Las relaciones Interhumanas deben llevarse bajo el mutualismo, lamentablemente, no podemos sobrellevar relaciones parásitas que nos consuman nuestras energías.
TL;DR: Iceberg’s value is sociological, not technical. And if you care about lightweight, single-process engines like datafusion and duckdb, it’s probably your best shot at first-class lakehouse support with Wide interoperability.
#apacheiceberg#lakehouse
https://t.co/Q8dyukv2GO
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
If your CI/CD pipeline pulls dependencies and builds a new image on every run, you may be wasting time and money.
Rebuild the image only when the app code, Dockerfile, or dependencies change.
CI/CD should be fast
Most data engineers are modeling their data wrong in the age of AI.
We tend to think of data in terms of Kimball data modeling:
- Facts (events)
- Dimensions (nouns)
The problem with this type of data modeling for AI is:
- Fact data is still way too large for the context windows of AI
- Text-to-SQL still hallucinates, and we shouldn't rely on it
- Dimensional data can be complex to handle, especially slowly-changing dimensions
Data engineers thought they solved the problem with One Big Table (OBT) data modeling.
OBT does solve some major problems for AI models like:
- Handling dimensions easily
- Eliminating the need for error-prone text-to-SQL models
OBT introduces a different set of problems. The biggest being, too much context for the AI model to handle.
So what does the future look like?
Derivatives and aggregations from OBT!
Question-specific models, so the AI needs to map to a well-named dataset like "customer_churn_last_28days."
This way, depending on the problem at hand, AI will be able to select the right data set with the Goldilocks amount of context it needs to solve its problem!
I wrote more deeply about this exact problem in my latest newsletter!
Buena introducción en el cap 1. Puntos a rescatar:
1-Comparativa ML vs https://t.co/UaFSJ3dGAZ .
2-Ciclo de ML y la importancia de entendimiento del negocio y caso de usos.
3-Donde entra el rol del arquitecto de Machine Learning
Que hermosa y util es el algebra lineal y los subespacios vectoriales tan injustamente odiados por los estudiantes
Explicado simple, uno de los cuellos de botella de los LLMs es la memoria necesaria para almacenar en cache el resultado de varios productos de matrices, por eso no podemos correr grandes LLMs en un solo GPU casero, no le alcanza la vRAM
Hay metodos de "quantizado" que comprimen (redondean) los pesos originales del LLM, justamente para que ocupen menos vRAM o memoria, pero terminan reduciendo la calidad del output
TutboQuant plantea un esquema en 4 pasos sin tocar los pesos originales del LLM, o sea sin perder precision
Paso 1, luego de calcular los K.V que es la primera multiplicaicon de matrices q hacen los LLMs, hacen una rotacion ortogonal (cambio de base), manteniendo el producto interno
Paso 2, ahi si comprimen reduciendo de 16bit hasta 2 o 3bit
Paso 3, durante la atencion Q.K, que es el segundo paso de multiplicacion de matrices que hacen los LLMs, se usan estas versiones comprimidas ahorrando muchisima vRAM
Paso 4, reconstruyen el sesgo del resultado del paso 3, usando un corrector que solo ocupa 1bit
Reduce mucho necesidad de vRAM, no reduce cómputo base, incluso agrega un peuqeño overhead, pero puede mejorar mucho la velocidad si estabas limitado por la RAM porq permite compresiones mucho mas agresivas (2bit) sin perder precision
O sea, podrian correrse los modelos chinos top TIER en "solo" 128 gb de RAM al tope de su calidad
Kubernetes is beautiful.
Every Concept Has a Story, you just don't know it yet.
In k8s, you run your app as a pod. It runs your container. Then it crashes, and nobody restarts it. It is just gone.
So you use a Deployment. One pod dies and another comes back. You want 3 running, it keeps 3 running.
Every pod gets a new IP when it restarts. Another service needs to talk to your app but the IPs keep changing. You cannot hardcode them at scale.
So you use a Service. One stable IP that always finds your pods using labels, not IPs. Pods die and come back. The Service does not care.
But now you have 10 services and 10 load balancers. Your cloud bill does not care that 6 of them handle almost no traffic.
So you use Ingress. One load balancer, all services behind it, smart routing. But Ingress is just rules and nobody executes them.
So you add an Ingress Controller. Nginx, Traefik, AWS Load Balancer Controller. Now the rules actually work.
Your app needs config so you hardcode it inside the container. Wrong database in staging. Wrong API key in production. You rebuild the image every time config changes.
So you use a ConfigMap. Config lives outside the container and gets injected at runtime. Same image runs in dev, staging and production with different configs.
But your database password is now sitting in a ConfigMap unencrypted. Anyone with basic kubectl access can read it. That is not a mistake. That is a security incident.
So you use a Secret. Sensitive data stored separately with its own access controls. Your image never sees it.
Some days 100 users, some days 10,000. You manually scale to 8 pods during the spike and watch them sit idle all night. You cannot babysit your cluster forever.
So you use HPA. CPU crosses 70 percent and pods are added automatically. Traffic drops and they scale back down. You are not woken up at 2am anymore.
But now your nodes are full and new pods sit in Pending state. HPA did its job. Your cluster had nowhere to put the pods.
So you use Karpenter. Pods stuck in Pending and a new node appears automatically. Load drops and the node is removed. You only pay for what you actually use.
One pod starts consuming 4GB of memory and nobody told Kubernetes it was not supposed to. It starves every other pod on that node and a cascade begins. One rogue pod with no limits takes down everything around it.
So you use Resource Requests and Limits. Requests tell Kubernetes the minimum your pod needs to be scheduled. Limits make sure no pod can steal from everything around it. Your cluster runs predictably.
3 years in MLOps and the biggest lesson: the model is the easiest part
data pipelines, monitoring, feature stores, retraining schedules, infra costs
shipping and maintaining an ML system at scale is 80% engineering, 20% ML
the papers don't tell you this
Big features in FastAPI 0.134.0 ✨
🌊 Stream JSON Lines with yield: https://t.co/99tra1kqSf
🦀 @pydantic serializes each item to JSON (on Rust) for max perf
📦️Stream binary data with yield: https://t.co/fuCzrly0dQ
🤖 Library Agent Skill updated with this
🥚 Easter egg
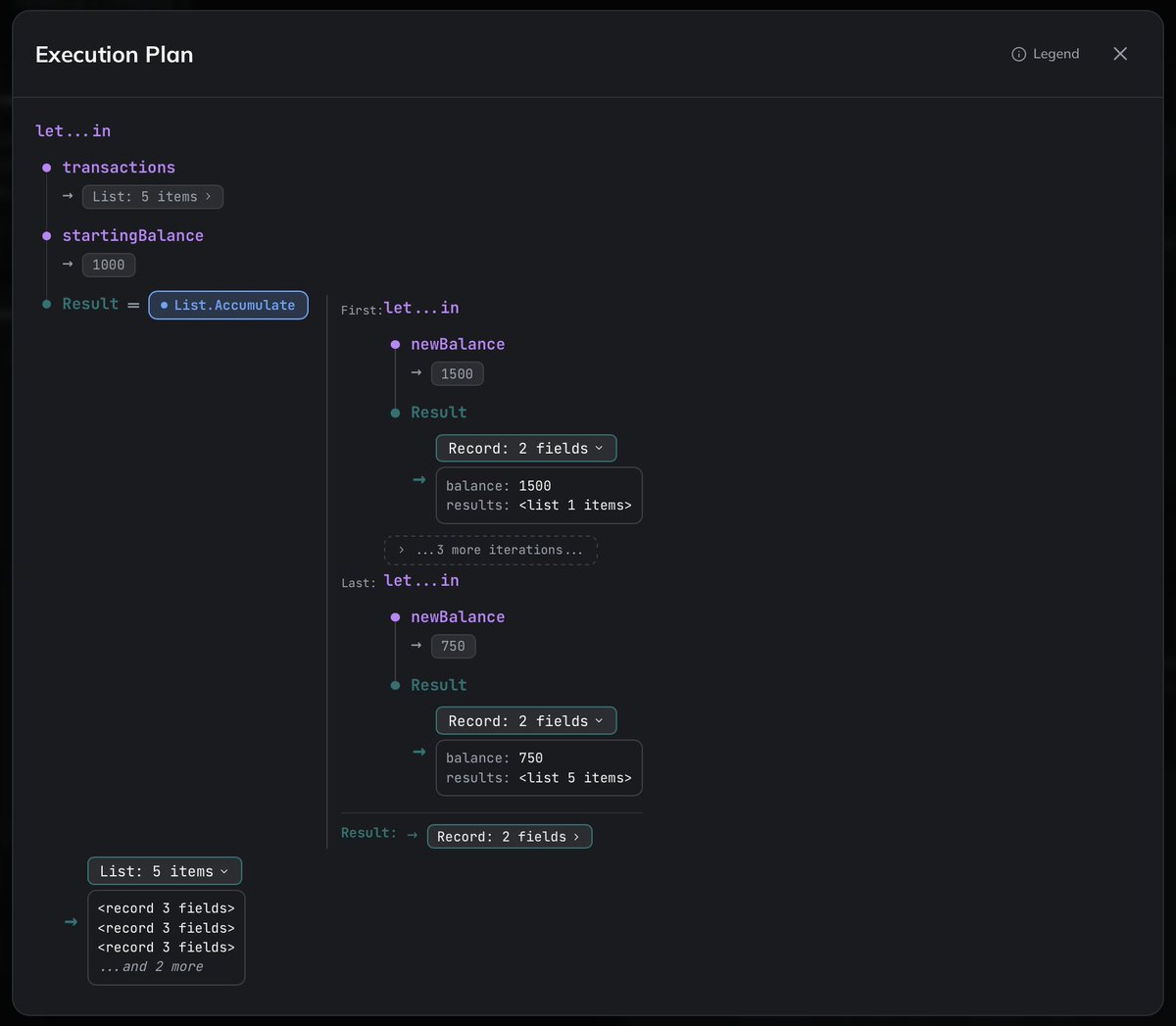
Sometimes you just need to see what your M (Power Query) code is actually doing — and that’s not always obvious.
I added an Execution Plan to M-Game: run your code, open the plan, inspect the flow + intermediate results ✅
https://t.co/I0askMggju
#PowerQuery#MLanguage#PowerBI
Researchers built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
And it hit 98.7% accuracy on a financial benchmark (SOTA).
Here's the core problem with RAG that this new approach solves:
Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity.
But similarity ≠ relevance.
When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar.
But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query.
Traditional RAG would likely never find it.
PageIndex (open-source) solves this.
Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents.
Then it uses reasoning to traverse that tree.
For instance, the model doesn't ask: "What text looks similar to this query?"
Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?"
That's a fundamentally different approach with:
- No arbitrary chunking that breaks context.
- No vector DB infrastructure to maintain.
- Traceable retrieval to see exactly why it chose a specific section.
- The ability to see in-document references ("see Table 5.3") the way a human would.
But here's the deeper issue that it solves.
Vector search treats every query as independent.
But documents have structure and logic, like sections that reference other sections and context that builds across pages.
PageIndex respects that structure instead of flattening it into embeddings.
Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications.
But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines.
For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis.
Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself.
I have shared the GitHub repo in the replies!
Dentro de lo que me quedo hasta ahora del capítulo 1 : la diferencia de los grandes modelos autorregresivos y los enmascarados, como unos predicen el siguiente token y el otro completa o rellena basado el contexto. (Hay más pero solo 1 post por cap)