Imagina vc ter acesso a algo tão maneiro quanto o alerta de defesa civil
E a piadoca q você faz é um termo incel energy fuleco
E não simplesmente
"ATAQUE NUCLEAR IMINENTE, busque abrigo ou proteção. Payload esperado: 10 megatrons. Tempo de resposta: 30 a 45 minutos"
"Tauri usa 60x menos RAM que Electron" não é verdade.
524MB→8MB? Isso é tamanho do binário, não RAM em runtime. O renderer do conteúdo domina a memória nos dois casos.
Medido: Discord no Pake = 484MB, não 8MB.
Economia real: ~1,5-2x, não 60x.
abre o monitor de recursos agora. olha quanta RAM o slack, o discord e o notion estao comendo parados
cada um desses "apps" é um navegador chrome inteiro empacotado. electron. você tem o mesmo motor de 200MB rodando 3, 4 vezes ao mesmo tempo
dá pra fazer diferente. tauri (rust) usa o webview que JÁ vem no seu sistema, em vez de embarcar um chrome novo. o mesmo slack empacotado assim sai de 524 MB pra 8 MB
webview nativo renderiza diferente em cada SO, então pra app complexo dá dor de cabeça.
não tem desculpa pra electron em 2026
GLM 5.2 is absolutely convinced that it is actually Claude, from Anthropic. When I tell it that it's GLM 5.2, it refuses to believe me, but is willing to check the local agent config to see what model is running.
The realization:
Isso é surreal
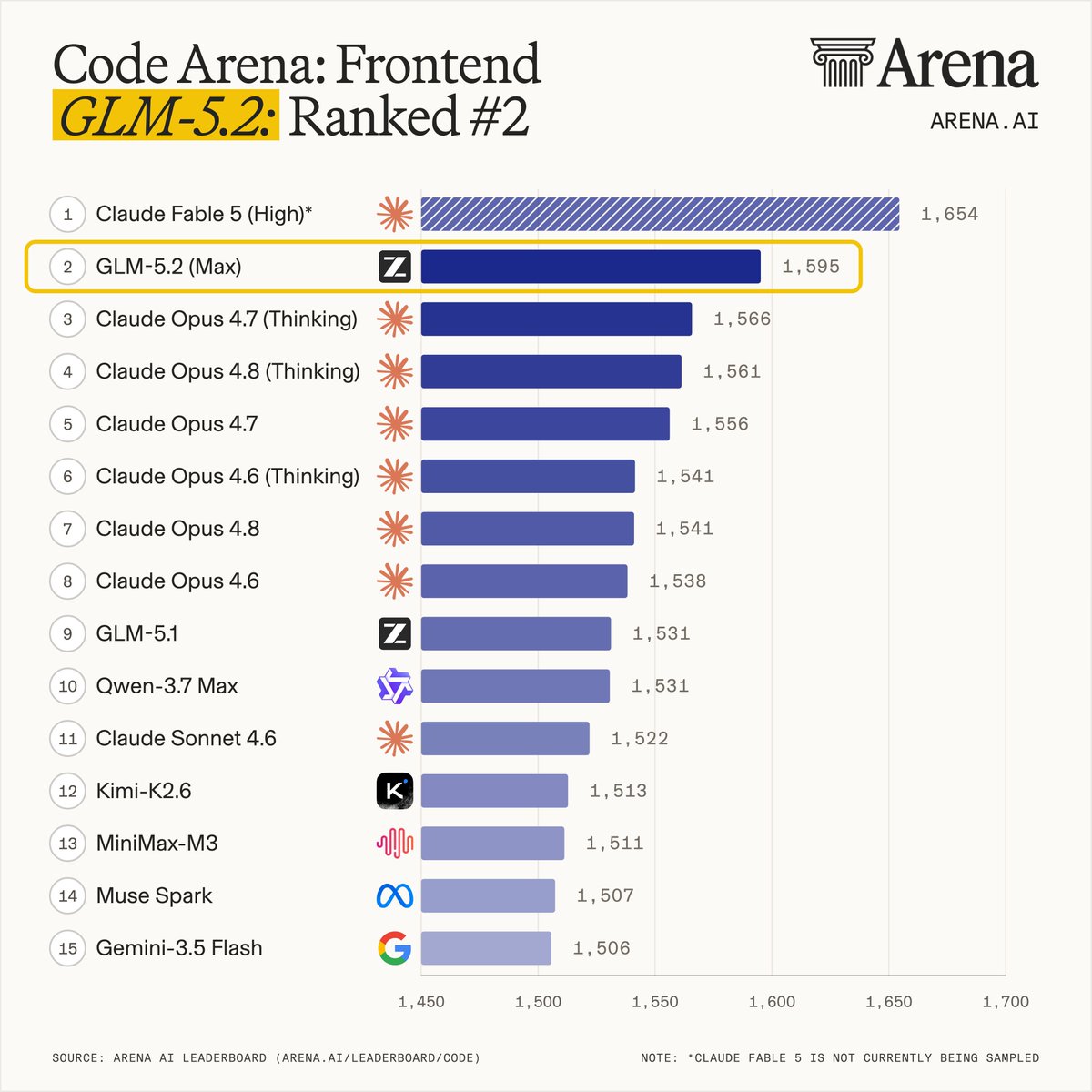
Um modelo chinês de código aberto agora é a melhor IA pra programação front end, já que o Fable não está mais disponível.
Open source alcançou modelos fechados, a China alcançou os EUA.