Ton serveur Linux ne sait pas que tu es en congé.
Et c'est précisément le problème.
Tu as parfaitement le droit de partir. Tu peux laisser ton ordinateur à la maison et profiter de tes vacances. Mais ton départ ne change rien à ce qui se passe autour de tes serveurs. La seule chose qui disparaît, c'est ta disponibilité.
Après 25 ans sur Debian, j'ai appris une chose : les événements importants choisissent rarement un moment pratique. Ils arrivent quand ils arrivent. La vraie question n'est pas de savoir si tu es disponible, mais ce qui se passe quand tu ne l'es pas.
Beaucoup de responsables regardent la stabilité de leurs serveurs pour décider s'ils peuvent partir. Pourtant, ce n'est pas la stabilité qui est testée pendant les vacances. C'est la dépendance de l'infrastructure à leur présence.
Le risque, lui, ne part pas avec toi. Les sites continuent de recevoir du trafic. Les attaques continuent. Les certificats expirent. Les fournisseurs ont des incidents. Si la seule chose qui disparaît est ta capacité d'intervention, c'est elle qui détermine le niveau réel de risque.
L'objectif n'est donc pas d'être joignable. Les infrastructures les plus sereines ne reposent pas sur la réactivité de leur responsable. Elles sont organisées pour que les tâches critiques restent surveillées, traitées et suivies, même en son absence.
Fais le test : quinze jours sans ordinateur, sans VPN, sans accès à tes outils habituels. Qu'est-ce qui continuerait à fonctionner exactement comme aujourd'hui ?
Les vacances ne créent pas la dépendance. Elles la révèlent. Tant que ton absence augmente le niveau de risque, chaque nouveau site, chaque nouveau client et chaque nouveau serveur renforcent une responsabilité qui repose encore principalement sur toi.
La stack SYSMASTER existe pour une raison : retirer le serveur de ta liste de préoccupations. Garder le contrôle sans rester le point de défaillance.
Télécharge l'ebook : https://t.co/6vnU8a4cdm
#Linux #SysAdmin #Debian
La semaine dernière j'ai mis à jour pfSense de 2.7.2 à 2.8.1. C'est mon proxy et mon VPN pour accéder de façon sécurisée à l'administration des serveurs que je gère.
Le changement majeur de cette version : le passage de FreeBSD 14 à FreeBSD 15. Deux ans de développement FreeBSD intégrés d'un coup. Correctifs noyau, gains de performance, et PHP qui passe de 8.2 à 8.3.
Côté VPN et accès distant : OpenVPN pousse maintenant la config par client directement depuis la GUI, et l'accélération crypto passe automatiquement par OpenSSL. IPsec, avec strongSwan mis à jour, corrige le ralentissement des règles firewall quand beaucoup de tunnels sont actifs. OpenSSH suit FreeBSD 15 avec la correction d'une faille de divulgation de clé via la console SSH. Les algorithmes obsolètes restent supprimés : 3DES, Blowfish, CAST128, MD5-HMAC.
Côté serveur DHCP avec Kea : haute disponibilité DHCPv4 et DHCPv6 en hot standby, baux synchronisés et chiffrés. Enregistrement DNS automatique des hôtes dans Unbound, configurable par interface. Délégation de préfixe DHCPv6 et configuration JSON personnalisée pour les options non couvertes par la GUI.
Côté sécurité : la politique d'état par défaut passe de Floating à Interface Bound. La récupération de passerelle purge automatiquement les états sur les passerelles de secours quand la principale revient. Et NAT64 est désormais pleinement supporté, des clients IPv6 only vers des hôtes IPv4, intégré au firewall, aux annonces routeur et au DNS Resolver.
Ce n'est pas une mise à jour anodine. Le saut FreeBSD 14 vers 15 impose de désinstaller tous les paquets tiers avant de lancer l'upgrade, puis de les réinstaller après. Le bootloader doit être mis à jour pour supporter le nouveau noyau, surtout avec ZFS.
Ce type d'opération ne se voit jamais. Jusqu'au jour où elle n'a pas été faite.
pfSense fait partie de la stack SYSMASTER. C'est par là que passe chaque connexion d'administration aux serveurs. Le détail de la stack complète est ici :
https://t.co/6vnU8a4cdm
Gérer ses emails avec un boulet au pied
Tu peux quitter ton hébergeur web en une journée. Pas tes emails.
Un site web se déménage avec un dump SQL et un rsync. Une boîte mail, c'est autre chose. Les comptes, les filtres, les anciens messages, les enregistrements DNS, la configuration anti-spam : tout est interconnecté et lent à transférer.
L'antispam analyse chaque email entrant en profondeur (contenu, headers, réputation, scoring bayésien). C'est un traitement gourmand qui s'accumule sur le serveur.
La gestion du spam est devenue une discipline à part entière : configurer SPF, DKIM, DMARC, surveiller la réputation IP, maintenir un antispam à jour, gérer les bounces et les plaintes qui remontent automatiquement.
Le jour où tu veux changer d'hébergeur, le déménagement est techniquement possible mais lourd. Il faut transférer les historiques par avance, reconfigurer les clients Outlook ou Apple Mail des utilisateurs, coordonner les bascules DNS, et accompagner chaque personne pas à pas. C'est un projet long et dépendant de l'implication de chacun, qu'on évite de relancer.
Le mail est probablement la seule décision technique pénible à défaire.
C'est pour ça que l'infogérance Linux SYSMASTER se concentre sur le web hosting et laisse le mail à des services spécialisés (Google Workspace, Microsoft 365, ProtonMail Pro pour la messagerie ; SendGrid, Brevo pour le transactionnel). Le détail de la stack ici : https://t.co/6vnU8a3EnO
#Mail #Email #Antispam #Infogérance #Linux #Debian #FreelanceTech #AgenceWeb #Hébergement
VPS, Public Cloud ou dédié ?
Un choix sur trois cache un piège qu'on te vend rarement.
Si tu héberges un site web, le choix par défaut est souvent un VPS.
Ce n'est pas toujours le bon.
Entre VPS, Public Cloud et serveur dédié, les différences vont au-delà du prix d'entrée. Le critère le plus regardé reste le SLA.
Un SLA est une garantie contractuelle, pas technique. Si le fournisseur ne tient pas le pourcentage annoncé, il rembourse partiellement. Ça ne veut pas dire que la machine ne tombera jamais.
Le VPS chez OVH a un SLA de 99,95 % et tourne sur du matériel mutualisé. Adapté à une petite app peu critique, avec un budget serré.
Le Public Cloud OVH a un SLA de 99,99 %, ressources garanties par instance, pas de voisinage gênant. C'est le défaut moderne pour un site qui doit tenir.
Le dédié ADVANCE reste à 99,95 %. Il devient pertinent quand tu veux poser ton propre hyperviseur (Proxmox), ou quand tu as besoin de gros volumes en continu et tu acceptes le SLA inférieur pour économiser.
Le dédié haut de gamme atteint 99,99 % mais à un prix qui rejoint celui du Public Cloud.
Le réflexe « petit site égale VPS » n'est plus systématiquement le bon. La vraie question est : quel niveau de garantie contractuelle tu veux pouvoir tenir, et avec quel socle technique en dessous.
L'infogérance Linux SYSMASTER part du choix de la machine adapté au SLA visé et pilote la stack technique Debian derrière. Le détail est ici : https://t.co/6vnU8a4cdm
#VPS #PublicCloud #ServeurDédié #SLA #Infogérance #Linux #Debian #FreelanceTech #AgenceWeb
La sauvegarde de tes sites internet sent le brûlé ! 🔥
Une sauvegarde sur la même machine que ta prod n'est pas une sauvegarde. C'est une copie qui tombe avec.
Le jour où ton disque crame, où le datacenter rencontre un incident, ou bien quand un ransomware chiffre ton système, tu perds les deux en même temps.
La vraie question n'est pas « est-ce que tu fais des sauvegardes », mais « où sont-elles physiquement ».
Sur le même VPS ou dans le même datacenter, le risque est corrélé. Si l'origine de l'incident touche l'infrastructure, ta sauvegarde aussi.
Une sauvegarde sérieuse vit ailleurs : un autre fournisseur, une autre zone géographique.
Inutile de venir pleurer ensuite ou te dire que tu ne savais pas.
Pour en savoir plus sur la stack SYSMASTER :
https://t.co/6vnU8a3EnO
#Sauvegarde #Backup #Ransomware #Infogérance #Linux #Debian #FreelanceTech #AgenceWeb
Votre serveur Linux affiche *** System restart required *** depuis 93 jours, et personne ne l'a lu.
Ce message apparaît sur Debian et Ubuntu dès qu'une mise à jour touche le noyau ou une bibliothèque critique. Il reste là, en attente d'un redémarrage.
Pendant ce temps, les mises à jour sont installées sur le disque mais pas actives. Le système continue d'exécuter les anciennes versions chargées en mémoire. Le noyau vulnérable corrigé dans la mise à jour tourne toujours, sous sa forme exploitable.
Une croyance circule : un serveur qui tourne longtemps égale bonne administration. C'est l'inverse. Un long fonctionnement sans redémarrage signifie qu'aucune mise à jour critique n'a pris effet pendant tout ce temps.
Notre stack SYSMASTER surveille ce signal en continu. Par défaut, le redémarrage se fait automatiquement.
L'e-book SYSMASTER : Découvrez comment notre stack peut asseoir votre crédibilité.
https://t.co/8TyvKn1Fo1
Pour les entreprises qui veulent faire le point sur leur situation : https://t.co/DCycP0ZhRt
#SystemRestartRequired #RebootLinux #KernelUpdate #MAJLinux #SécuritéLinux #Infogérance #Debian #MaintenanceServeur #VPS #LinuxServer
Ubuntu 20.04 est sorti du support standard il y a 13 mois. Beaucoup de serveurs déployés à cette époque tournent encore dessus, sans correctif depuis.
Comment ces machines finissent oubliées ? Quelques scénarios reviennent souvent.
Un site client posé il y a quelques années, plus rouvert depuis.
Un développeur qui a installé puis quitté l'équipe sans transmission propre.
Un VPS chez un hébergeur "managé" avec panel, où on paie le confort de gestion. La maintenance du système reste à la charge du client.
La sortie de secours commerciale proposée par Canonical s'appelle Ubuntu Pro. Elle place la sécurité long terme de vos serveurs sous la dépendance commerciale d'une seule entreprise.
Sous la question de la version d'Ubuntu, un autre problème pèse plus lourd : l'absence d'un plan de migration anticipé.
Notre stack SYSMASTER est bâtie sur Debian pour son indépendance vis-à-vis d'une entreprise unique et sa politique de mises à jour conservatrice. Chaque migration est planifiée à l'avance.
📘 L'e-book SYSMASTER : Découvrez comment notre stack peut asseoir votre crédibilité : https://t.co/8TyvKn1Fo1
Pour les entreprises qui veulent faire le point sur leur situation : https://t.co/17Azy99yBr
#ubuntu #upgrade #infogérance
Votre site WordPress se BLOOOOOOOQUE lors d'un événement important ?
J'aborde les techniques que j'utilise pour optimiser le chargement et tester les performances.
#wordpress#optimisation#performance#lenteur#rapide
━━━━━━━━━━
👉 Télécharge mon E-book "Comment ne plus craindre les risques de pannes et intrusions de vos serveurs Linux avec notre stack SYSMASTER ?" : https://t.co/6FKo9XxwA9
📞 Réserve un RDV pour m'expliquer ton besoin : https://t.co/FkC7RurIH0
Quel danger représente une extension WordPress désactivée ?
#wordpress#intrusion#sécurité#plugin#piratage#hacker#sécurisé
━━━━━━━━━━
👉 Télécharge mon E-book "Comment ne plus craindre pannes et intrusions de vos serveurs Linux avec le SYSMASTER ?" : https://t.co/6FKo9Xy4pH
📞 Réserve un RDV pour m'expliquer ton besoin : https://t.co/FkC7Rusgwy
Deux failles de sécurité MAJEURES sur vos hébergements web
#infogérance#debian#linux#hébergementweb#sécurisation#faillesdesécurité
━━━━━━━━━━
👉 Télécharge mon E-book "Comment ne plus craindre pannes et intrusions de vos serveurs Linux avec le SYSMASTER ?" : https://t.co/6FKo9XxwA9
📞 Réserve un RDV pour m'expliquer ton besoin : https://t.co/FkC7RurIH0
@gxlmo@olesovhcom C'est parce qu'ils sont visionnaires. IPv6 est abandonné et IPv8 (plus simple) va remplacer IPv6 et IPv4. Pour l'instant c'est à l'état de draft.
@_adriend_ On voit que chaque processus plakar consomme une mémoire RES de plus de 4Go.
Et la machine a 32G, alors sur les 11 lignes qu'on voit, on est déjà à 44 Go de RAM sur 32.
Le système swap pour tout faire rentrer.
Au delà de 6 ou 7 plakar, le système ne peut pas fontionner.
Un disque serveur plein en moins de 24h ?
(Alors que le disque semble largement suffisant)
Mais un problème de configuration MariaDB ignoré depuis des mois.
Les fichiers mysql-bin s'accumulent sans produire d'alertes jusqu'à ce que le monitoring le voit lorsqu'il reste 5% ou 10% d'espace disque.
Pas de ralentissement visible, jusqu'au crash.
Ce que j'ai trouvé en creusant :
→ expire_logs_days configuré à 3 jours, mais la purge automatique ne se déclenchait plus
→ Beaucoup de fichiers mysql-bin.* accumulés depuis septembre
→ La purge manuelle bloquée sur une erreur 1375 sans explication claire
→ Une incohérence entre l'index interne de MariaDB et les fichiers physiques sur disque
La résolution a nécessité une purge manuelle des fichiers et une reconstruction complète de l'index.
Ce type de problème peut arriver sur n'importe quel serveur MariaDB après une interruption brutale passée (crash, coupure électrique, SIGKILL). La configuration semble correcte. Les logs ne montrent rien d'alarmant. Et le disque se remplit quand même.
J'ai documenté le diagnostic complet et la procédure de résolution dans un article ici : https://t.co/zTiNlWJAi6
Si vous gérez des serveurs MariaDB en production, ça vaut la lecture.
@Elkha_D Heureusement je n'ai ni Docker (sauf exception), ni Windows.
Cliquer sans comprendre comment gérer en production, c'est une perte de temps, en plus de ne rien maîtriser.
Pourquoi supposer qu'un stagiaire est mauvais le premier jour ?
Pour ma part, j'étais opérationnel dès le premier jour et bien meilleur que les soi-disant "senior" qui étaient devenus mauvais avec le temps et dépassés.
Et aujourd'hui, je ne mettrais jamais un agent IA directement sur mes serveurs Debian tant que je n'aurai pas accès ni au source du code, ni au source du raisonnement en totalité avec une confiance sans faille.
L'IA est utile pour m'assister et non l'inverse.
#debian #ia #infogérance
Tes serveurs sont toujours en Debian 11 (ou pire) ? Tu n'as pas l'impression d'être rester coincé dans une boucle temporelle ?
Personne ne t'a fêté la nouvelle année...
Personne ne t'a invité aux anniversaires Debian.
Ton noyau est périmé, moisi...
Au fait, tu sais qu'on s'est débarrassé de python 2 ?
Le mieux, c'est de toucher à rien parce que ça fonctionne ? Et que tu n'oses le faire évoluer car tu n'as pas le temps mais tu sais que tôt ou tard, arrivera ce qui arrivera.
C'est tellement mieux de ne pas se sentir seul face aux évolutions.
Dis-moi ce qui te retiens de migrer ?
#debian11 #migration
https://t.co/u6TGx9FZ0D
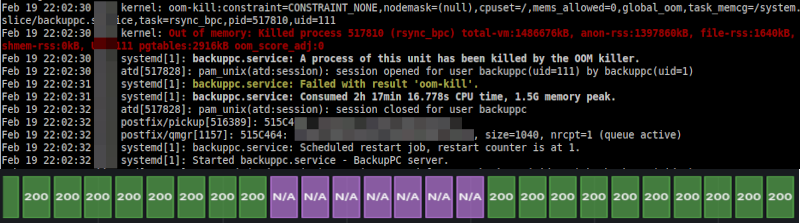
Petit coup de chaud pour #BackupPC au moment de la sauvegarde de deux serveurs Dolibarr le 19 février.
Il a voulu consommer trop de mémoire.
Ce n’est pas la première fois que le processus rsync_bpc se fait tuer.
Il a pourtant largement assez de mémoire.
systemd (je sais que certains ne l’aiment pas) l’a relancé dans la foulée.
Et de toute façon, Puppet l’aurait relancé dans les 30 minutes grand maximum.
Entre temps, j’ai reçu une alerte par mail de Prometheus qui m’a signalé avoir perdu de vue BackupPC (en violet sur la photo).
Et quand BackupPC s’est relancé, j’ai reçu ses alertes de sauvegarde échouée.
La sauvegarde s’est relancée d’elle-même l’heure suivante.
Ce qui est intéressant est que le système a pu se réparer de lui-même (en quelque sorte) sans aucune intervention de ma part…