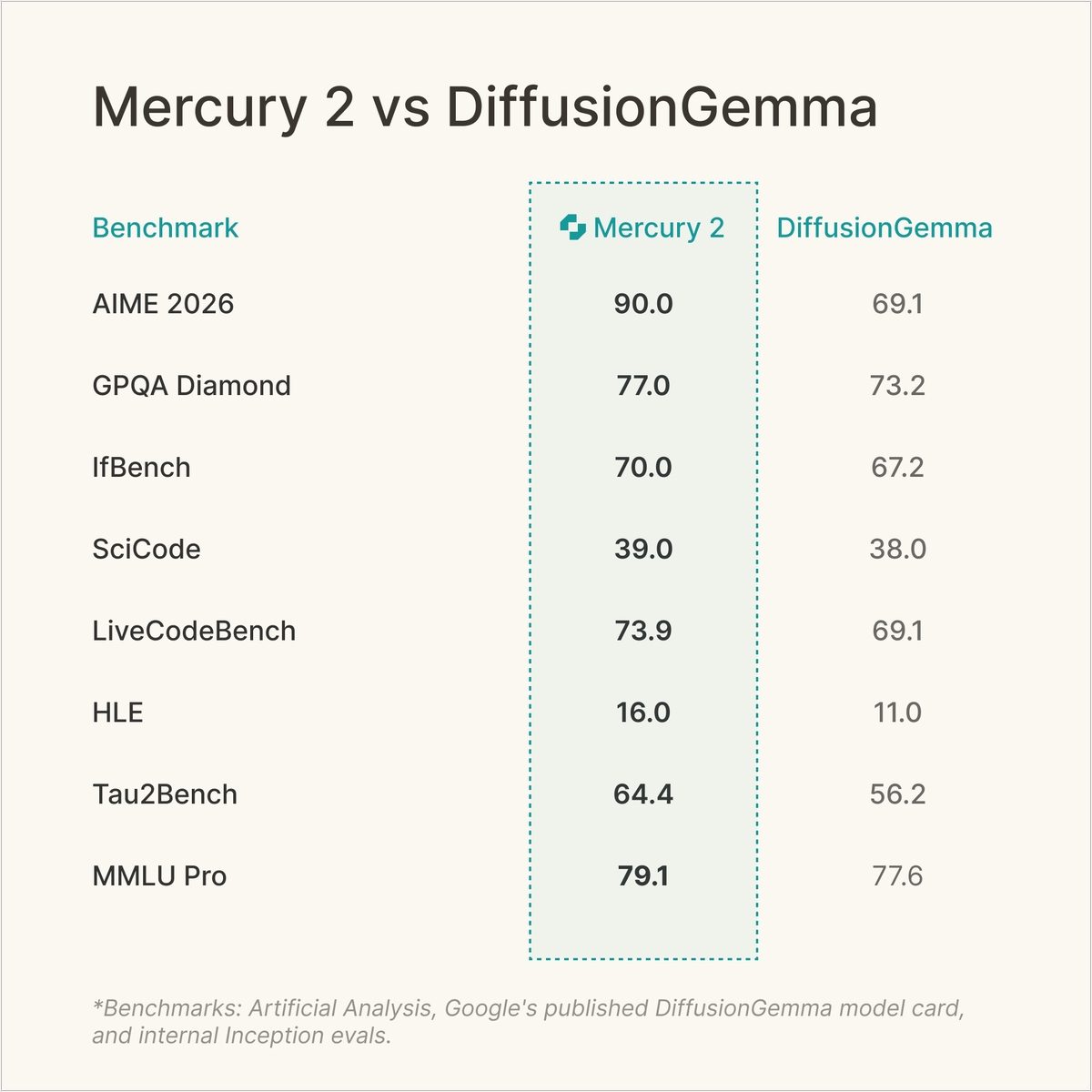
Mercury 2 continues to lead the Pareto frontier for quality, speed, and cost among publicly available diffusion LLMs.
Why are autoregressive LLMs still generating one token at a time?
That question led to the breakthrough behind the first commercially available diffusion LLM. The team applied diffusion, the technical approach that transformed image and video generation, to text and code.
The result: a dLLM that matched the quality of traditional speed-optimized autoregressive models while running 10x faster.
Our CEO @StefanoErmon joined @YourProtagonist, host of the Fund/Build/Scale Podcast, to talk about the journey from lab to commercial product.
Full episode linked in thread.
Excited to see Mercury 2 live on @baseten
Mercury 2 delivers Groq/Cerebras-like speeds (>1000 tokens/sec) with quality comparable to speed-optimized models like Claude Haiku
If you have latency-sensitive workloads we’d love to hear from you.
We are excited to announce that we have partnered with @_inception_ai to make Mercury 2 available on Baseten. This makes us the first inference platform to bring Inception’s diffusion LLM to production.
Inception’s dLLM architecture fixes the bottlenecks of sequential token generation and can deliver 1,000+ tokens/sec on standard NVIDIA GPUs. Early users like @augmentcode have seen impressive results, such as an 82% reduction in latency and 90% cost savings, while maintaining high quality.
The fastest reasoning LLM is now in production on Baseten.
Mercury 2 is a diffusion LLM, so it generates tokens in parallel and hits 1,000+ tokens/sec on @NVIDIAAI GPUs, speeds that used to require specialized hardware.
@augmentcode is already using Mercury 2, cutting cost 90% and latency 82%.
Proud to partner with the @baseten team to bring dLLMs to production.
Honored that @_inception_ai has been named to the @WEF's 2026 Technology Pioneers community.
Diffusion reshaped image generation. With Mercury 2 we're bringing that leap to text and code. Grateful to the team and everyone who backed us early.
Excited to see Mercury 2 recognized by @ArtificialAnlys as the fastest model.
Autoregressive models generate one token at a time, while diffusion LLMs refine many tokens in parallel.
Mercury 2 shows what this unlocks in practice.
https://t.co/kLY0An0pgn
Autoregressive models generate text one token at a time.
That sequential process becomes a major bottleneck at inference scale with:
-memory-bound workloads
-poor GPU utilization
-growing infrastructure demands
Diffusion LLMs work differently.
Instead of generating tokens one at a time, Mercury refines multiple tokens in parallel, which is why diffusion models can achieve dramatically higher throughput.
Part 2 from @StefanoErmon's keynote at @StartupGrind on why diffusion models are the future of LLMs.
Hiring our first Forward Deployed AI Engineer at Inception.
We built the world's fastest reasoning LLM and the first commercially available diffusion LLM, Mercury 2.
>1,000 tokens/sec on standard GPUs via diffusion, 10x faster than speed-optimized autoregressive models at comparable quality.
Enterprise demand has outpaced what we can serve as a research-led team. You'll define how we run customer engagements, scope POCs, build evals, turn deployments into a flywheel for the next generation of models.
Apply:https://t.co/x9tHAHgv69
Will the next decade of LLMs run on autoregression, or on diffusion?
One of the top questions we got at MLSys this week.
Part 6, the final part of our founder story series with @timt at @MenloVentures.
Featuring @StefanoErmon, @adityagrover_, @volokuleshov
Day 2 at @MLSysConf.
Thanks to everyone who came by yesterday. The conversations on diffusion for language, the future of language models, and what fast inference unlocks have been the highlight.
Come find us at the booth today and meet the team behind Mercury 2. And join us tonight for drinks.
🔗 https://t.co/qnIITs3Rtz
We're at @MLSysConf in Seattle!
Catch our co-founder and Chief Scientist @volokuleshov on stage today at 2:30pm.
Learn more about diffusion LLMs and how Mercury 2 hits >1,000 tok/s on standard GPUs, at comparable quality to speed-optimized autoregressive models.
Swing by the booth after to meet the team.
Today's autoregressive models generate one token at a time.
Mercury 2 generates tokens in parallel. Over 1,000 tok/sec on standard GPUs, at comparable quality to speed-optimized models.
Since launch, the community has been showing what diffusion LLMs can unlock. Thanks to the team at Clyep for the breakdown.
Inception is heading to #MLSys2026 in Seattle next week.
Two things worth your time:
1️⃣ Mon 5/18 at 2pm: lightning talk from @volokuleshov, co-founder of Inception. Come hear about a new generation of training and inference for diffusion-based language models.
2️⃣ Tues 5/19 evening: drinks + conversations with @akashpalrecha98, @apoorv_umang, @sawyerbirnbaum, and the team.
👇 Luma RSVP below
Inception is hiring a Head of Product
This is a hands-on role for a technical product lead who wants to help build the next generation of LLMs. You'd work directly with S-tier AI researchers at the frontier of model architecture, inference, and enterprise deployment.
We're one of the only AI labs where the product is live in production with enterprises and AI-native companies today - and the valuation is at a stage where your equity has real upside (not financial advice).
The bar is high. The role is not a walk in the park. But if you’ve been watching the frontier AI labs from the sidelines and waiting for the seat where you can help build foundational AI infrastructure before the category is obvious, this is it. DM me. Bay Area only.
https://t.co/Uj6zvC8zJ2
At @augmentcode , we took a counter-intuitive bet on our AI architecture.
Instead of using the primary coding model to preserve KV cache (the industry standard), we used Mercury 2 by @_inception_ai as a dedicated subagent.
The payoff for our users:
82% faster context compaction,
90% lower summarization costs,
<1s tool-search summaries,
30% lower LLM spend via Prism routing
Read the full story here: https://t.co/UN7xxX8Ap6