huge respect for justin bieber switching from autoregressive to diffusion-based text generation while headlining coachella.
most artists just soundcheck. justin swapped out his LLM provider backstage... you can see him here (real photo!) spinning up mercury 2 from @_inception_ai on a dedicated instance, watching tokens materialize in parallel instead of one at a time like some kind of animal, refreshing his p99 latency graphs and whispering "discrete diffusion" to himself before performing for 100,000+ people.
most performers have a vocal warmup routine. justin's is curl -X POST https://t.co/2c2yfycASz.
justin ships nothing at 2500ms. neither should you.
Mercury 2 is now available on @baseten!
If you're building a multi-agent system, coding tool, voice application, or anything where you're currently routing all traffic to a single expensive LLM, Mercury is worth testing. Same intelligence tier as Haiku and Flash, 5-7x faster, sub-500ms to first token.
We’re running a limited batch of free POCs. If you want to see the numbers on your own traffic, start here:
https://t.co/2XIciEkh6K
Most researchers agree that autoregression is best when memory bandwidth is cheap and diffusion is best when FLOPS are cheap. They also admit the future of compute is all FLOPS because memory scaling is hard and scaling FLOPS is easy. So why not go all in on diffusion????
@DavidSHolz That’s exactly the bet we’re making at @_inception_ai
We’re already matching speed-optimized models from frontier labs on quality, while being faster and more cost efficient. That gap will only widen as we continue to scale.
going to start threading the autoregressive model killer candidates emerging
1/ @_inception_ai diffusion LLM Mercury 2 rips 4x the tokens per second vs autoregressive LLMs (@StefanoErmon & @phylera14)
Inception is hiring a Head of Product
This is a hands-on role for a technical product lead who wants to help build the next generation of LLMs. You'd work directly with S-tier AI researchers at the frontier of model architecture, inference, and enterprise deployment.
We're one of the only AI labs where the product is live in production with enterprises and AI-native companies today - and the valuation is at a stage where your equity has real upside (not financial advice).
The bar is high. The role is not a walk in the park. But if you’ve been watching the frontier AI labs from the sidelines and waiting for the seat where you can help build foundational AI infrastructure before the category is obvious, this is it. DM me. Bay Area only.
https://t.co/Uj6zvC8zJ2
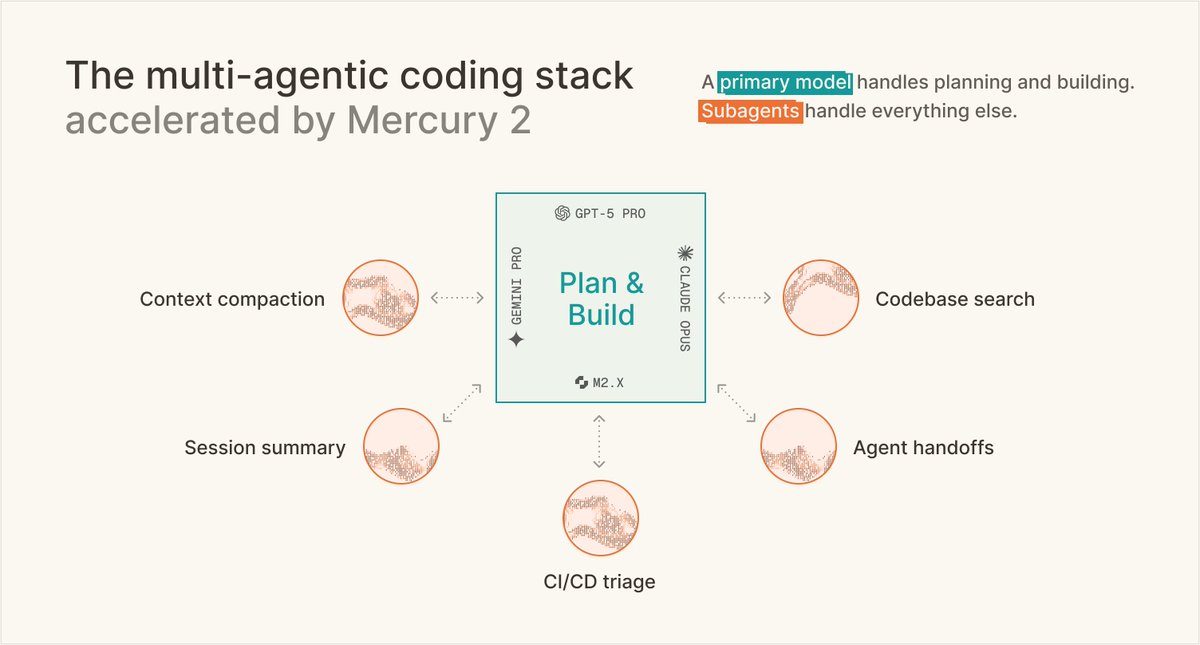
The best AI agents in production aren't one model. They're 5-10 specialized subagents running in parallel, each matched to the right task/cost/speed tradeoff. @augmentcode's architecture is one of the cleanest examples of this shift. We wrote up how they do it.
@augmentcode rebuilt their context compaction layer around Mercury 2. 82% latency cut. 90% cost cut. Comparable quality to Opus 4.7. Running in production today.
"We took a counter-intuitive bet. We decoupled summarization entirely, offloading it to Mercury 2 as a dedicated subagent. Mercury 2 is the highly efficient engine powering our most critical workflows."
-@RustagiAnkur & @jm1234567890, Members of Technical Staff at Augment Code
The subagent layer needs the most efficient model. Full methodology and eval setup in the writeup.
https://t.co/LPVTdaMjli